Mapping Multiverse Alternative Facts In the Age of Post-truth
Team Members
- Ivan Kisje
- Kaspar Beelen
- Derrek Xavier
- Tommaso Elli
- Felipe Escobar
- Abraham Koshy
- Jesper Hinze
- Emillie V. de Keulenaar
- Marc Tuters
- Daniel de Zëuw
- Giovanni Profeta
- Nina Welt
- Aurelio Amaral
- Michele Mauri
Contents
General introduction
This project considers how alternative wikis, or 'Altpedias', create and maintain their own universes of 'alternative facts'. Specifically, it uses visual network analysis and word2vec in order to represent the vernacular worldviews of a number of online encyclopedia projects, including en.metapedia.org, infogalactic.com, and en.rightpedia.info. In addition to representing their particular ideologies, our analysis demonstrates the strategic position these projects take in curating the information they propagate and their vision of what ‘good’ knowledge amounts to. We argue that ‘alternative facts’ are not so much the products of a certain disregard for truth, but rather information stemming from different normative standpoints from which ‘knowledge’ is defined and used for. In Rightpedia, Metapedia and Infogalactic, these standpoints often ascribe to libertarian and far-right political movements. Our analysis thus considers the role that these alternative online encyclopedia projects might play in the constitution of new kinds of postmodern publics whom define truth in (and due to) opposition to one another, carving self-contained worldviews.Summary of Key Findings
-
Rationalwiki offers a large number of references in their articles - and a broad variety thereof compared to its competitors. But does the variety of sources contribute to debunk myths and conspiracy theories?
-
The ‘openness’ of Wikipedia can only go so far -- until users with fundamental ideological disagreements shift to ‘alt-pedias’, each with their own alt-facts and methods of validation.
-
The creation of alt-facts in alt-pedias is usually due to users being banned for infringing upon these methods of validation.
-
If we want to understand the problem of so-called "post-truth", fact-checking is not enough. Rather, we need to understand the role of alt-facts in relation to the particular language games of the platforms which cultivate them.
I. Alt-facts and edit wars on race and intelligence from Wikipedia to Altpedias
Introduction
Today, propagating such types of ‘alternative facts’ does not appear to have limited itself to locations such as the Facebook Newsfeed, the YouTube recommender system or 4chan/pol/ threads. While they are certainly present in those places, presenting, debating, substantiating and propagating these is a process equally prone to wikis, whether these are Wikipedia or more politically oriented alternatives, or ‘alt-pedias’: Metapedia, Infogalactic, Rightpedia, and Rationalwiki. In these wikis, information related to the debate on race and intelligence is indeed highly subject to the political orientation of each wiki. While most Wikipedia editors curate information about the debate as to elaborate on a discredited pseudoscience with a problematic history, other editors attempt to bring the debate back to a state of relevance with sources and statements ‘backed’ by radically different sources, under radically different premises of what accounts to historical validity. Banned for posting unsubstantiated sources, these dissident editors tend to unite and go on to create their own wikis, starting with a fork or copy of the original Wikipedia page that they then re-write or ‘correct’ overtime.
This sub-project looks into the process of this ‘wiki revisionism’ as an example of how the factual status of information is negotiated amongst different political actors. As we will see, the validity of ‘facts’ is but an output of a long process of discussion (or ‘edit wars’) amongst such actors. In each wiki, the ‘factual’ status of information on race and intelligence is determined by editors within their limited definition of factuality -- or, to paraphrase Lyotard, their own ‘language games’. While on Wikipedia, ‘facts’ are substantiated by a ‘neutral point of view’, ‘verifiability’ and cannot originate from a user’s own ‘original research’, alternative wikis prize a set of different protocols where veracity is itself conceptualised under widely different terms, or is instead sacrificed for a wider, political mission to ‘influence language’ in the name of a ‘metapolitical and cultural struggle’ (Metapedia 2018).
Each wiki contains a different set of protocols to substantiate information in opposition or distinction to the one proposed by Wikipedia. And so, disputing or ‘correcting’ the veracity of ‘factual’ information it is not limited to each wiki, its editing processes or edit wars. It ranges instead from one wiki to another, in a cross-wiki fashion, making it necessary to explore how information on race and intelligence is edited and validated from the original wiki in which it was stated to the one in which it is then re-written.
-
What are the basic “facts” of Altpedias?
-
What are the particular “worldviews” defended by each Altpedia?
-
How do Altpedias rely on information provided by Wikipedia, and how do they then alter it?
-
In light of existing research on Wikipedia, what can we say are the main dynamics governing Altpedias?
-
Taking into account the above-mentioned questions, how can we say different Altpedias “do issues”
Methodology
This sub-project has been divided in several methodological steps.
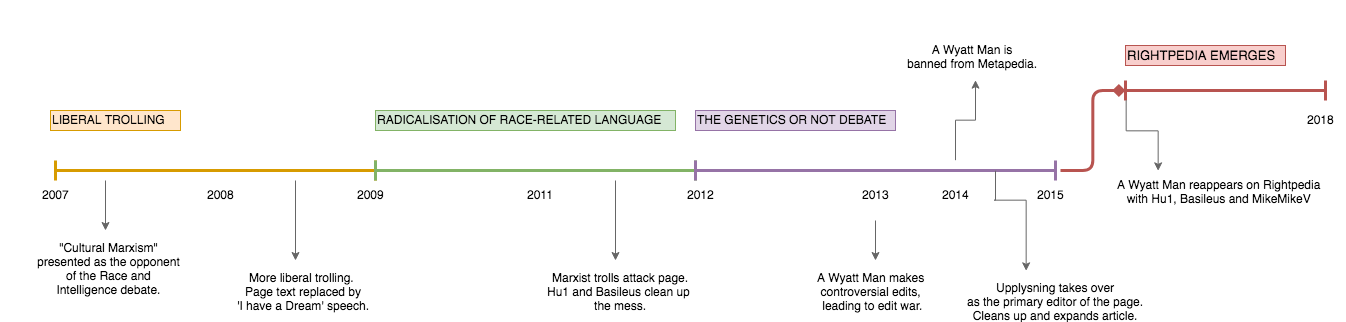
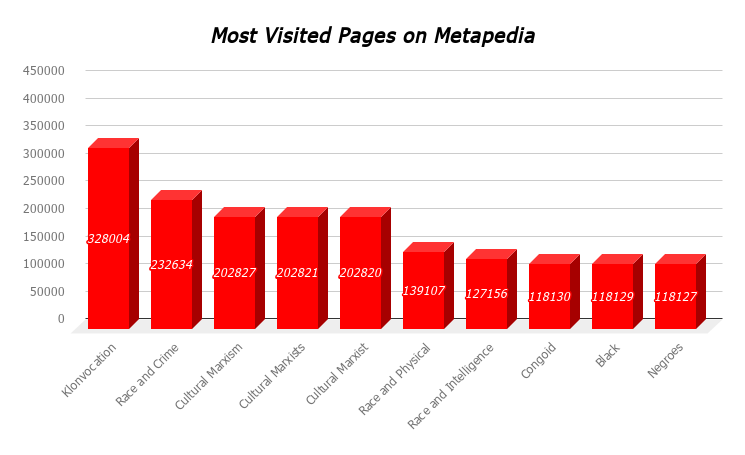
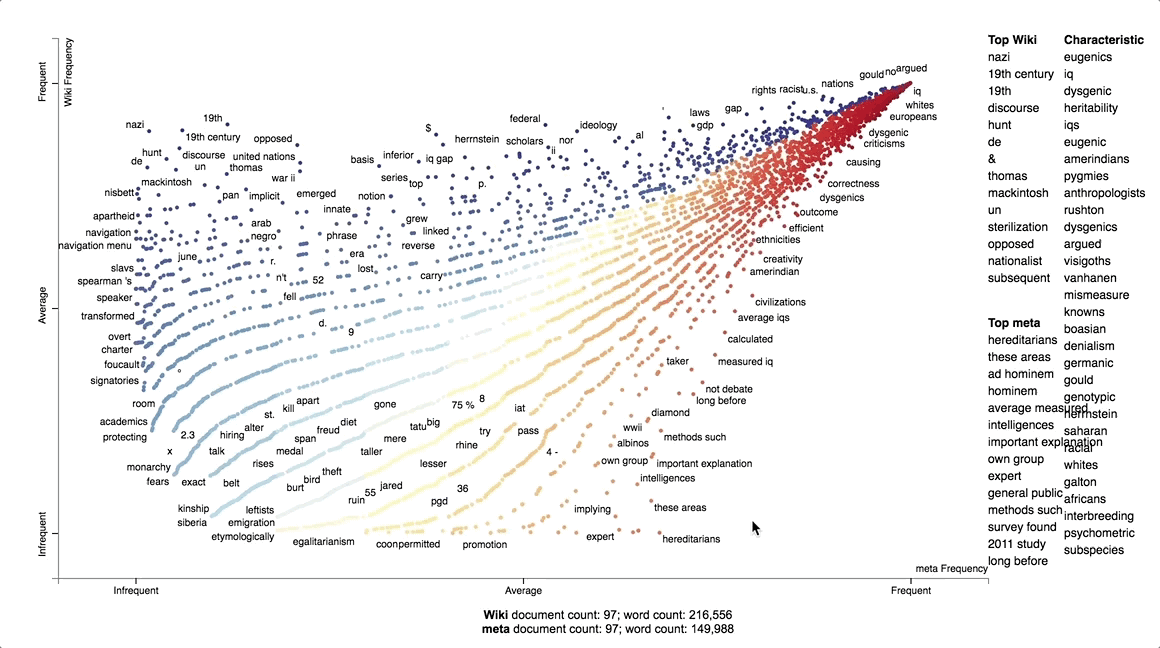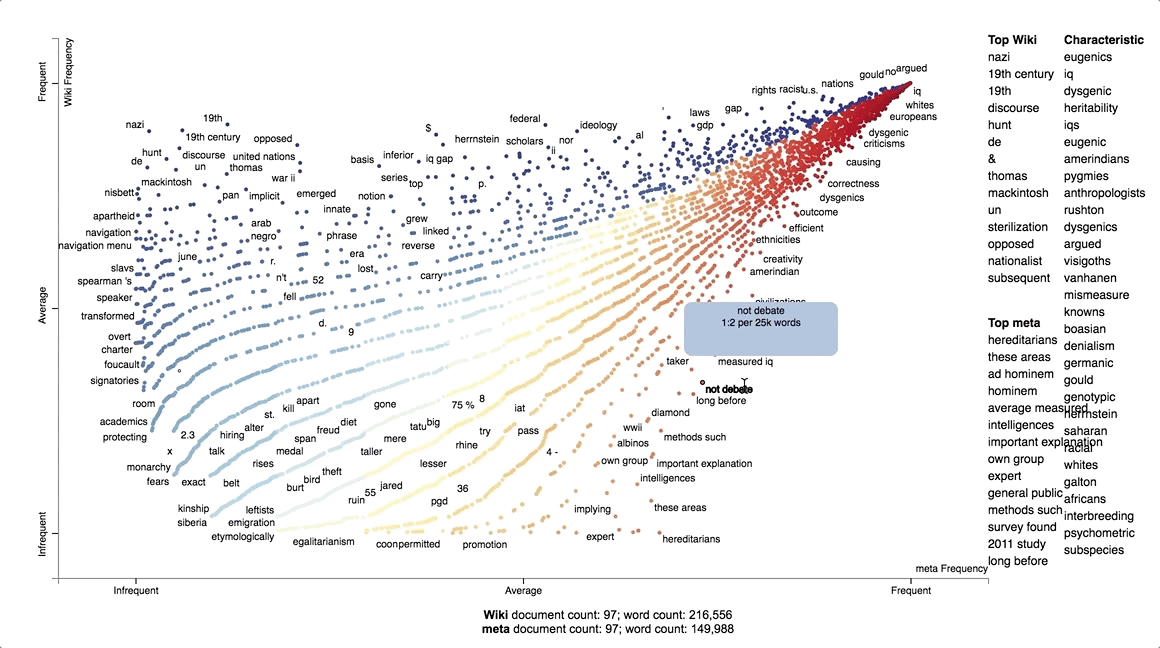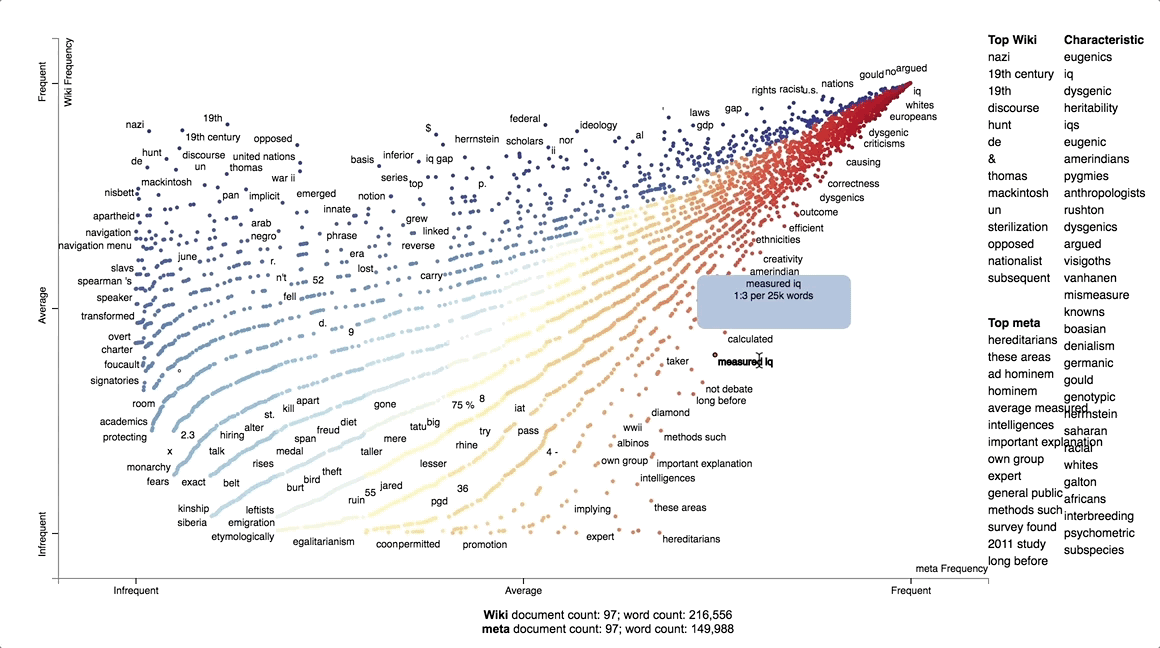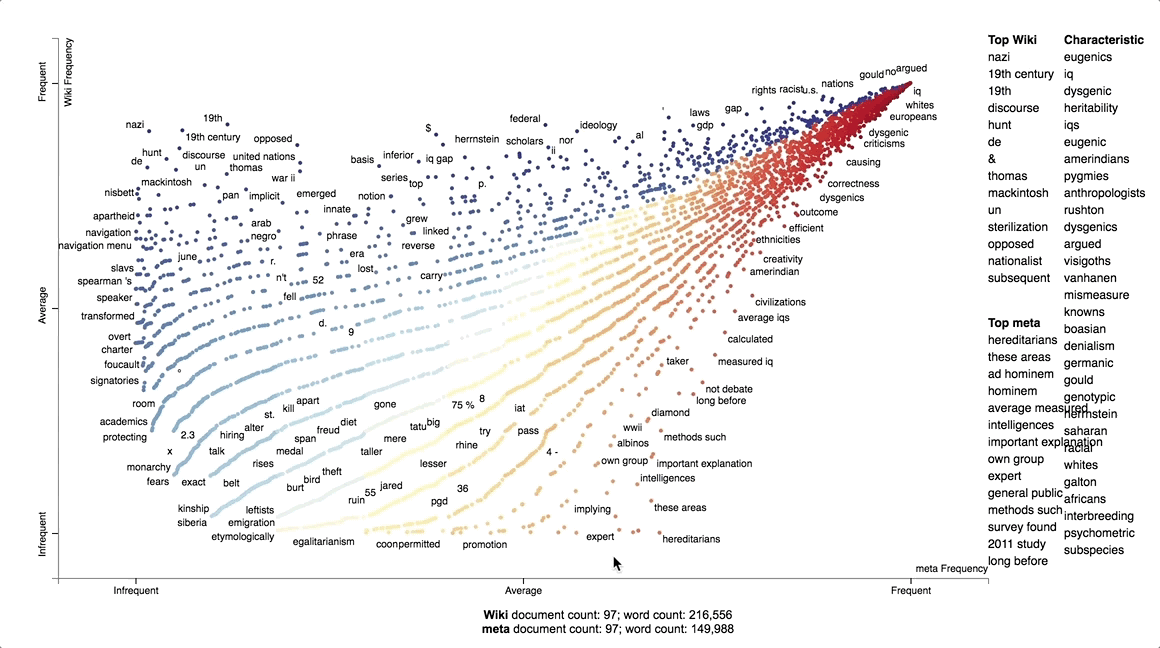
The first of these was to justify our choice to examine the Wikipedia and alt-pedia pages on race and intelligence. This project was originally intended to focus on their pages on the Holocaust, due to the prominence of harder ‘factual’ historical evidence we could easily scrape and examine with computational techniques. This was not a sufficiently well-grounded reason, however, since the Holocaust page was not amongst the most visited in alt-pedias. In Metapedia, in particular, the most prominent pages are on the Ku Klux Klan, Anglo-Saxon far-right parties like Britain First and the American Freedom Party, and several pages focused on race: race and crime; race and physical attractiveness; and race and intelligence. Of these, race and intelligence was most prone to contain ‘factual’ information, such as statistical numbers, visual evidence, cited arguments and sources. Most importantly, race and intelligence was a page we found across all wikis -- and, as we explain further on, was an important source of disagreements amongst editors from one wiki to another.

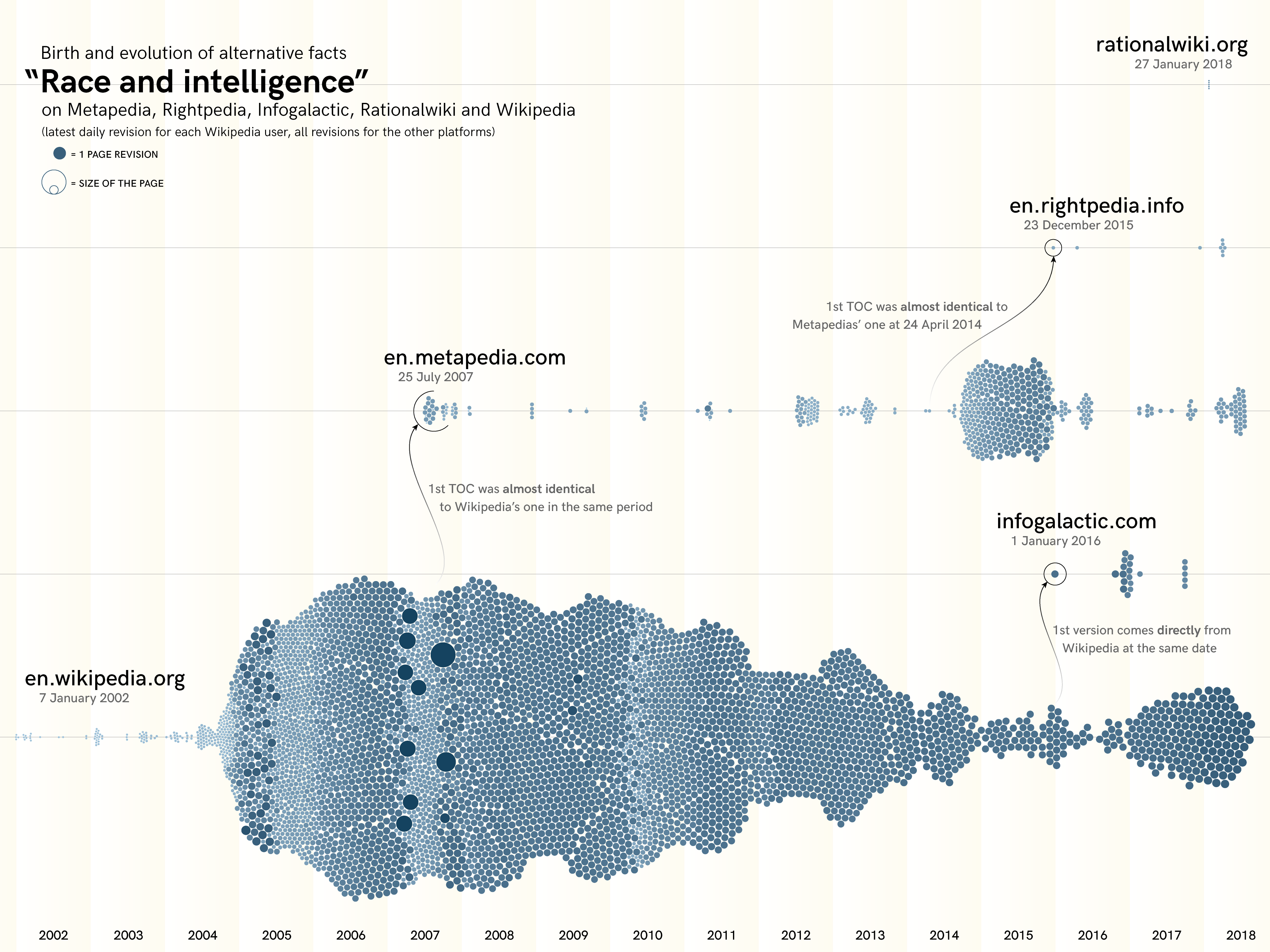
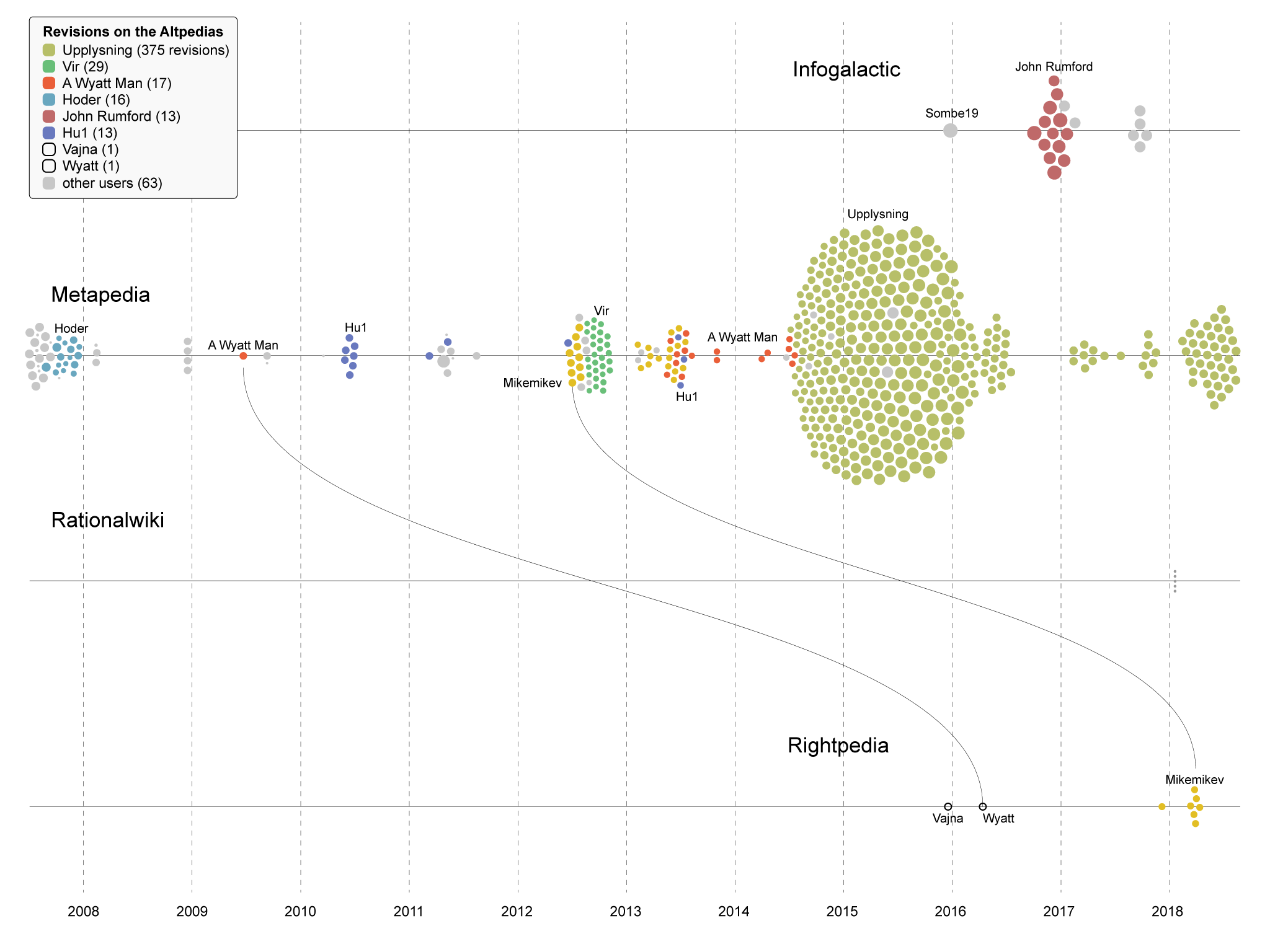
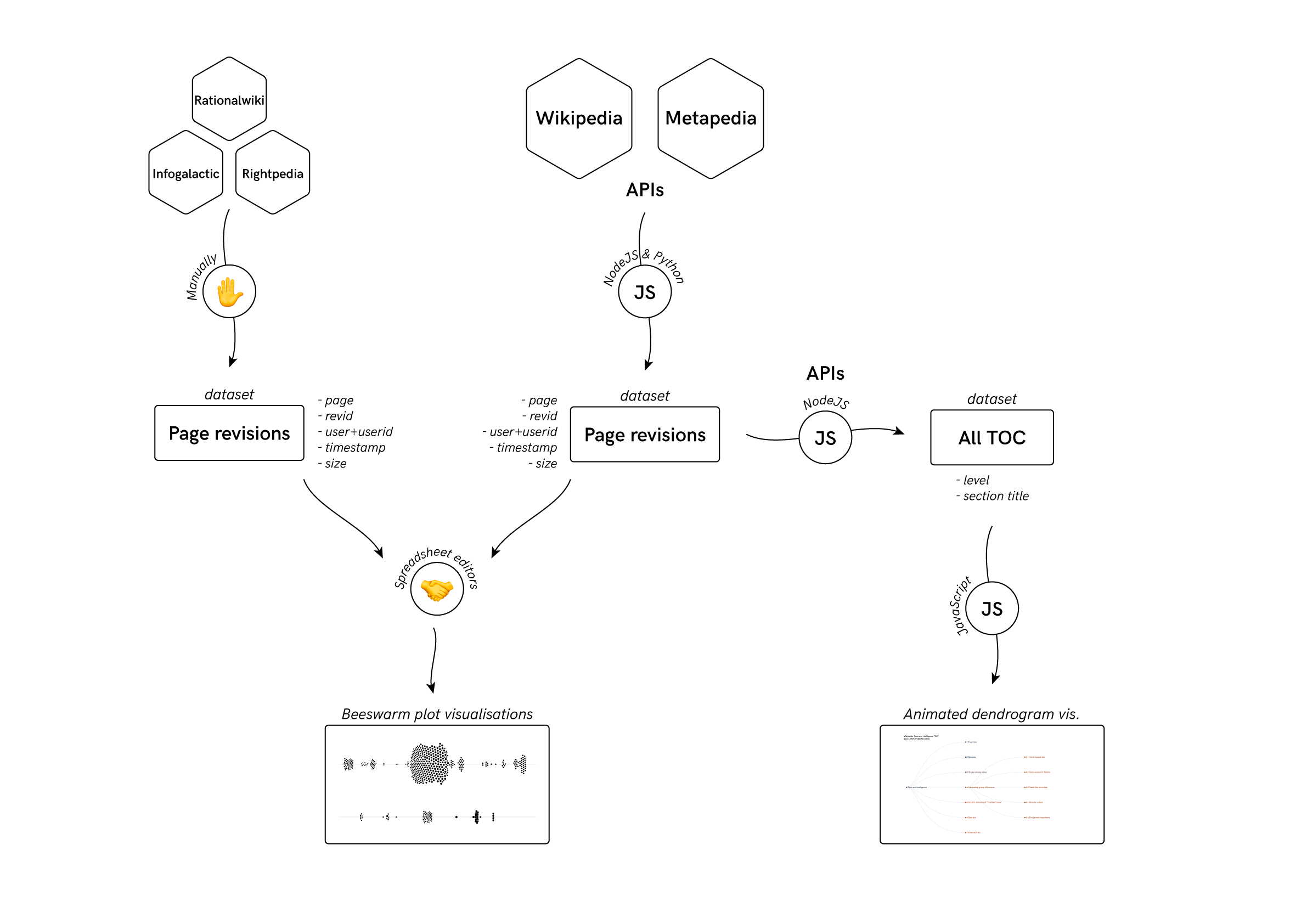
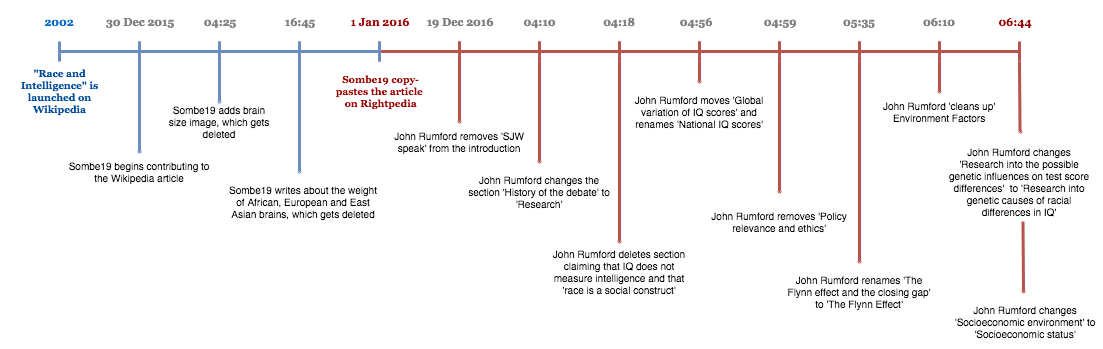
In order to assess how pages race and intelligence were edited across wikis, we first needed to determine from which of these wikis each of these pages originated from. Wikipedia’s page was not always the original source other wikis used. Through Wikipedia and Metapedia’s APIs, we were able to extract all textual from their respective race and intelligence page, their revision history, editor user IDs, and size. Combined with a manual analysis of other wiki’s page history, edit history, size and textual content, we traced the edit times and edit sizes for the race and intelligence page of each wiki. We then discovered that Wikipedia was the first to publish a page on the subject, and that, since then, only Metapedia and Infogalactic forked from it at different stages in time. Metapedia’s edited version of Wikipedia’s page was then forked to Rightpedia. Rationalwiki started from scratch and forked to no other wiki.

Having determined the origin and forks of each wiki’s page, we then wanted to assess how every page was progressively ‘rewritten’. We decided to first obtain a general impression of how pages differed from one another in their general composition, through their table of contents. Through each wiki’s API and with NodeJS, we extracted all of their table of contents overtime and visualised them via an animated dendrogram. The dendrogram juxtaposes the table of contents of the original article with that of the fork article.
We then focused on a closer reading of every page and its editing history. There were multiple elements of interest that emerged at this level of analysis, the most important of which was to determine why and how pages were forked from one wiki to another. To answer this question, we revisited the edit history of each article, from the original to its fork. We manually tracked important moments in the course of the article’s edit history, noting edit periods whereby significant amounts of text were deleted or brought in. We examined edit summaries and interactions between editors to better understand why text was added or deleted. To better illustrate this process, we made a video that showed (in the lines of Jon Udell’s Heavy Metal Umlaut) significant textual changes on the front-page of the page. Our video first showed significant edits on the original article and then goes on to detail how the forked version diverged from its original version. Significant editing moments were determined by a combination of edit size and important changes indicated by the history of a page’s table of content.

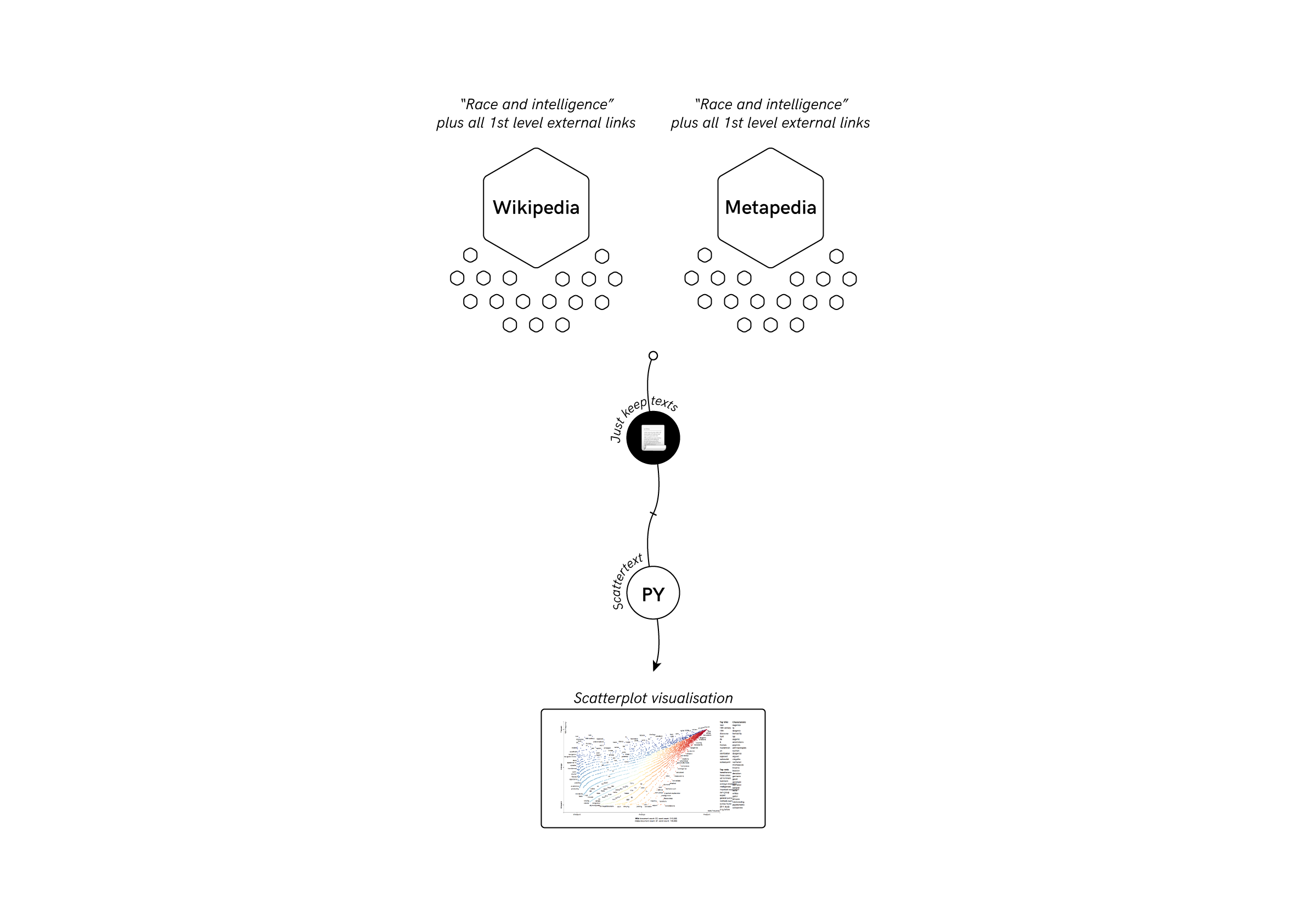
With this information, we then manually determined specific stylistic changes in edited sentences. We sought to better contextualise these stylistic changes by making a comparative text analysis of two prominent, forked wikis: Wikipedia and Metapedia. Our visualisation gave us an idea of how the language used to write each wiki’s page diverged ideologically.

Findings and discussion

 Altpedias are then often the product of editors that have been banned from Wikipedia in the context of an edit war, vandalism or a violation of conduct often at the source of deep epistemological schisms. In response to Wikipedia’s perceived ‘epistemological bias’, Altpedias a set of more objective scientific criteria that attend to more just values elaborated in their mission statements. Against Wikipedia’s ‘highly centralized structure’, Infogalactic welcomes ‘Relativity’ as a key pillar of its content guidelines (Infogalactic, 2018a). Against Wikipedia’s ‘leftist, politically correct, and anti- White bias’, Metapedia proposes to restore the ‘original meaning’ of concepts related to European history in an attempt to advance a metapolitical, ‘pro-European’ ‘cultural struggle’ (Metapedia, 2018a; Metapedia, 2018b). Rightpedia, which branched off of Metapedia in around 2007, aims to make up for its predecessor’s ‘Zionist’ agenda by providing ‘the truths that those in power don’t want people to know.’ (Rightpedia, 2018a, 2018b). Such qualifications delimit the frontiers in and out of which Altpedias question the veracity of one another.
Altpedias are then often the product of editors that have been banned from Wikipedia in the context of an edit war, vandalism or a violation of conduct often at the source of deep epistemological schisms. In response to Wikipedia’s perceived ‘epistemological bias’, Altpedias a set of more objective scientific criteria that attend to more just values elaborated in their mission statements. Against Wikipedia’s ‘highly centralized structure’, Infogalactic welcomes ‘Relativity’ as a key pillar of its content guidelines (Infogalactic, 2018a). Against Wikipedia’s ‘leftist, politically correct, and anti- White bias’, Metapedia proposes to restore the ‘original meaning’ of concepts related to European history in an attempt to advance a metapolitical, ‘pro-European’ ‘cultural struggle’ (Metapedia, 2018a; Metapedia, 2018b). Rightpedia, which branched off of Metapedia in around 2007, aims to make up for its predecessor’s ‘Zionist’ agenda by providing ‘the truths that those in power don’t want people to know.’ (Rightpedia, 2018a, 2018b). Such qualifications delimit the frontiers in and out of which Altpedias question the veracity of one another.
 In this sense, Altpedias are not just articulated by different content and vernaculars, but also by a different normative definition of knowledge and what it ought to be used for. This tightly knit relation between science and ethics echoes Lyotard’s own description of what he called the ‘delegitimation’ of competing types of knowledge (Lyotard 1984, 37). At the source of the questioned legitimacy of a type of knowledge is a question of ‘double legitimation’: ‘[...] who decides what knowledge is, and who knows what needs to be decided?’ (Lyotard 1984, 8-9). Both of these questions are answered by each Altpedia to various extents, but always within declared opposition against those it sees as ignoring the types of content it considers legitimate. Just as Lyotard argues that knowledge is legitimised by laws that are promulgated as norms (Lyotard, 1984, 8), Altpedia mission statements will select and argue in favour of norms it defends as criteria of ‘good’ knowledge. They then elucidate what content does or does not satisfy to these standards within a structure starting from the normative approach of mission statements to the practical guidelines of manuals of style. Wikipedia’s own mission statement (what it calls ‘Purpose’) recurs in many respects to a universalist and post- ideological vision of knowledge, validating criteria it perceives as necessary to obtain an ‘open’, ‘free’ and democratic form of knowledge production (Wikipedia, 2018e, 2018f). Metapedia, Rightpedia and Infogalatic’s mission statements all undermine the universal extent of Wikipedia’s, accusing it of bias and omission of valid topics.
In this sense, Altpedias are not just articulated by different content and vernaculars, but also by a different normative definition of knowledge and what it ought to be used for. This tightly knit relation between science and ethics echoes Lyotard’s own description of what he called the ‘delegitimation’ of competing types of knowledge (Lyotard 1984, 37). At the source of the questioned legitimacy of a type of knowledge is a question of ‘double legitimation’: ‘[...] who decides what knowledge is, and who knows what needs to be decided?’ (Lyotard 1984, 8-9). Both of these questions are answered by each Altpedia to various extents, but always within declared opposition against those it sees as ignoring the types of content it considers legitimate. Just as Lyotard argues that knowledge is legitimised by laws that are promulgated as norms (Lyotard, 1984, 8), Altpedia mission statements will select and argue in favour of norms it defends as criteria of ‘good’ knowledge. They then elucidate what content does or does not satisfy to these standards within a structure starting from the normative approach of mission statements to the practical guidelines of manuals of style. Wikipedia’s own mission statement (what it calls ‘Purpose’) recurs in many respects to a universalist and post- ideological vision of knowledge, validating criteria it perceives as necessary to obtain an ‘open’, ‘free’ and democratic form of knowledge production (Wikipedia, 2018e, 2018f). Metapedia, Rightpedia and Infogalatic’s mission statements all undermine the universal extent of Wikipedia’s, accusing it of bias and omission of valid topics.
 What is notable about ruptures between wikis is that the mission statements each uses to redefine their purposes as encyclopaedia does not focus solely on specifying what they deem as ‘good’ knowledge, but also on choosing a relatively unique set of epistemic concepts. Altpedias promulgat norms they see as necessary to remediate Wikipedia’s unjust curation of knowledge and definition of what qualifies it as ‘good’. While Metapedia focuses on content, particularly as to compensate what it perceives is Wikipedia’s omission of a ‘pro-European’ perspective of history, Rightpedia and Infogalactic attempt to revert Wikipedia’s definition of what count as good theories of knowledge. Wikipedia’s categorisation of pseudoscience, conspiracies and fringe theories as subjects not worth of serious scientific scrutiny makes for Rightpedia’s mission as an ‘exhaustive record’ of perspectives expressed in fringe theories, conspiracies, and pseudosciences. Infogalactic, on the other hand, chooses to go beyond content. It criticises Wikipedias ‘centralist’, ‘ideological’ and objectivist approach to curating knowledge, opting instead to do justice to a criteria of ‘relativity’ by adding page categories such as ‘opinion’ (Infogalactic, 2018b).
What is notable about ruptures between wikis is that the mission statements each uses to redefine their purposes as encyclopaedia does not focus solely on specifying what they deem as ‘good’ knowledge, but also on choosing a relatively unique set of epistemic concepts. Altpedias promulgat norms they see as necessary to remediate Wikipedia’s unjust curation of knowledge and definition of what qualifies it as ‘good’. While Metapedia focuses on content, particularly as to compensate what it perceives is Wikipedia’s omission of a ‘pro-European’ perspective of history, Rightpedia and Infogalactic attempt to revert Wikipedia’s definition of what count as good theories of knowledge. Wikipedia’s categorisation of pseudoscience, conspiracies and fringe theories as subjects not worth of serious scientific scrutiny makes for Rightpedia’s mission as an ‘exhaustive record’ of perspectives expressed in fringe theories, conspiracies, and pseudosciences. Infogalactic, on the other hand, chooses to go beyond content. It criticises Wikipedias ‘centralist’, ‘ideological’ and objectivist approach to curating knowledge, opting instead to do justice to a criteria of ‘relativity’ by adding page categories such as ‘opinion’ (Infogalactic, 2018b).

Conclusions
It is not that Altpedias do not necessarily go on a direct affront against truth, nor that their criteria of truth are distinct. Altpedias are rather applications of mission statements, content guidelines and editing ‘language games’ that spell out different criteria as to what is and is not worth and good knowing. These guidelines are written in direct opposition to other wikis, as each of them results from unresolved epistemological ruptures separating one another. These ruptures are marked not just by disagreements regarding content, but also about how each wiki allows one to qualify knowledge as ‘good’, and thus knowable, based on the normative guidelines it stands upon. It may be fair to say that, with the exception of Rightpedia, all wikis share a more or less similar set and definition of key concepts in their guidelines, including neutrality, objectivity, the need of references and citations, criteria for their reliability, credibility and accuracy. All agree that neutrality, reliability, credibility, accuracy and the use of good sources are necessary tenets for an encyclopaedia that wishes to be credible, serious and exhaustive about the content it publishes. But their choice of what content attends to these values mark ‘epistemological biases’ from which follow different applications of ideas as to what is and is not ‘good’ knowledge, how best to substantiate it, and which criteria best ensure its credibility. Following this analysis, we would add to Lyotard’s description of postmodernity as a period characterised by knowledge past meta- narratives a slight but important nuance brought by this small case study on alternative encyclopaedias. While data banks’ remain ‘the encyclopedia of tomorrow’, they are still subject to agonistics caused by unresolved disagreements as to what amounts to ‘good’ knowledge. As is the case in Altpedias, normative definitions of knowledge are still elucidated by different visions of history, and, in this sense, narrative knowledge. While Wikipedia has been designed to host as many ‘narratives’ as possible, it does so within a limited spectrum as to what are good and bad conducts, criteria, and forms of knowledge. Altpedias attempt to surpass these limits in their very condition of ‘alternative’ data banks curated by alternative narratives.II. A cartography of Rational-Wiki
Findings

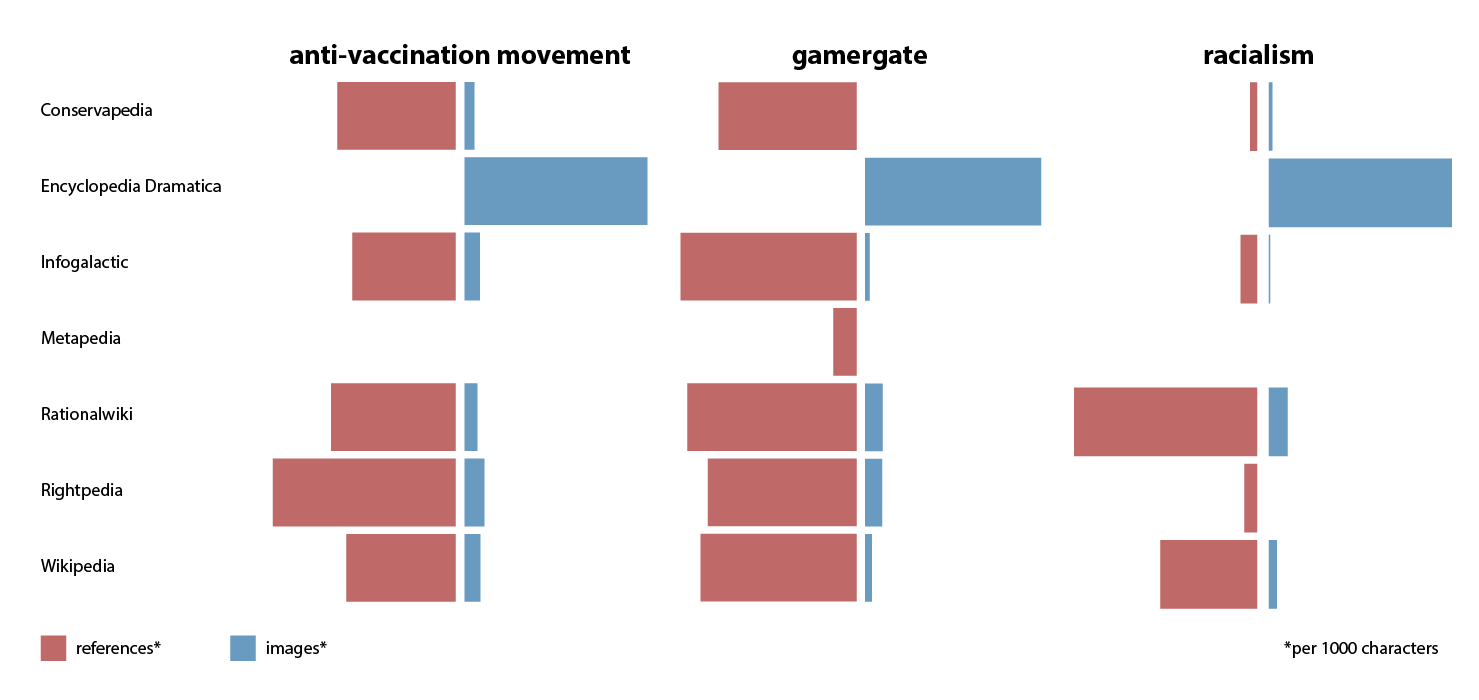
A) Image comparison per article





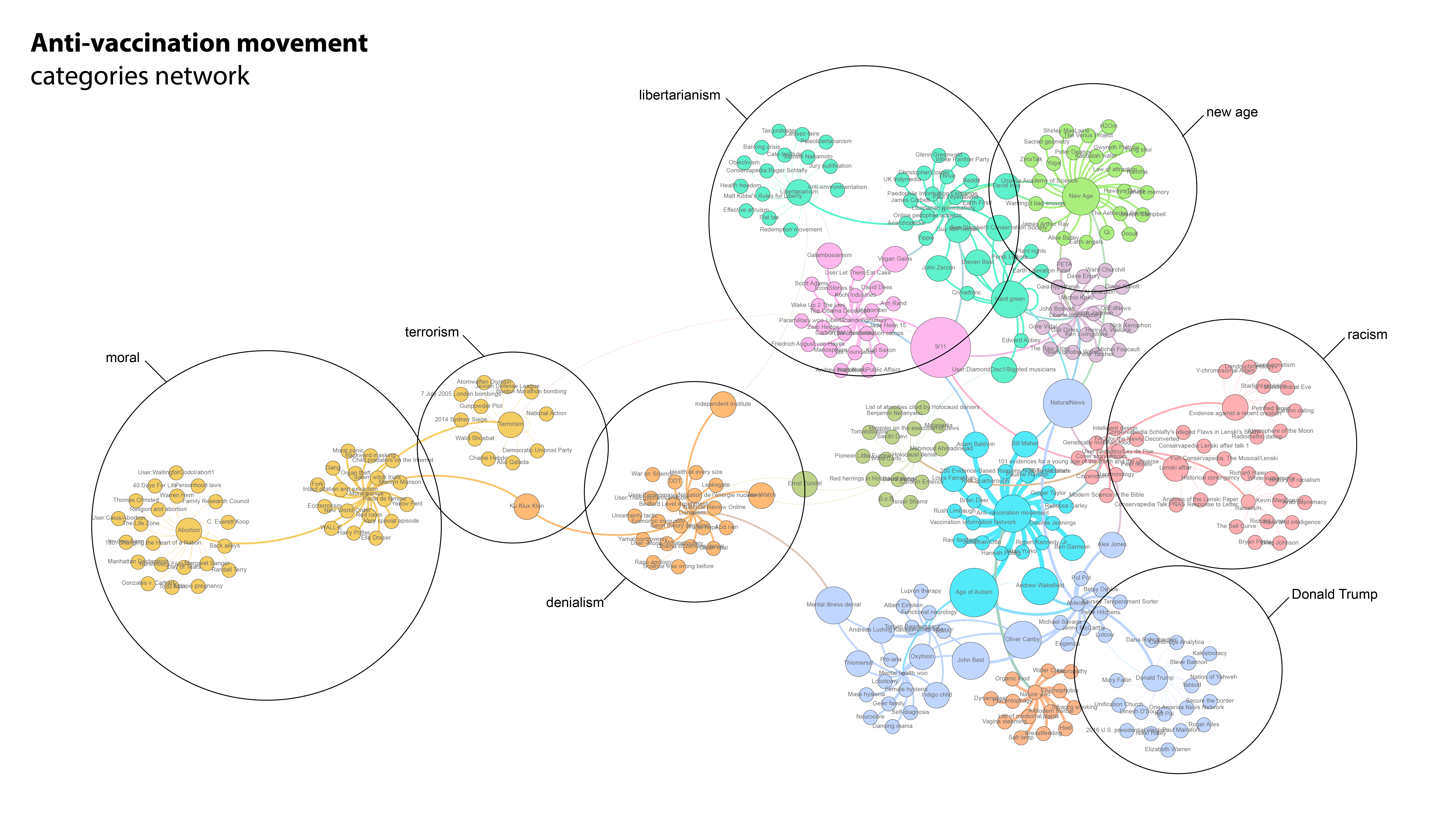
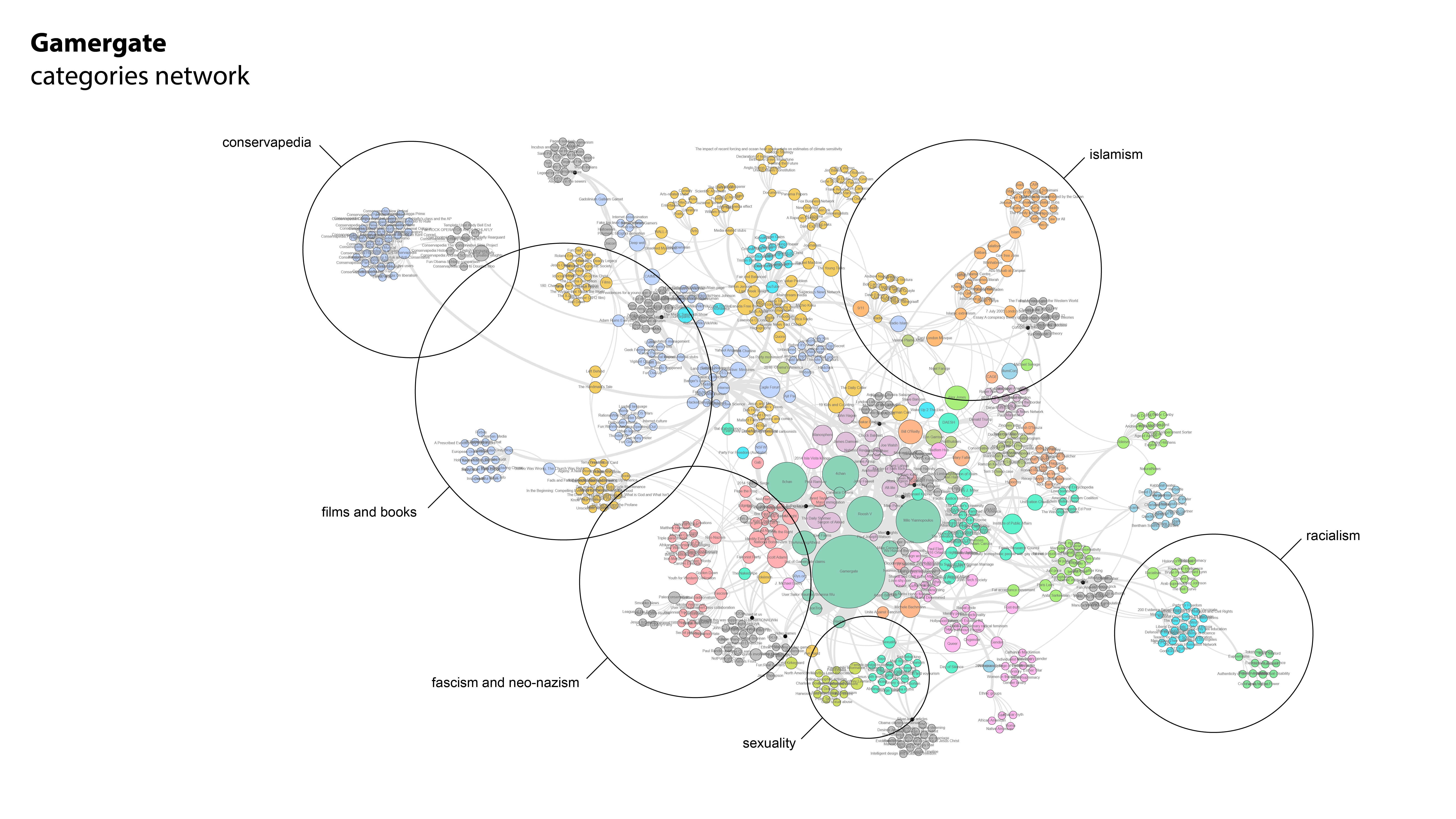
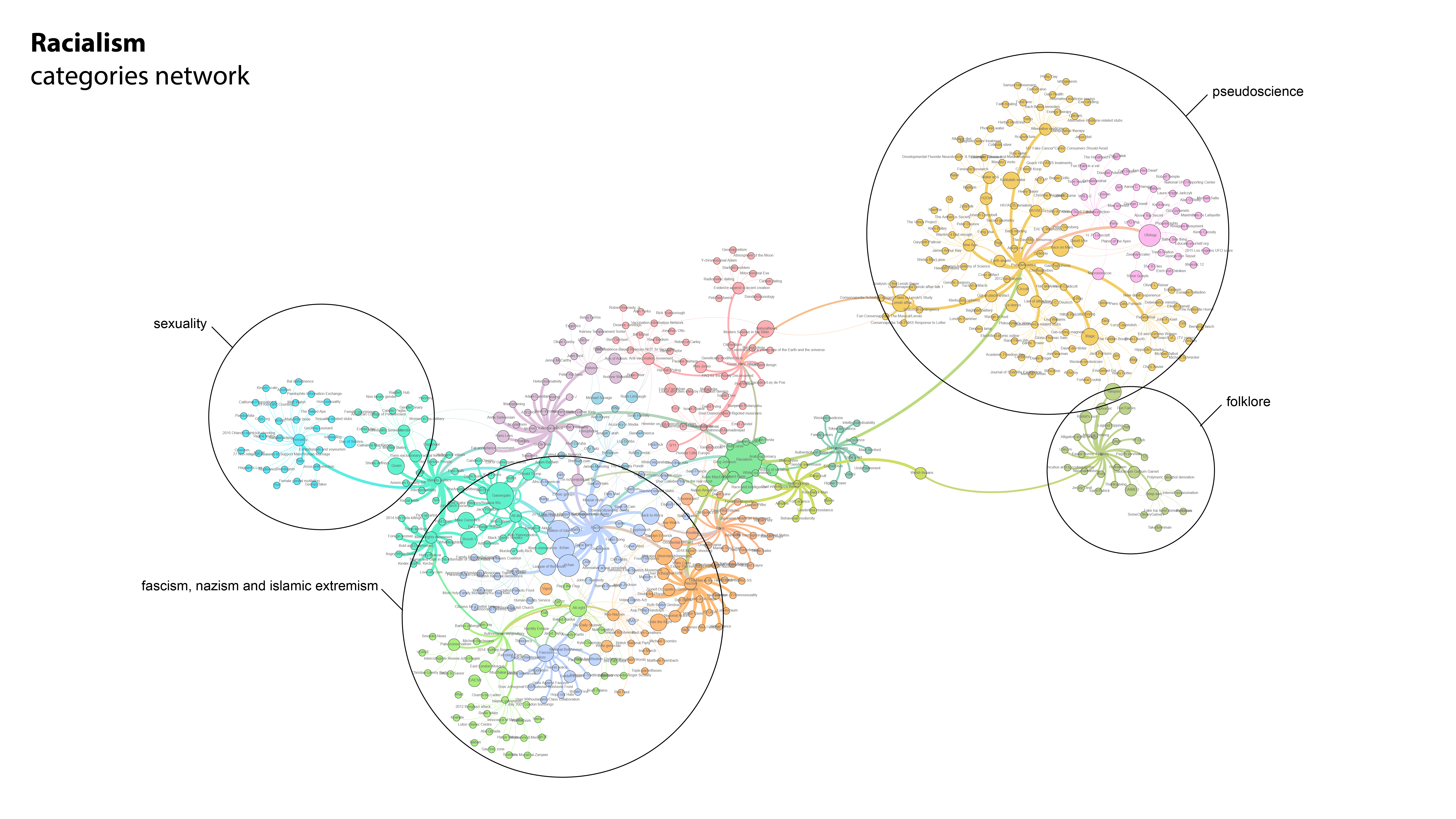
 C) Category network per article
C) Category network per article


8. References
Jason S. Kessler. Scattertext: a Browser-Based Tool for Visualizing how Corpora Differ. ACL System Demonstrations. 2017.
Lyotard, Jean-Francois. 1984. The Postmodern Condition: a Report on Knowledge. Manchester: Manchester University Press.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback