SynthViz: Enhancing Interpretative Summarization and Visualization Techniques
> Team Members
Dr Jonathan Albright (Project Facilitator)
Piyush Aggarwal
Dr Jan Babnik
Anna Cattaneo
Haohan (Lily) Hu
Lingyu Li
Mengdi Zhu
> Contents
Introduction
Data and Steps
Research Questions
Methodology
Findings
Discussion
Conclusion
References
> Summary of Key Findings
Our exploratory study applies what we label as synthetic visual methods (SVM). By visualizing the official CNN text transcripts from the Trump-Biden 2024 presidential debate, we show that generative models such as Stable Diffusion (SD) 2 and 3-medium visually condense the predominant discursive traits of the transcript segments. Synthetic visualization techniques, therefore, mimic and reflect the discursive. In this project, we show that the deliberation is visualized in conspicuous media formats, which transfers specific aesthetic values from textual corpora to visual media including to specific media genres, color palettes, gradients, and colorations, and visualized objects, with imagined publics (e.g., crowds, spectators, protestors) as well as identifiable imagined figures (e.g., political collaborators, opponents, visual composites/hybrids). In summary, SVM creates a composite meta-media visual layer that allows digital research to capture the predominant tone as well as the sentiment of the discursive. We term the collective result of this methodological technique a 'revisualization'.
1. Introduction
Our SynthViz: Enhancing Interpretative Summarization and Visualization Techniques project aims to integrate generative AI tools into digital methods to convey the wider ‘visual culture’ of data inquiries using synthetic approaches. By using topical text prompts to generate corresponding visuals through Stable Diffusion models, and then running these images through computer vision models and color and feature extraction tools, we create a form of data inquiry that reflects the aesthetic and communicative styles of generative models. This approach allows us to investigate how generative AI both mimics and extends the conventions, affordances, and styles that are prevalent on these platforms, and visually gauge how the synthetic interpretations are reflexively shaped by broader media debates and cultural landscapes.
The rise of conversational AI chat interfaces and generative AI tools necessitates a profound reconfiguration of the debate around the study of communicative practices and cultural production. Emerging AI-powered tools capable of remarkably nuanced language and content generation introduce a range of new research possibilities into the process of communication research. This paper situates the study of communicative AI systems as 'platform-based mediums' in their own right, subtly building on the foundation of Rogers' 'digital methods' (2013). We propose a revitalized approach for investigating conversational AI interfaces and generative AI tools, hereafter termed 'communicative AI'.
Our project highlights the unique communicative capacities and investigative agency of emerging AI tools, which sets the stage for a deeper theoretical exploration and methodological innovation in media and communication research that extends far beyond the scope of this project. As Feher (2024) notes, 'AI technology and media operation converge, leading to an extended AI mediatisation' (p. 2). Moreover, van der Wal et al. (2024) emphasize that 'the quality of bias measures is critical for understanding the scale of the problem and designing mitigation strategies.' (p. 2).
Connecting strategies to practice, Pink (2019) argues that 'social research is almost inevitably digital' as digital, social, and material dimensions of our lives are now inseparably entangled (p. 46). The methodological challenges of studying communicative AI are akin to those faced in post-API research (Perriam et al., 2020). Traditional research methods, which rely on fixed and stable outputs, are insufficient for capturing the dynamic and evolving nature of AI systems. Instead, researchers must adopt a medium-centric approach that embraces the fluidity of communicative AI interfaces.
Finally, we adopt Hilbert et al. (2019) in extending our exploratory project perspective by asserting that computational methods 'cataly[se] a new set of methods directly suited to tackling foundational research questions in communication' (p. 3913) This involves treating AI outputs as 'traces' in a dynamic process, allowing for a deeper understanding of the system's underlying logic, biases, and creative tendencies.
2. Data and Steps
Inputs: Text directly from CNN’s (United States) presidential debate transcripts (event was broadcast live on 28 June 2024 from 21:00 EDT).
Total words spoken (word count from transcripts):
- Biden: 5,201 words (61 statements made)
- Trump: 7,011 words (76 statements made)
Total speaking time (according to CNN):
- Biden: 35 minutes and 41 seconds
- Trump: 40 minutes and 12 seconds
Image mosaics showing synthetic visual outputs for Trump and Biden’s 2024 debate statements (see below for details)

Image 2 (above) : Mosaic of Trump's synthetically visualised 2024 debate transcripts. Arranged linear (left-to-right, moving down) from the first statement to their last statement. From the official CNN transcripts. Trump made 76 statements, Biden made 61: this is reflected in the relative size of the synthetic visual corpuses.

Image 2.1 (above) : Mosaic of Biden's synthetically visualised debate transcripts. Arranged linear (left-to-right, moving down) from the first statement to their last statement. From the official CNN transcripts. *Trump made 76 statements, Biden made 61: this is reflected in the relative size of the synthetic visual corpuses.
*Steps (shown in detail in Appendix)
-
Set up the Python environment, pre-processed textual data by adding timestamps (duration HH:MM:SS), and uploaded the input CSV file to the SynthViz app.
-
Selected model (CLIP encoder and Stable Diffusion 3-medium used for this project). Stored parameters and generated as a batch for each candidate into generated image folders; exported log .csv of input prompts and parameter settings for reproducibility (seed, guidance, iterations).
-
Generated the images from the transcript as discrete sets for each candidate.
-
Used Microsoft Florence-2-large to extract features from the generated images, caption the generated images; used colorthief to analyse image moods and extract rgb/hex color palettes; network graphs generated to visualize 2D input text-image similarity (not used for this project), analyzed and visualized input_text-to-caption alignments.
-
Compiled the data, exported, and stored the working project and image batch files.
-
Summarize the findings of similarity and alignment analysis.
-
Ran preliminary correlation analysis on colors/mood, caption sentiment, debate issues, and output formats.
3. Research Questions
-
How can synthetic visual methods (SVM) enhance existing digital research methods?
-
How do different discourses, platforms, aesthetic values, and topics affect the synthetic outputs on the thematic level?
-
Are certain aesthetics in the visualizations predominant across the generated visual corpus, and if so, are there observable differences?
-
[future] What are the best practices for integrating SVM as a critical tool into exploratory digital research frameworks?
4. Methodology
The project takes a strongly mixed-methods approach, combining an exploratory analysis of generated synthetic visual data followed by a sequence of computational qualitative and quantitative processing using SynthViz, an experimental Python-based pipeline (tool) built by the project facilitator and hosted on Google’s Colab for the project due to model GPU requirements. SynthViz can process, generate, and (re)combine the visual outputs of .csv files in Stable Diffusion 2, 2.1, XL, and 3.
For analysis of our outputs, including captions, Microsoft Florence-2-large was used. Additional analysis was achieved using models including RoBERTa (twitter-roberta-base-sentiment), MiniLM (all-MiniLM-L6-v2), and BART (facebook-Bart-Large-CNN) to extract and analyse different aspect of the synthetic visual corpus for each candidate. As this project was part of a week-long data sprint, we focus in this report on the visual outputs.
5. Findings
5.1 Trump 2024 Debate Statements - Poster Visualization
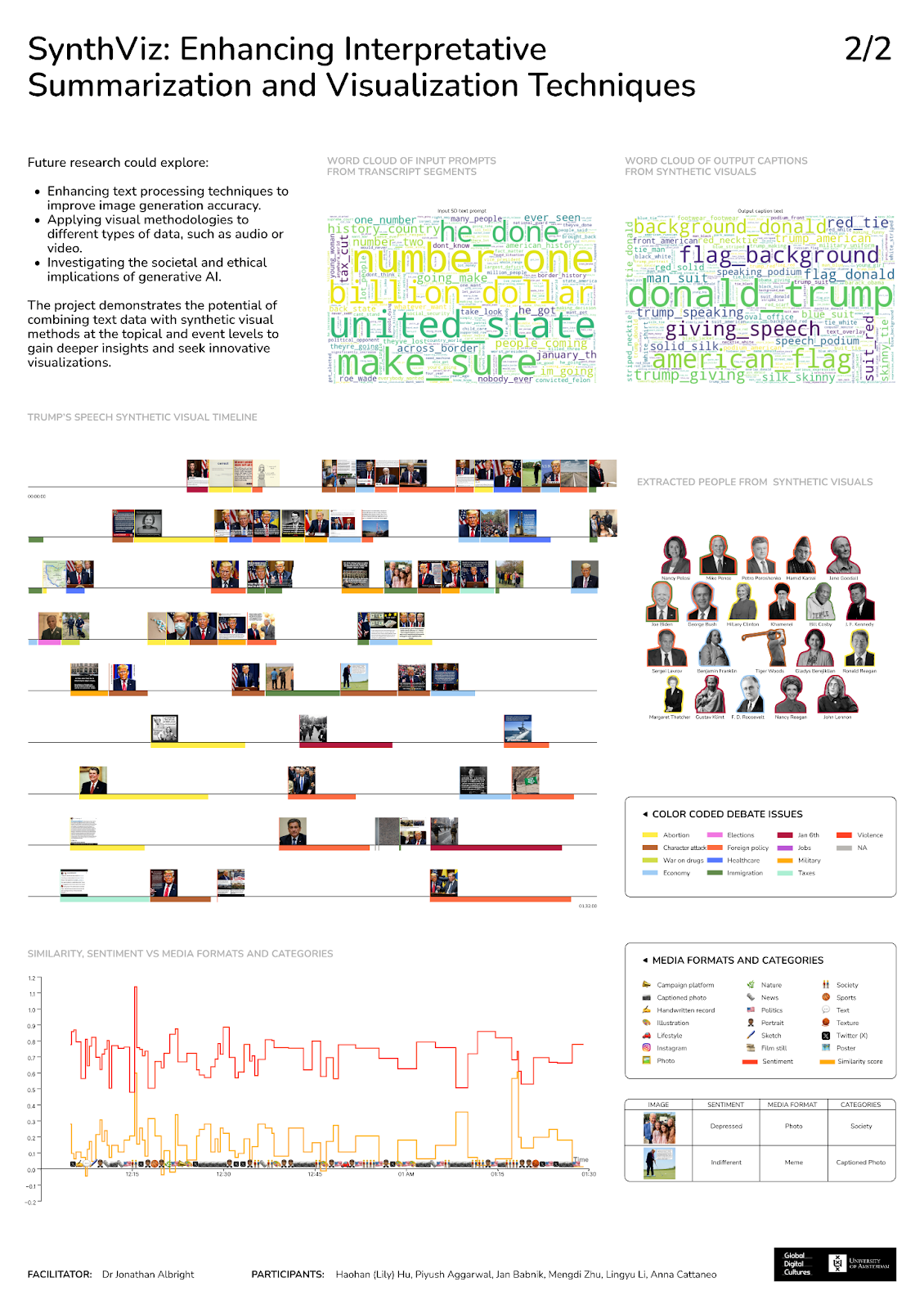
5.1.1 People extracted by Florence-2-large from Trump's SVM-visualized debate statements (see Image 5.1 above on the right side of poster for legend and the associated debate issues in which they appeared; most figures did not appear in transcript; Pelosi and Reagan are directly mentioned):Image 5.1: Top: Word clouds of text from transcript statements vs. Florence-2-large captioned image descriptions. Middle: A visualisation of Trump’s statements, color coded by issue, from the start to end of 2024 debate using a timestamp-enriched official transcript. Lower: sentiment score from Florence-2-large captions, plotted by media format (e.g, meme, photo, X/Twitter post, etc.) and media category (e.g., politics, sports, lifestyle)
 5.2 Biden 2024 Debate Statements - Poster Visualisation
5.2 Biden 2024 Debate Statements - Poster Visualisation
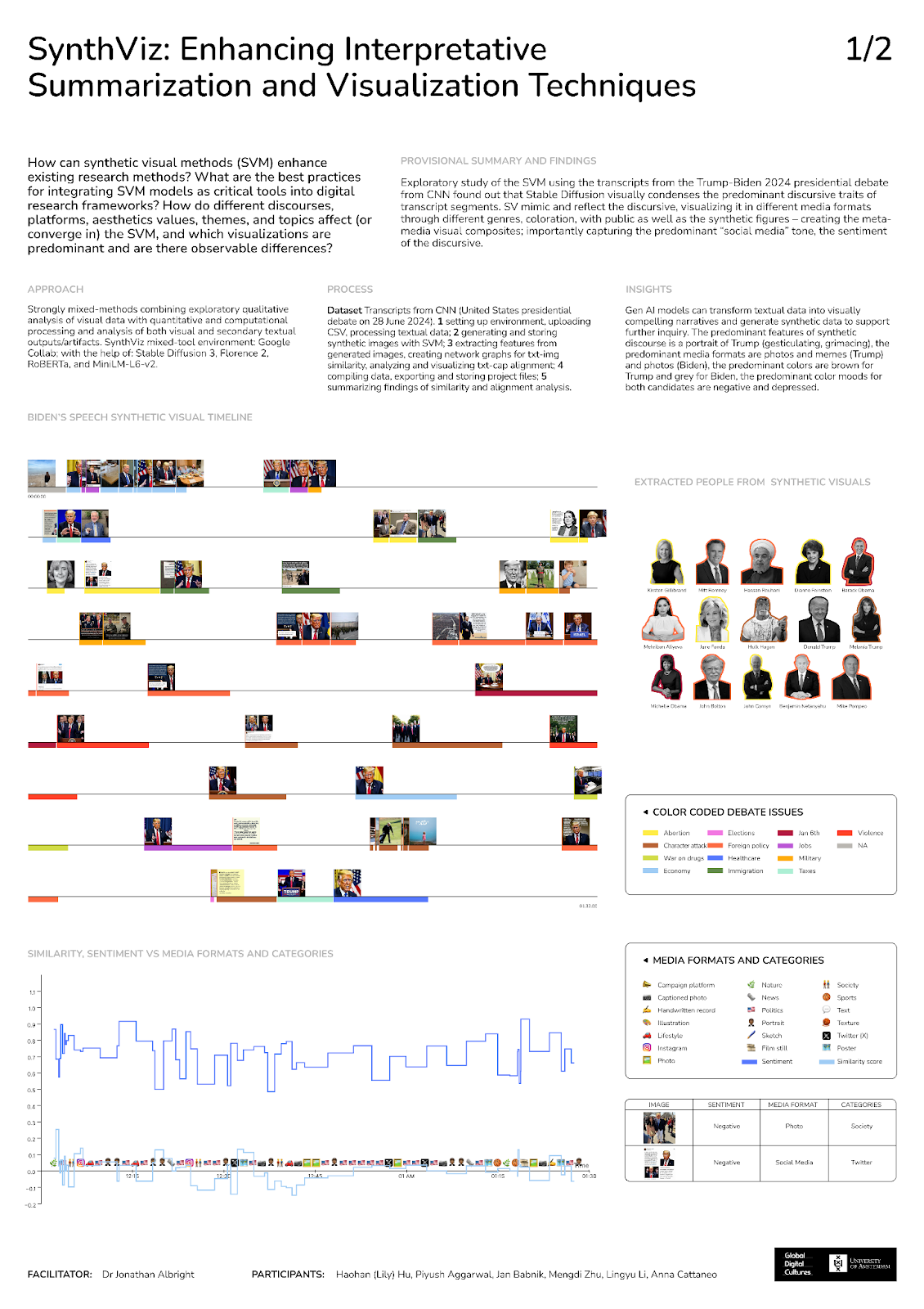
5.2.1 People extracted by Florence-2-large from Biden's SVM-visualized debate statements (see Image 5.2 above on the right side of poster for legend and the associated debate issues in which they appeared, most figures did not appear in transcript):Image 5.2:Middle: Visualisation of Biden’s statements, color coded by issue, from start to end of 2024 debate from timestamp-enriched official transcript. Lower: sentiment score from Florence-2 captions plotted by media format (e.g, news photo, illustration, X/Twitter, etc.) and media category (e.g., politics, sports, lifestyle)

5.3 Examples of Generated Images
+ Trump's Synthetic Visuals (selected examples):- Predominantly negative and intense, often depicting anger, frustration, and projecting power and determination.
- Frequent inclusion of protest scenes, military imagery, and platform-specific usage of social media.
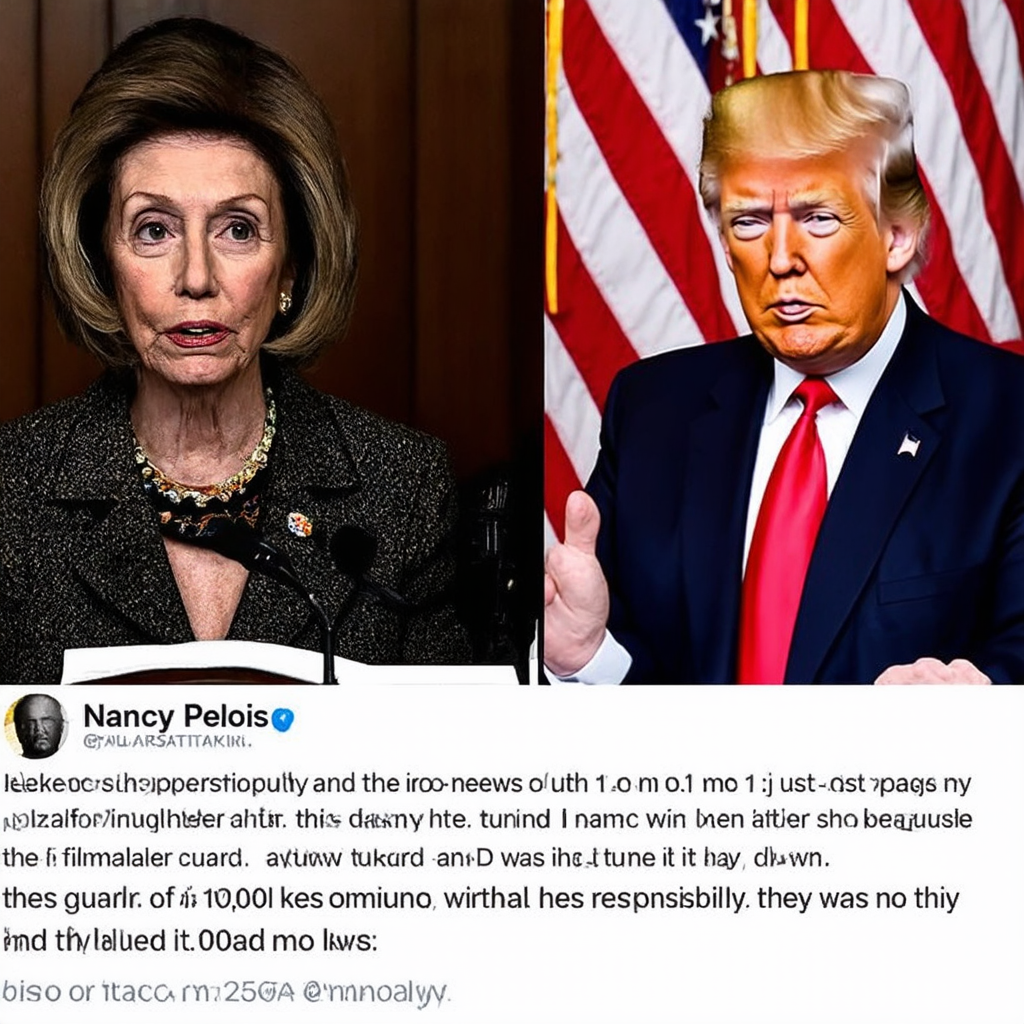
Image 5.3-1 [from Trump] : “Well, I didn’t say that to anybody. I said peacefully and patriotically. And Nancy Pelosi, if you just watch the news from two days ago, on tape to her daughter, who’s a documentary filmmaker, as they say, what she’s saying, oh, no, it’s my responsibility, I was responsible for this ....”

Image 5.3-2 [from Trump] : “And I will tell you … throughout the entire world, we’re no longer respected as a country. They don’t respect our leadership. They don’t respect the United States anymore. We’re like a Third World nation. Between weaponization of his election, trying to go after his political opponent, all of the things he’s done, we’ve become like a Third World nation. And it’s a shame the damage he’s done….”

Image 5.3-3 [from Trump] : “Because the tax cuts spurred the greatest economy that we’ve ever seen just prior to COVID, and even after COVID. It was so strong that we were able to get through COVID much better than just about any other country. But we spurred – that tax spurred.”

Image 5.3-4 *[from Trump]: “I offered 10,000 because I could see – I had virtually nothing to do. They asked me to go make a speech. I could see what was happening. Everybody was saying they’re going to be there on January 6th….”

+ Biden's Synthetic Visuals (selected examples):Image 5.3-5 [from Trump] : “And because of his ridiculous, insane and very stupid policies, people are coming in and they’re killing our citizens at a level that we’ve never seen. We call it migrant crime. I call it ‘Biden migrant crime’... And you’re reading it like these three incredible young girls over the last few days. One of them, I just spoke to the mother, and we just had the funeral for this girl, 12 years old.”
In our project findings, images of Trump dominate nearly all of Biden's debate statements in the outputs, with Biden appearing only once in a visualized Trump statement (see Image 5.3-5 above) across the entire set of combined outputs. Images of Biden do not appear in his corresponding statement visuals. Beyond this result, Biden's visual corpus is more somber and serious, with imagery depicting formal settings, forums, discussions, and public addresses. There is an reflective emphasis in the synthetic visual outputs of Biden’s attempt to focus debate discussion around healthcare/abortion and progressive social issues.

Image 5.4-1 [from Biden] : "It’s been a terrible thing what you’ve done. The fact is that the vast majority of constitutional scholars supported Roe when it was decided, supported Roe. And I was – that’s this idea that they were all against it is just ridiculous."

Image 5.4-2 *[from Biden]: “Let’s see what your numbers are when this election is over.”

Image 5.4-3 [from Biden]: “He had the largest national debt of any president four-year period, number one. Number two, he got $2 trillion tax cut, benefited the very wealthy. What I’m going to do is fix the taxes.”

Image 5.4-4 [from Biden] : "The only terrorist who has done anything crossing the border is one who came along and killed three in his administration, killed – an al-Qaida person in his administration killed three American soldiers, killed three American soldiers….”

Media Formats and Sentiment Correlation: The captioned photos and imagined 'memes' generated from Trump's debate statements tend to be highly issue-forward, while formal portraits and policy discussion output visuals of Trump present as more neutral and serious. Color palettes influence the visual perception, and Trump's synthetic output visuals have darker, more intense coloration, with bright red ties as a recurring centerpiece; Biden's visual outputs have a more muted, neutral, somber tone overall.Image 5.4-5 [from Biden] : “You are a child.”
Debate Topics Influence on Visual Sentiment
In our experiment, Biden's focus on healthcare and COVID-19 and his corresponding statements seemed to lead to the more somber visual outputs, while statement focusing on national security, terrorism, and the economy generated more intense and aggressive visuals overall for Trump.
Socio-Technical Context:
Recognizing Bias in Models: Transformer models reflect the collective emotional responses and cultural biases from their implementations, algorithms, and training data. The outputs shown thematically visualising the candidates' transcripts from the United States' 2024 presidential debates suggest a sort of 'feedback loop' where public perception and media representation become amplified through generative AI. The clear dominance of Trump in the visuals, even in neutrally-valenced (i.e., objective) statements, highlights the need for responsive, experimental critical reflection on emerging generative model biases. This project approaches this not from a 'proof of bias' perspective, but instead from an experimental critical data studies approach. We seek to understand how secondary methods such as as synthetic visual methods (SVM) to visualize thematic text-based corpora supplements existing methods.
6. Discussion
Our project’s preliminary findings are striking: First, our results show the potential of synthetic visual methods (SVM) techniques in transforming thematic textual data into visually compelling meta-narratives that support primary qualitative and deeper socio-computational inquiries. Second, our findings underscore the importance of innovation in experimental critical perspectives in digital social research, particularly concerning the biases and limitations inherent in generative tools and AI models, including for generating visuals around political topics, debates, and issue controversies.
6.1 Critical Reflection on AI / Data Technics
From a critical media and ‘data technics’ perspective, examining why -- and how -- certain statements made by Trump in the 2024 Presidential debate carry through to specific, and potentially predictable color palette combinations and synthetic media formats (e.g., imagined 'memes' and captioned photos, newspaper headlines, stacks of documents, Tweet/X and Instagram posts, etc.) involves understanding both the technical mechanisms of the models, and the socio-cultural contexts deeply embedded within the model and stack (e.g., encoder, tokenizer, etc.) used for generating synthetic visuals.
The training datasets for Stable Diffusion include vast repositories of scraped data (SD 2/2.1/XL uses LAION-5B), which contain amounts of human-generated content that include a range of representations of influential public figures, arguably none more prevalent and ubiquitous that Donald Trump. These underlying datasets encapsulate the collective media portrayal, computationally positioning it against prevailing cultural narratives, and to some degree, against societal biases associated with these figures. Generative AI models such as SD 2 and 3, including in their initial tokenization process draw on associative patterns that are present in both inputs (i.e., prompts) as well as within model-specific tuning and the underlying training data.
The dominance of Trump in both candidates' debate transcript imagery is interesting, but not surprising. The ubiquity of and portrayal of Trump in contentious and confrontational contexts in news and more recently, on social media over the past decade surely contributes to the dominance our 2024 debate visuals.
What is most interesting is that statements made by both candidates generate highly specific types of visuals (e.g., aggressive, large font, imaginary 'memes', imagined X/Twitter posts, etc.). In our results, when Stable Diffusion processed the textual inputs from CNN's 2024 debate transcripts, despite statements never mentioning him by name, the model’s algorithms appear to co-locate themes and visualize sentiments that are in closest proximity in the model and training data. At least for Stable Diffusion 3-medium, Trump appears to be in closer proximity than Biden for issues and topics covered in the first 2024 US Presidential debate.
Furthermore, our results show that statements made by Trump are visually interpreted within a distinct framework of conflict, intensity, and controversy. The visual outputs directly reflect Trump’s form and style of communication, including his use of social media posts, Trump’s go-to campaign tactics, extending to imagined captioned photos and aggressive ‘memes’, which led to synthetic visual outputs that reflect these themes in media formats and color-specific moods.
6.2 Color Moods + Affective Resonance
The color palettes extracted from our synthetic visuals are influenced in part by the emotional resonance of the text. Darker and more intense colors, such as those shown in Trump’s transcript visuals, can be associated with negative emotions including retribution, frustration, and conflict. These color choices are influenced to some extent by the model’s ‘understanding’ of the valence and sentiment conveyed in the text, as well as the historical representation of similar sentiments and archived events that appear in the visual outputs (e.g., the Great Depression, FDR, etc - see Image 5.3-4).
However, our results show that the statements by both Trump and Biden in the 2024 presidential debate that involved strong opinions, controversial topics, character attacks, and combative language triggered synthetic visual representations with corresponding color palettes/moods, but also generated specific forms of media (e.g., imagined Facebook and Instagram-specific posts; attack 'memes', captioned photos; instances of on-the-ground and 'citizen journalism (print media covers, courtroom battles (see Image 5-4.1), and even stacks of voter pamphlets and election registration documents (see Image 5-4.2)
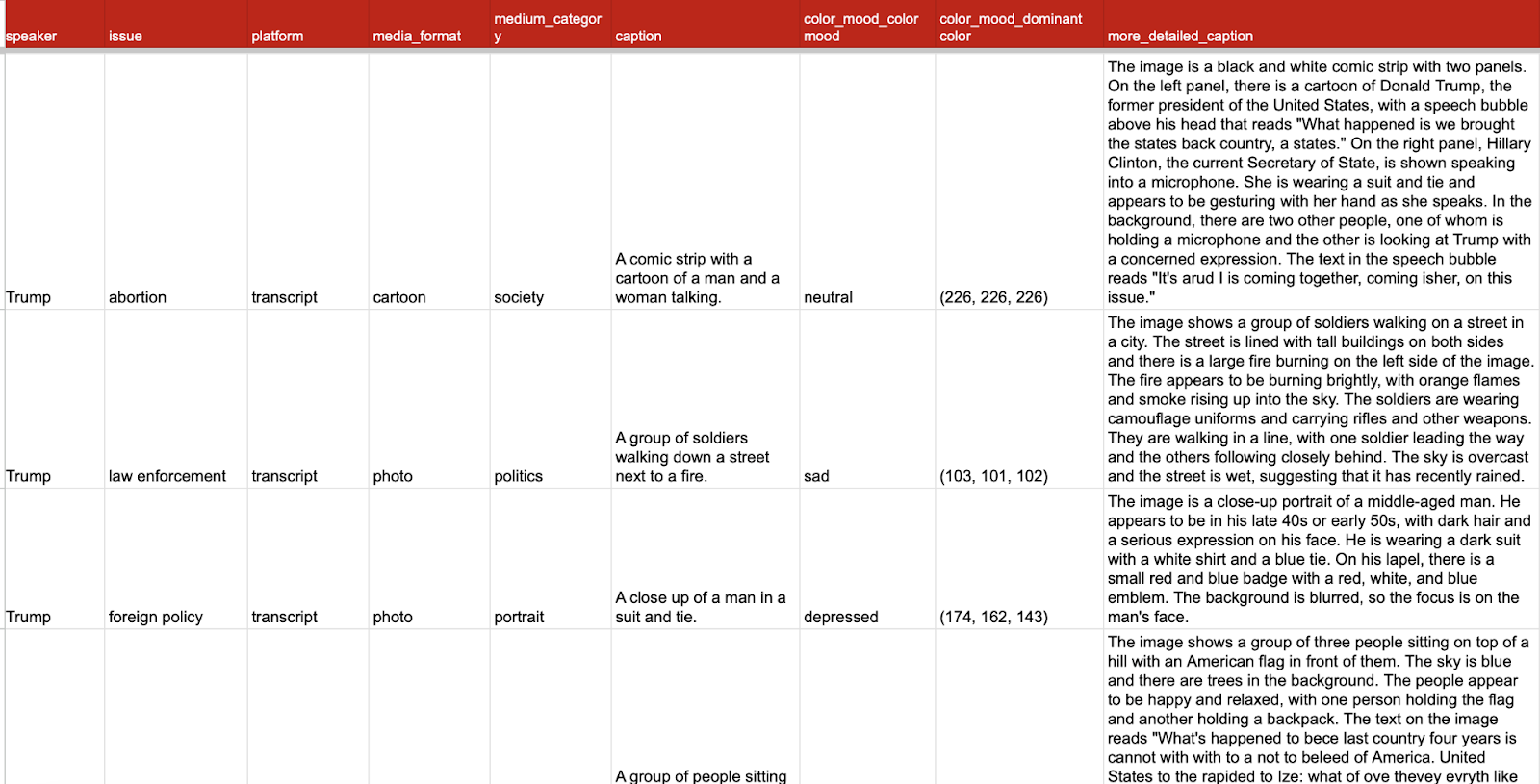
Image 6.2: Example of data analysis outputs (Florence-2 captions)
6.3 Media Formats + Discursive Strategies
Memes, captioned photos,and platform-specific social media posts were the most frequent media formats seen in the generated visuals for both Trump and Biden's transcripts in the 2024 presidential debate (see Images 5.3-1, 5.3-2 and 5.4-4) . These synthetic media formats are surely attributed to the pervasive use of these formats in political discourse, where Trump is frequently a subject of social media commentary and media-focused satire, and the tool he strategically leverages to share his views and opinions on social media. In other words, Stable Diffusion 3-medium, used in this project appears to ‘recognize’, at least to some degree, the alignment between Trump’s statements (i.e, as prompts) and the cultural landscape in which the statements are being made.
Looking at the outputs seen in the Images above (see Images 2 and 2.1 and Images 5.3-1 to 5.4-5), the capability includes not just imagining how discourse is situated in the present, but how it aligns with corresponding meme culture, combative discourse, and aligning broadcasted statements with machine learning-optimized campaign tactics. This appears to help lead to the generation of synthetically-aligned visuals as shown in the outputs with situationally, context-appropriate media formats.
Next, the nature of print media and journalistic photos generated in Trump’s synthetic outputs further reflect the nature of elite and style institutional media attention he receives. These outputs thus mirror the media’s practice of using striking images and controversial headlines to capture public attention around Trump, and his propensity to leverage it for his own gain, particularly when the coverage involves issues such as abortion rights, which he has resituated through recent policy, appointments, and actions/orders.
Finally, we ran an initial statistical analysis to discover if there were any significant correlations in the relationships between color palettes, color moods, and sentiment and the resulting generated media format. This needs further investigation as we only had a few days to work on this part of the project, however, we suspect there is some evidence of correlation between the captioned photo / imagined 'meme' format and the mood: ‘indifference’.
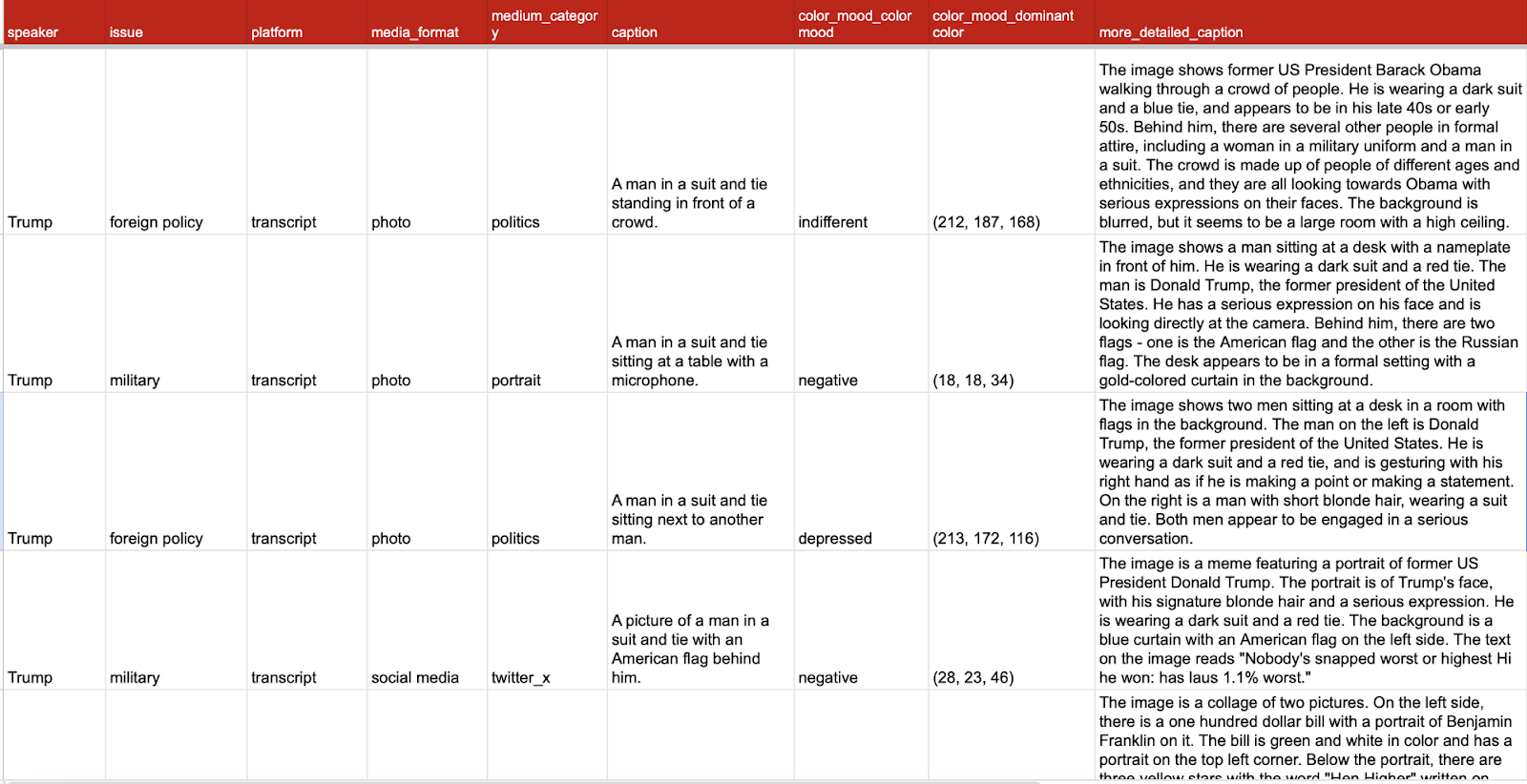
Image 6.3: Example of data analysis outputs cont.
6.4 Socio-Technical Feedback Loop
Cultural Narratives: It should be emphasized that generative (AI) models are not isolated from the socio-cultural contexts in which they are designed, tested, trained, and deployed. The portrayals of Trump in the debate-generated images are influenced by the broader cultural narratives and the journalistic and media-specific practices that shape public perception. This creates a feedback loop where the models such as Stable Diffusion (3-medium, in this case) both reflect and reinforce these narratives.
Critical Implications: Understanding the socio-technical feedback loop is crucial for critical data inquiry. It highlights the need for researchers to be aware of the biases and cultural contexts embedded in generative models. Using synthetic methods to reflect on these aspects, researchers can develop more nuanced and responsible approaches to using AI in digital research.
The generation of specific color palettes and media formats in response to Trump’s statements underscores a powerful interplay between black-box ML and algorithmic processes and associative socio-cultural influences. By further critically examining this specific area, research can gain deeper insights into how models interpret and visualize textual data, and how these interpretations are reflexively shaped by the broader media and cultural landscapes. This experimental reflective approach is essential for advancing the ethical and effective use of AI in digital research.
7. Conclusion
The integration of synthetic methods into digital research represents a significant advancement in our ability to capture and analyze the visual essence of digital discourse. By leveraging generative tools such as Stable Diffusion, we can transform abstract sentiments and themes into rich, multi-layered visual data, providing new dimensions of understanding and interpretation. Continued development and refinement of methods and tools will improve the analysis of contemporary digital platforms' complex visual landscapes.
Appendix 1. Visualizations and Insights
- Sentiment Distribution by Candidate:
-
Shows the distribution of sentiment values for Biden and Trump.
-
Highlights the emotional tone captured in the generated visuals.
-
-
Word Cloud of Common Terms:
-
Word clouds for each candidate highlight the most frequently discussed topics and terms in the Florence-2 captioned synthetic visual outputs
-
-
Color Mood Analysis:
-
The bar chart shows the distribution of different color moods across the generated images for each candidate.
-
Uses lower opacity for Biden and solid fill for Trump to differentiate between candidates.
-
-
Media Format Distribution:
-
Shows the distribution of different media formats (e.g., photo, social media) used in the generated images for each candidate.
-
-
Key Themes and Issues:
-
Shows the most common issues discussed by each candidate, providing insights into their focus areas.
-
Appendix 2. Additional Insights from SynthViz Posters
-
Media Formats: The predominant media formats are photos and memes for Trump, and photos for Biden.
-
Color Mood: Predominant colors are brown for Trump and grey for Biden, reflecting the dominant tones of their visuals.
-
Subjects and Themes: Extracted people from synthetic visuals include prominent figures and common themes such as politics, healthcare, and public speeches.
-
Similarity and Sentiment Analysis: Graphs show the similarity scores between different media formats and the sentiment associated with each visual, providing a nuanced view of the debate dynamics.
-
Detailed Caption Analysis: Highlighted the alignment of generated captions with the input texts, reflecting the effectiveness of the SVM in capturing and transforming the discursive traits of the debate transcripts.
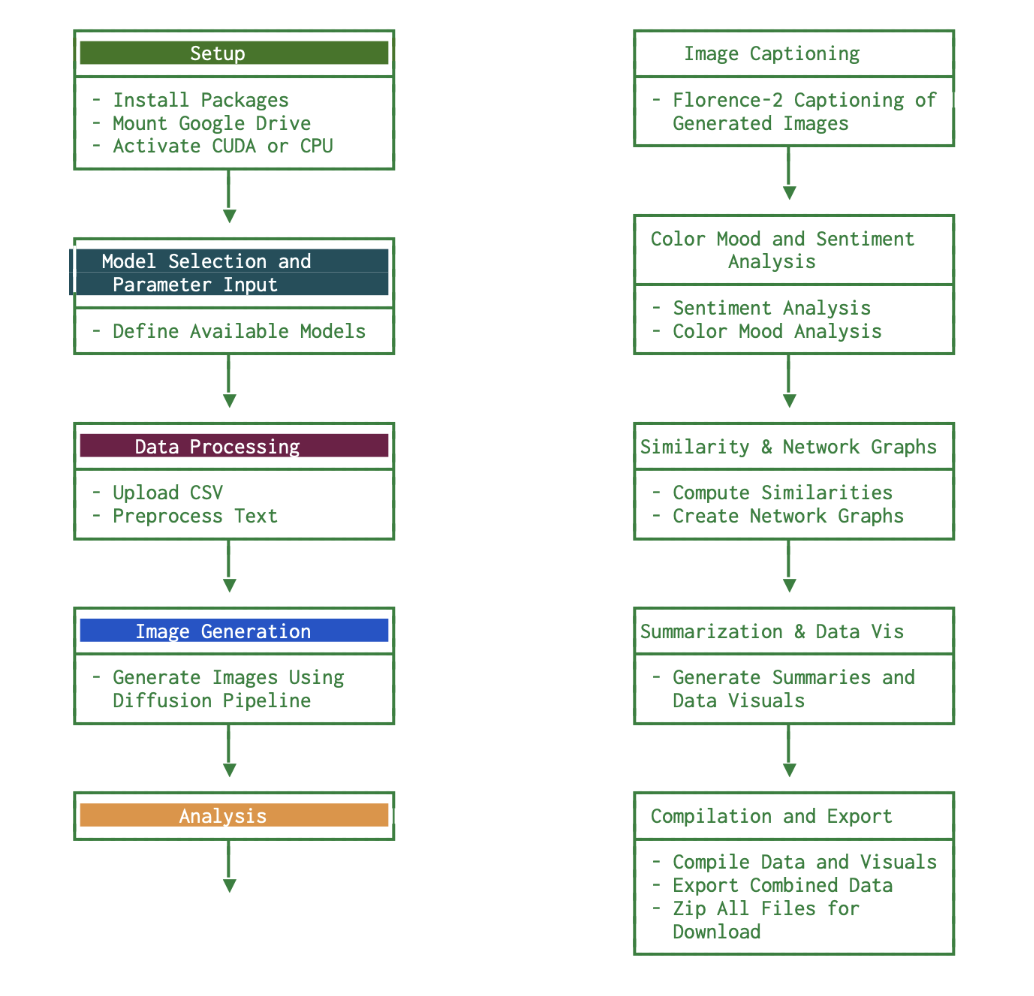
Appendix 3: SynthViz Flowchart (Simplified)
References
Feher, K. (2024). Exploring AI media. Definitions, conceptual model, research agenda. Journal of Media Business Studies, 21(4), 340–363. https://doi.org/10.1080/16522354.2024.2340419 Florence-2, Microsoft (2023). Computer Vision Analysis. Model content paper available at: HuggingFace Florence-2 Hilbert, M., Barnett, G., Blumenstock, J., Contractor, N., Diesner, J., Frey, S., González-Bailón, S., Lamberso, P., Pan, J., Peng, T.-Q., Shen, C., Smaldino, P., Van Atteveldt, W., Waldherr, A., Zhang, J., & Zhu, J. H. (2019). Computational Communication Science: A Methodological Catalyzer for a Maturing Discipline. International Journal Of Communication, 13 (23). https://ijoc.org/index.php/ijoc/article/view/10675/2764 LAION-5B: A Large-scale Dataset for Training Multimodal Models. Retrieved from LAION. Pink, S. (2019). Digital Social Futures Research. Journal of Digital Social Research, 1(1), 41–48. https://doi.org/10.33621/jdsr.v1i1.13 Rogers, R. (2013). Digital methods. MIT Press. Stable Diffusion Models (2023). AI Image Generation. Details at https://stablity.ai Stable Diffusion 3-Medium (2024). Diffuser hosted at HuggingFace. Available at: HuggingFace Stable Diffusion 3 Van Der Wal, O., Bachmann, D., Leidinger, A., Van Maanen, L., Zuidema, W., & Schulz, K. (2024). Undesirable Biases in NLP: Addressing Challenges of Measurement. Journal of Artificial Intelligence Research , 79 , 1–40. https://doi.org/10.1613/jair.1.15195-- JonathanA
Ideas, requests, problems regarding Foswiki? Send feedback