What are coding skills worth in the age of AI?
Team Members
Eva Otto · Andrea Nye · Kristijan Tevcev · Iida Palosuo Poster link: https://surfdrive.surf.nl/files/index.php/s/Kdwkho5CacV6aq1#pdfviewerContents
1. Introduction
In the “back-end” of the digital revolution stands the software engineer. An elusive figure responsible for building our many digital systems and interfaces. Traditionally, coding has been considered a highly specialized and creative skill. With the ubiquity of digitalization, generally developers as a professional group enjoy a position of being in high demand (by companies and organizations), giving a certain privileged position to the “tech wizard”. However, the recent introduction of AI into coding might destabilize the very profession responsible for making AI tools. Recent AI developments in coding, such as co-pilot on Github, are sold as tools – to managers as well as developers - promising to make developers more productive by automating rote work. Other AI-based solutions are integral for “low-“ or “no-code” frameworks, lowering the bar for the technical skills needed to produce technical solutions. Software engineering is considered a creative practice by software developers, based both on skill and “style”, with especially clever hacks and solutions being valued among developers (Bialski 2024, Coleman 2009, 2013, Beltran 2023, Otto et al 2023). Such values are part of larger value and practice frameworks within coding communities, and can be studied from a cultural perspective (Beltran 2023, Breslin 2024, Bialski 2024) With the advent of AI, it seems that established values, norms and practices have been destabilised. And in the debate over what AI means for coding skills, we see different positions being staked out. Using the destabilization that AI has occasioned we can access arguments and values that are normally under the surface, because they do not need to be articulated. An initial scan reveals a beginning divide on whether AI will help or hinder established and new coders. Some critical voices point to AI making developers “dummer”, as AI is accused of shortcutting the trajectory normally needed to go from neophyte to specialist. In other words, new recruits might not “learn the ropes”, and accept bad solutions suggested by AI, leading to overall worse code. Some point to the homogenizing effects on coding by using AI as a bad thing, while others seem to welcome it as a way to increase quality or and AI as a way to democratize coding. As such AI might have an impact on ( a minimum of) two interrelated aspects of software development: the (perceived) quality of codework and the privileged position of the developer. But what other positions are there, are these the salient ones, and which types of reasoning are at play? This project explores how the developer community considers the possible threats and benefits of AI, by taking inspiration from a an issue mapping approach (Marres 2025, Venturini and Munk 2021). By looking at this question, values within the coding community that are normally taken for granted, and thereby unarticulated, also come to the surface. The software development community is manifested through online spaces (Kelty 2008, Otto et al. 2023), and therefore also aptly studied through online platforms. In this project we look at responses to AI in coding in two different platforms in which the introduction of AI is discussed: Tiktok and LinkedIn. Where LinkedIn is a niche space for professional networking, Tiktok is a broader pop culture platform, with a higher traction among younger people. The two platforms show a suprising similarity in the types of concern that arise with the introduction of AI, although they showcase differeing styles in which arguments are made. Focusing on these two platforms allowed us to leverage the possibility of comparison. This gives insights into the affordances that each platform leverages, allowing us to approach the relation between our overall question and its relation to the forums in which we explore it. Lastly in this project we aimed to explore the use of LLM's for qualitative coding. As such the title - coding skills in the age of AI, has a double connotation, also posing the question of how ai can be used to analytically code datasets of qualitative material.2. Research Questions
Overall we ask, how does the coding community (broadly construed) evaluate the use of AI in coding, and what values about coding does it draw on in doing so? This entails the following sub questions for both platforms:- RQ1 Who is engaged in the debate?
- RQ2 what kind of language do actors use, what kind of “concerns” do they refer to?
- RQ3 What kind of values do these concerns link to, how are they being employed and negotiated? Who is considered to benefit, who might lose?
3. Methodology and initial datasets
3.1 Collection
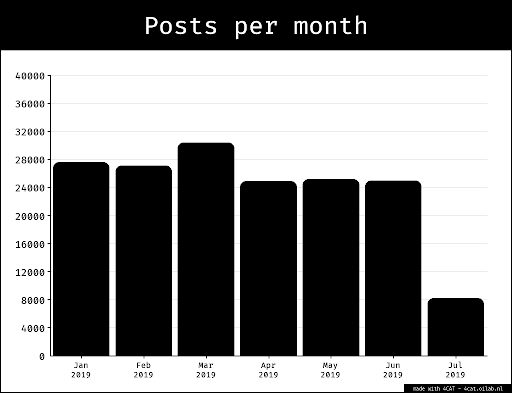
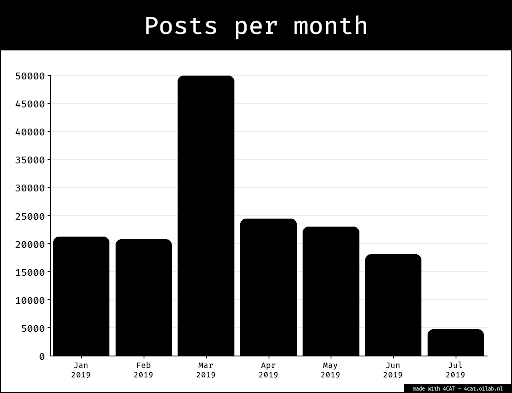
For collecting our datasets we employed a query design that focused narrowly on the posts connected to the keyword "AI Coding". After reviewing LinkedIn and Tiktoks data-structures respectively, we decided that a keyword search would best fit our purposes. We started the sprint by collecting three datasets using the Zeeschuimer tool. LinkedIn: Between three researchers, we started by conducting a focused keyword search on our personal linkedin profiles using the phrase “AI Coding”. We filtered the search to include all posts from the past month (longest time frame that LinkedIn allowed), and chose the sort by feature to be ‘top match’. Each of us scrolled until the end of the page, and we merged the datasets removing 455 duplicates, ending up with 812 entries. TikTok posts: We repeated the process on TikTok, with the exception of using blank-slate profiles instead of personal profiles. We collected posts and comments with the search tool and the same phrase, “AI Coding”. With the TikTok search tool, we had even less visibility to how the posts shown to us were determined. However, we were able to scroll until the end of page on our three profiles, merge the datasets and end up with 425 entries and 444 removed duplicates.The higher proportion of duplicates indicates that there is more limited personalisation at play for the keyword search in tiktok . Tiktik comments: Finally, we also gathered a dataset of TikTok comments, scraping comments from the first 100 posts with the same keyword search on all our profiles. This gave us 15,521 entries, and 7,225 removed duplicates. While it was an interesting collection, and we explored it through different methodologies, due to time-constraints, this data does not feature in our results.3.2 Who is engaged in the debate?
We used the data analysis tool 4cat (Peeters and Hagen 2022) as an integral part of our data analysis. To figure out who is speaking of the theme, we decided to take two actions: extract the ‘top voices’ on each platform to take a closer look at them, and on LinkedIn, where our dataset included self-written author descriptions, to categorize them into more general professions. Starting with the first step, we extracted the 10 posts with the most likes, 10 posts with the most shares and 10 posts with the most comments on each platform, as well as 10 posts with the most plays on TikTok, where this metric was available. With the second step, we used the ‘classify text using large language models’ processor on 4cat to categorize the author descriptions into general professions. We used the google/flan-t5-large model and zero-shot classification style, as the few-shot classification was not operating at the time. We went back and forth between manually checking the accuracy of the classification from a sample of 100 author descriptions and adjusting the categories we gave the model. Eventually giving the categories of ‘executive’, ‘engineer’, ‘creative’, ‘evangelist’, ‘student’, ‘researcher’, ‘no title just followers’, and ‘other’ gave us an 84% accuracy on the classifications, which we were satisfied with for the purposes of this exercise. With more time, we would have explored the few-shot classification method, as well as compared the differences between the two large language models available.3.3 The style of debate on each platform
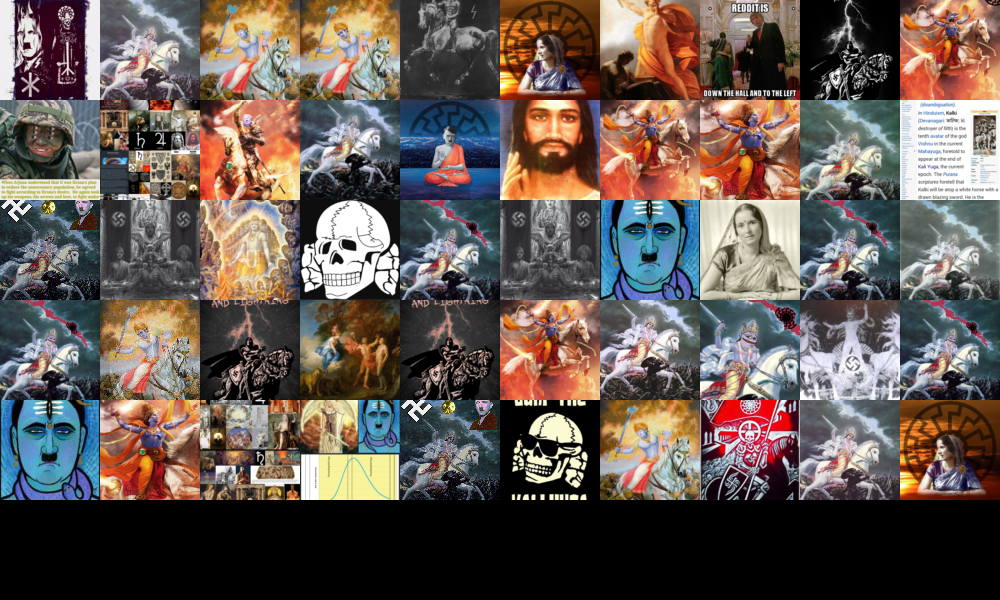
We had most challenges in finding the answers to our qualitative research questions, that required thematic analysis of the textual data. We extracted the top 50 hashtags for each platform using a 4cat processor. This gave us an indication of the different “styles” or “genres” of each platform.We also tried to identify what are the imagery patterns of the two platforms contents. We created the following image wall with 4cat. One intuitive observation is that nearly none of the LinkedIn images used real human faces and human-like robots were a repetitive motif. While on TikTok it is the reverse case, nearly all video cover pages are of a human in a real life setting (office, home, etc.) while robots are rare. This difference can be partially explained by the communication culture difference on the two platforms, which LinkdIn focuses on professional knowledge sharing and TikTok on building followerships through personal connections. Yet this communicative pattern is parallel to the difference we have discovered in the word tree analysis, in the sense that LinkedIn contents addresses more abstractly to businesses, industries, talent pool, labour market transition, etc, while TikTok addresses more at individual level, particularly tapping into the entrepreneurial focus of its viewers and how to make their skillsets more valuable.

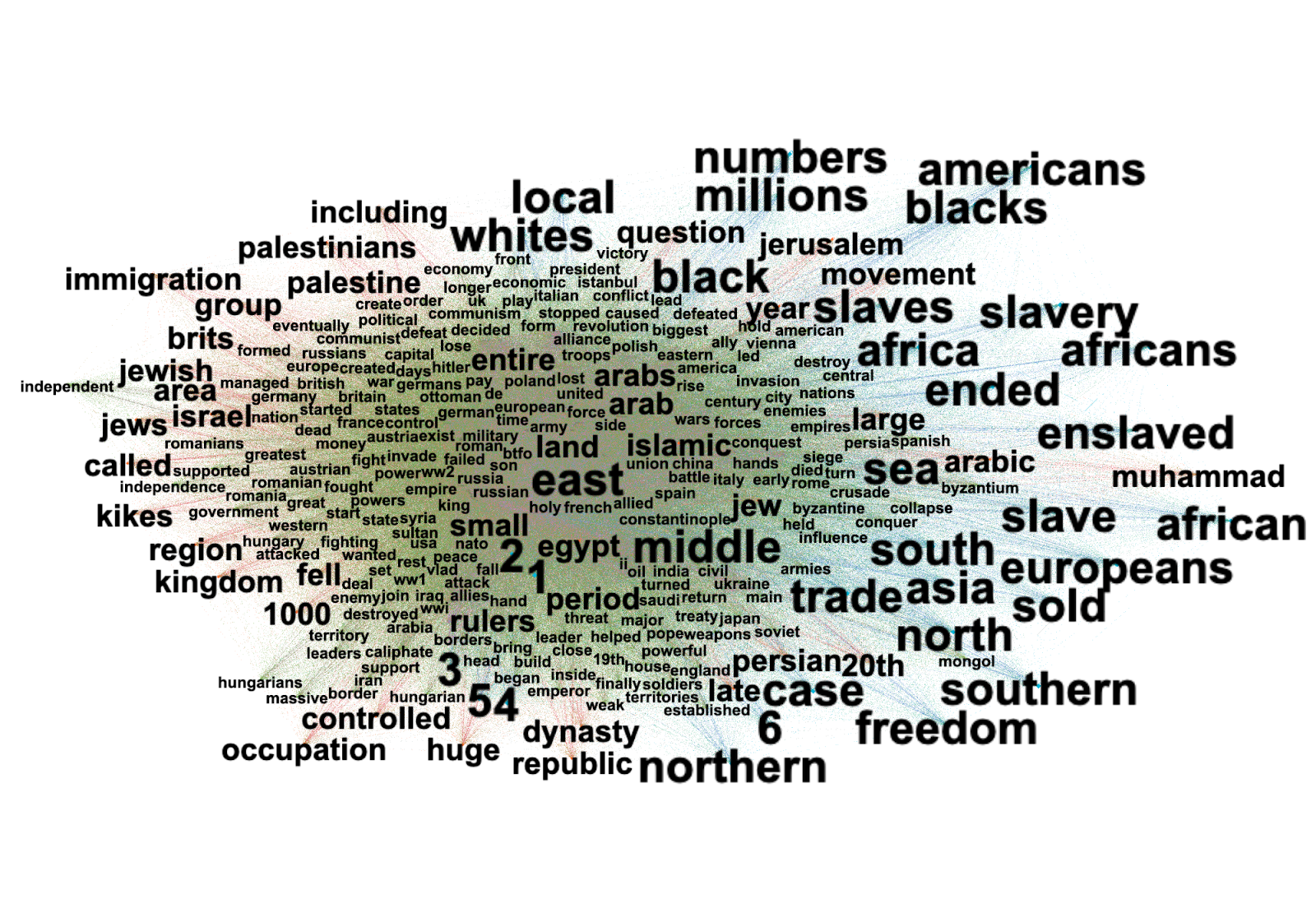
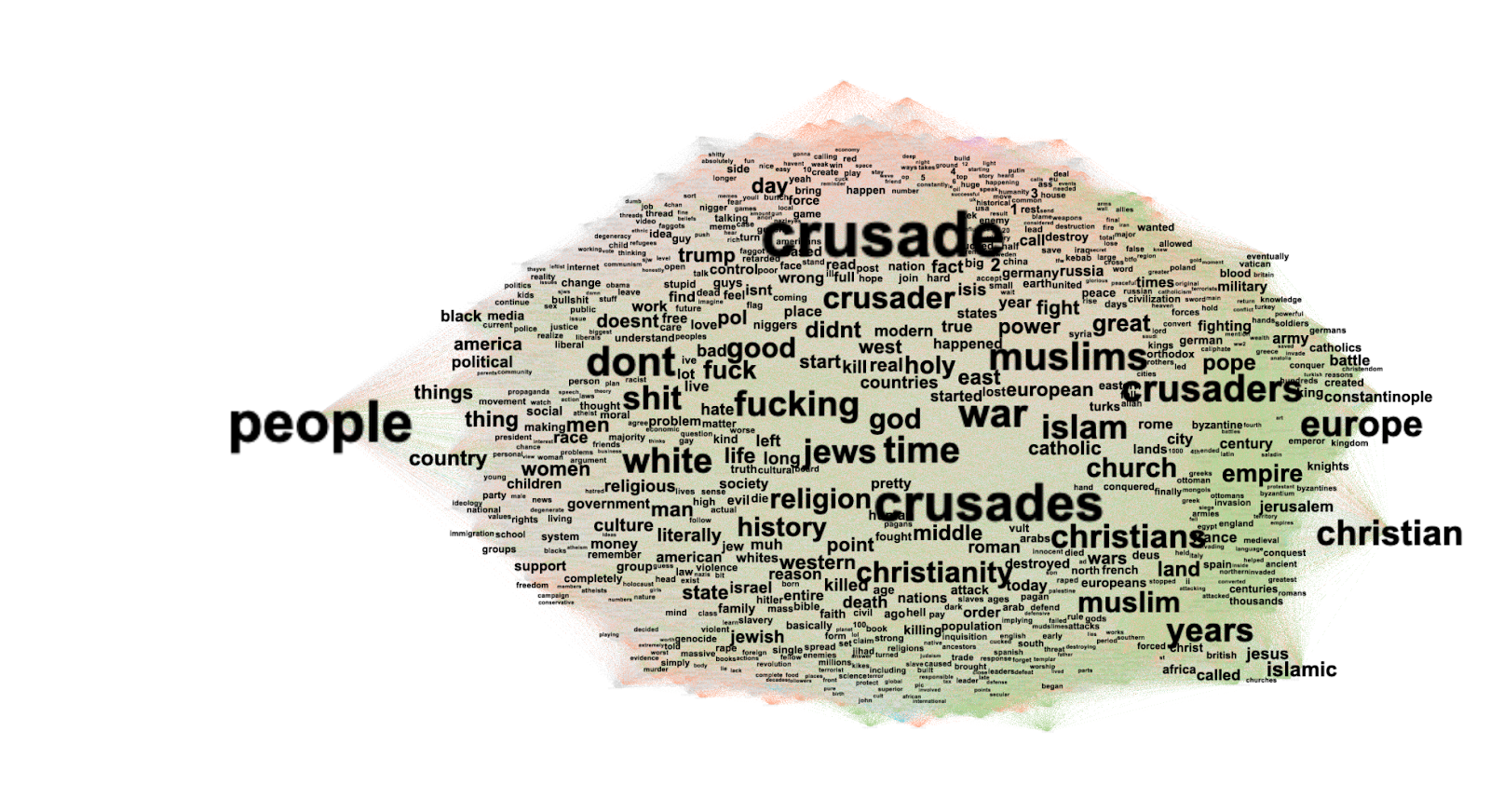
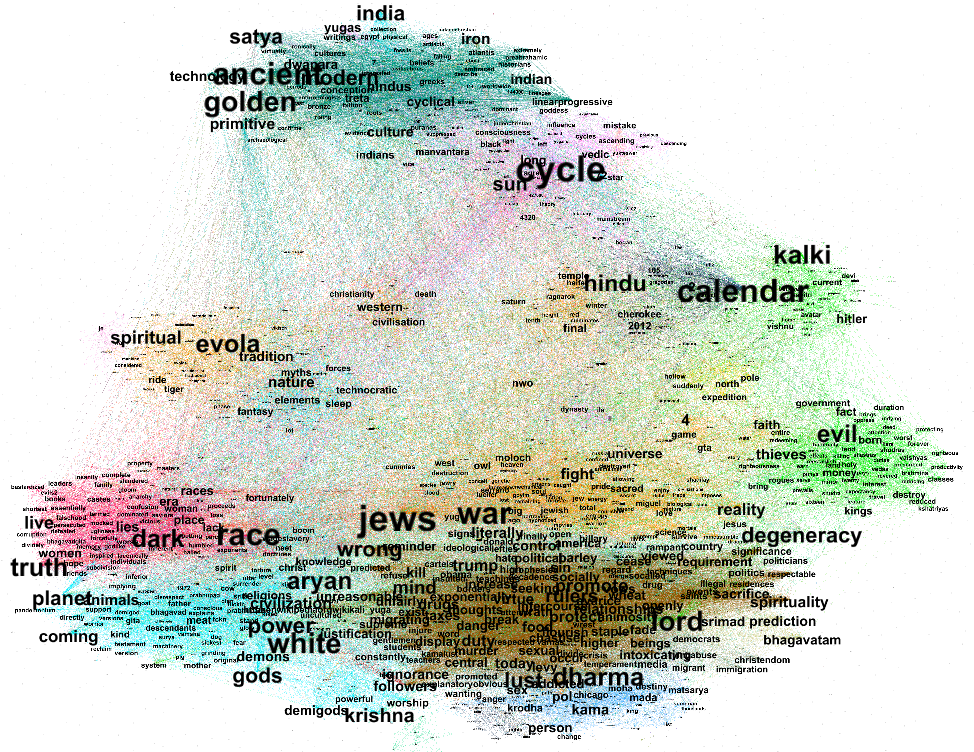
 Another explorative ‘quick and dirty’ approach was to build word trees via neologisms extracted through 4cat. For tiktok the results initially seemed of little analytical value for two reasons: (1) The texts of TikTok comprises a huge amount of hashtags and the majority of neologism was hashtag comprising of two separate words which are not applicable to word trees (2) some keywords identified such as fyp or blackbox appeared for purely platform-specific reasons, for example, #fyp is believed to help the posts to be sent to more users. However, then we identified two groups of common keywords as root words for both LinkedIn and Tiktok. The first group is “future” and “now”, as the researchers have found out by analyzing the data manually (Se below) that the two platforms have different temporal focus. As more LinkedIn posts focus on the mid- to long- time frame impacts of AI-based coding tools and insights on industries, TikTok captions focus more on the present and actionable advice, so we wanted to use the word tree to test this hypothesis. The hypothesis was supported by the number of search results: In LinkedIn posts the “future” word tree search results number was larger than the “now”, while for TikTok it was the reverse.
Another explorative ‘quick and dirty’ approach was to build word trees via neologisms extracted through 4cat. For tiktok the results initially seemed of little analytical value for two reasons: (1) The texts of TikTok comprises a huge amount of hashtags and the majority of neologism was hashtag comprising of two separate words which are not applicable to word trees (2) some keywords identified such as fyp or blackbox appeared for purely platform-specific reasons, for example, #fyp is believed to help the posts to be sent to more users. However, then we identified two groups of common keywords as root words for both LinkedIn and Tiktok. The first group is “future” and “now”, as the researchers have found out by analyzing the data manually (Se below) that the two platforms have different temporal focus. As more LinkedIn posts focus on the mid- to long- time frame impacts of AI-based coding tools and insights on industries, TikTok captions focus more on the present and actionable advice, so we wanted to use the word tree to test this hypothesis. The hypothesis was supported by the number of search results: In LinkedIn posts the “future” word tree search results number was larger than the “now”, while for TikTok it was the reverse.


 The second group of world tree roots we tested were modal verbs “can” “need” “should” “must”. The rationale is that “can” describes an increased capacity or possibility, “need” expresses call to actiona or commercial motives, while should and must invoke a sense or uurgence. Our observation is that the pattern of these 4 verbs in both LinkedIn and TikTok data have been very similar, with “can” posiding a far higher frequency, followed by need, while should and must are not very common. Our interpretation is that it reflects a common communication style of both posting communities when talking out AI and coding online, that the main focus is displacing possibility.
The second group of world tree roots we tested were modal verbs “can” “need” “should” “must”. The rationale is that “can” describes an increased capacity or possibility, “need” expresses call to actiona or commercial motives, while should and must invoke a sense or uurgence. Our observation is that the pattern of these 4 verbs in both LinkedIn and TikTok data have been very similar, with “can” posiding a far higher frequency, followed by need, while should and must are not very common. Our interpretation is that it reflects a common communication style of both posting communities when talking out AI and coding online, that the main focus is displacing possibility.
3.4 exploring LLM approaches:
3.4.1 Open exploration.
We explored a very open discourse analysis using LLMs, focusing on prompt engineering. However with very limited success. Neither giving ChatGPT or Copilot access to the data and engineering the prompts provided useful categorizations or analysis. For example, asking ChatGPT model 4o to perform an explorative discourse analysis on a dataset of 10320 TikTok comments gave us 8895 categorizations as “general comment” (not at all useful) and 14 categorizations as “Criticism or caution” (criticism or caution about what? Not very useful). We spent quite some time trying to develop a prompt, that followed the examples of best practice from prompt-engineering (ref). However, during the multiple tests the LLM’s kept giving random results, indicating that we could not make it go through the data systematically. This was not an unsurprising result, as LLm’s are built according to a predictive rationale (reference here). Our results so far led us to the consideration that the analysing task might have been to complex to describe it clearly. Inspired by Rogers and Zhang (2024), we attempted a more simple classification, trying to see if we could group posts according to sentiments as either positive, negative or neutral towards AI. This however did not seem promising either. More testing might be needed to se if it can potentially be done. But the complexity of different stances towards AI, and the fact that in some posts, both stances and sentiments were present, might also mean that this approach is not the best for our purposes.3.4.2 manually annotating data
In order to create a baseline for machines assisted methods we made a sample set of manually annotated data grouped into themes. We aimed for 40 samples from both Linkedin and TikTok posts and 100 samples from TikTok comments. Due to an unknown technical difficulty with the 4cat random sampling processor, we ended up with a sample of 36 for the LinkedIn comments, a sample of 24 for TikTok posts and a sample of 100 for the TikTok comments. Between three researchers, each of us annotated two of the three sets without seeing the others' annotations, and afterwards we compared and collectively agreed upon the final themes.3.4.3 Few shot classification
Based on these classifications we attempted a few shot classification. The few-shot classification processor on 4cat didn’t give much accuracy with a few examples per class, and we ran out of time to explore it with more examples. A noteworthy observation was that the large language models still showed more promise with the LinkedIn post data compared to the TikTok post or comment data – perhaps due to the LinkedIn posts being longer and more explicit in nature.3.4.4 Using sentences as categories
A second endeavor with 4cat classification with LLMs was using sentences as categories. As the we found out that giving just one word (e.g. transformative) or a phrase (transformative future) could not generate useful results, we attempted to use a whole sentence to describe in contexts the possible substance in the sentence without any presence of comma as the different categories are separated by commas. These category sentences were based on our manual coding. Here are the category-sentences we have used:- Efficient future narrative for people with coding skills: AI-based tools are helping you as a programmer or coder or developer to complete coding tasks more Efficiently and quickly and productively and better in a more streamlined workflow
- Efficient future narrative for people without coding skills: AI-based tools are helping you as a creative professional or entrepreneur or Marketer to complete non-coding tasks more Efficiently and quickly and productively and better in a more streamlined workflow
- Transformed future narrative for people with coding skills: AI-based tools are transforming or fundamentally changing or Revolutionizing or rewriting your industry such as coding or website development or UX design so that you you as a programmer or coder or developer need to use AI-based tools to help you stay in the industry
- Transformed future narrative for people without coding skills: AI-based tools are transforming or fundamentally changing or Revolutionizing or rewriting your industry such as marketing or investment or creativity so that you you as a business leader or a creative professional or entrepreneur or Marketer need to use AI-based tools to help you stay in the industry
- Junior job replacement narrative: AI-based tools are acting like junior professionals in both coding and non-coding tasks so that young people are more likely to be replaced by AI-based tool
- Senior job non-replacement narrative: AI-based tools are not going to replace experienced humans because humans have expertise needed by AI
- Democratization narrative arguing everyone can learn to code: AI-based tools are free and easy so that anyone can learn to code nowadays
- Democratization narrative arguing nobody need to learn to code anymore: AI-based tools are free and easy so that you don’t need to learn coding any more
3.4.5 Using keywords for classification of posts.
We then tried a third approach, which is using ChatGPT generated keywords with 4cat filtered keywords. The rationale for this approach is to test whether GPT can perform well in extracting keywords based on their textual properties (i.e. which substantial words are more likely to appear together) instead of their connotations. The result is that some of the keywords generated in different themes were the same or could be categorized into both. The final classification is based on 4cat filtered keywords. The keywords combines two types: (1) ChatGPT is asked to identify the top 5 most frequently used keywords in the categories researchers have identified. Researchers then asked ChatGPT to check whether these words have actually appearewd in the posts dataset to avoid hylucianation; (2) These GPT generated keywords are then supplement by manually identified keywords, including both the keywords ignored by GPT and the same word root in different form (e.g. transform, transformative, transforming) as the filtered keywords cannot identify them if not all listed.3.4.6 Future potentials
As the we explored TikTok comments data, it became clear that this part of the dataset had to be shelved due to the time limit of the project. Another reason being the comments are more directly linked to the post or the content creators themselves, instead of the thematic focus. For future research it would be promising to conduct sentimental analysis on thecomments to understand whether a certain type of posts are more likely to generate positive or negative sentiments. In this regard many comments are composed purely of emojis, so a potential method is to use ChatGPT to catogorise them, reason being (1) emojis are much less complex grammatically than written languages (2) interpretation of emojis are highly dynamic as the any of the online language practices, so that GPT might outperform humans as it is updated with new language practices.4. Findings
4.1 Who is engaged in the debate?
We approached the first question on two ways. Using LinkedIns platform affordances, we we found the types of proffesions posting on the topic AI coding. Afterwards, for both platforms we explored the relative distributions of popularity for the topic AI coding, finding that a smaller set of posters, were responsible for a large amount of likes, posts and views.4.1.1 Proffesional categories on Linkedin
We could see that most of the people posting about AI and coding were engineers (n=370), the second largest group was executives (n=170) and third largest group were “evangelists” (n=85)
4.1.2 The winner takes it all
When looking closer at the 10 most engaged with posts in the dataset, we could see something that could be interpreted as the “winner takes it all” distribution of likes: the most liked post had 4156 likes, the fourth most liked post had 1657 likes, and the 10th most liked post had only 713 likes. Looking at the whole dataset, the mean for likes is 70 and median 7. This indicates that only a few posts about AI and coding get a lot of traction. However, based on the limited data, we cannot say whether this tells us something about the popularity of the individual posts that happened to be in the dataset by chance, or whether it tells something about how the algorithms of the platform are giving visibility to certain posters over others. Another observation about the top 10 posts on Linkedin is that the distribution of professions is reflected very well in the posts: four of the posts were authored by an engineer, two by an executive, two by an “evangelist”, one by a creative, and of one, we don’t have data. The top five were almost all engineers, excluding one executive in third place. Looking at the TikTok posts, we can again see the same phenomenon, where a small number of ‘topic influencers’ have a significantly higher proportion of engagement than the main body.

4.2 dominant concerns within each platform
Through manual annotation, we were able to identify 8 narratives across the LinkedIn and Tiktok posts. These are labelled (1) efficient future narrative, (2) transformed future narrative, (3) democratization narrative, (4) (junior) job replacement narrative, (5) expertism narrative, (6) job security narrative, (7) financial theme, and (8) ethical concerns. Below we describe the different narratives and the keywords we used for analysing posts, in our combined machine and manual methodology (see methodology section) We used a bipartite network between the narraitves and posts, to illustrate the relative prevalence of different narratives. Out of the 8 narratives, 1-4 were discussed on both of the platforms, whereas themes 5 and 6 were native to LinkedIn and themes 7 and 8 native to TikTok. The most prominent narratives on LinkedIn were 1-3 and on TikTok 1, 3, 4 and 7. (See figure for colour-coded categorization that relates to the networks below)
We found that on LinkedIn, the most prominent narrative regarding coding and AI is that the AI transformation is going to make the work of developers and other professionals more efficient. However, another prominent narrative is that AI is going to fundamentally transform the whole production mode of all professionals, including coders, so that incorporating AI into the workflow is not just a matter of efficiency but survival in the changed future. We could also locate two, perhaps even opposing narratives – a large number of the posts discuss AI using the democratization narrative, where AI tools are seen as empowering people with less skills in excelling in their own field or breaking down barriers of entry to other fields. However, there’s a smaller but significant number of posts discussing the expertism narrative, where AI-based tools are seen as prone to preserving the relative power relations in industry and workplaces, where coders / managers / business leaders with more expertise and knowledge benefit more and beginners might even be harmed.
We used a bipartite network between the narraitves and posts, to illustrate the relative prevalence of different narratives. Out of the 8 narratives, 1-4 were discussed on both of the platforms, whereas themes 5 and 6 were native to LinkedIn and themes 7 and 8 native to TikTok. The most prominent narratives on LinkedIn were 1-3 and on TikTok 1, 3, 4 and 7. (See figure for colour-coded categorization that relates to the networks below)
We found that on LinkedIn, the most prominent narrative regarding coding and AI is that the AI transformation is going to make the work of developers and other professionals more efficient. However, another prominent narrative is that AI is going to fundamentally transform the whole production mode of all professionals, including coders, so that incorporating AI into the workflow is not just a matter of efficiency but survival in the changed future. We could also locate two, perhaps even opposing narratives – a large number of the posts discuss AI using the democratization narrative, where AI tools are seen as empowering people with less skills in excelling in their own field or breaking down barriers of entry to other fields. However, there’s a smaller but significant number of posts discussing the expertism narrative, where AI-based tools are seen as prone to preserving the relative power relations in industry and workplaces, where coders / managers / business leaders with more expertise and knowledge benefit more and beginners might even be harmed.
 On TikTok, we can see that the themes of democratization and efficient future are prominent too. The transformed future narrative is not as discussed as on LinkedIn. Instead the TikTok posts often included themes of job replacement narrative, where people express concern for AI replacing especially entry-level jobs. The same narrative is present on LinkedIn as well, just not as prominently.
On TikTok, we can see that the themes of democratization and efficient future are prominent too. The transformed future narrative is not as discussed as on LinkedIn. Instead the TikTok posts often included themes of job replacement narrative, where people express concern for AI replacing especially entry-level jobs. The same narrative is present on LinkedIn as well, just not as prominently.
 We purposefully employed a methodology that allowed one post to be part of more than one narrative, as we saw during out initial analysis that posts could contain several narratives about AI.This also meant there are particular narratives that have a heavy overlap within posts. Below we see an example of how the two most popular themes on tiktok overlap. The diagram illustrates how about a third fo the posts that fall into the efficient futures narrative, also fall into the democratization narrative.
We purposefully employed a methodology that allowed one post to be part of more than one narrative, as we saw during out initial analysis that posts could contain several narratives about AI.This also meant there are particular narratives that have a heavy overlap within posts. Below we see an example of how the two most popular themes on tiktok overlap. The diagram illustrates how about a third fo the posts that fall into the efficient futures narrative, also fall into the democratization narrative.

4.3 methdological findings
A methodological finding concerns the reliability of our approach. The relative number of posts labeled for “efficient future” and “transformed future” have been stable across the three methods, while the other them are more volatile across labelling methods. Our hypothesis is that “efficient future” and “transformed future” are the most dominant discourses so their identification is of little nuance. As some other themes like democratisation or expertism have connotations overlapping with “efficient future” or “transformed future,” so that when we exclude the keywords or sentence meaning used in these two future categories, the margin of democratisation or expertism definition becomes not easy to define.
4.4 Limitations
It is important to note, that still through the keyword search process, a large number of posts were not annotated to include any of the themes. For the LinkedIn posts, 135 out of 812 entries, and for the TikTok posts, as many as 415 out of 458 entries were not categorized to any of the themes. Given further time, an improved annotation process, and deeper exploration of this would be necessary.5. Discussion
Our research explored how AI’s influence on coding is perceived across different social media platforms, specifically LinkedIN and TikTok, highlighting the unique dialogues shaped by each platform’s distinct audience. On LinkedIn, the discourse primarily resolves around the efficiencies and future potential that AI can introduce to professional workflows, emphasising the necessity for professionals to integrate AI to remain relevant and competitive. This conversation suggests a strategic, long-term view of AI as an essential tool for enhancing productivity and advocating careers. TikTok 's discussions are more immediate and practical, focusing on the accessibility of coding skills and the potential job displacement caused by AI. The platform's younger demographic engages with AI from what we categorize as a democratization perspective, viewing it as a tool that can either lower barriers to entering the tech industry or pose risks to job security, particularly for those in entry-level positions. Both platforms also grapple with the tension between democratization and expertism. LinkedIn 's professional base expresses concerns that while AI might democratize coding, it could also entrench existing hierarchies within the tech world. Seasoned professionals might use AI to enhance their dominance, potentially marginalizing novices. TikTok 's narrative, while similar, places greater emphasis on the immediate risks AI poses to job security rather than its potential to reshape professional hierarchies. As such the future of the labour of coding (Parikka 2014) is differently framed according to the relation drawn between the importance of expertise and AI. These platform-specific conversations underscore a broader cultural and generational divide in perceptions of AI’s role in coding, reflecting how public perception and acceptance of AI technologies are heavily influenced by the media through which people engage with these topics.6. Conclusions
Our research explored AI's impact on coding across LinkedIn and TikTok, revealing distinct dialogues shaped by each platform's audience. LinkedIn discussions focus on AI's efficiencies and future potential in professional workflows, emphasizing the need for integration to stay competitive. TikTok 's conversations center on the accessibility of coding skills and potential job displacement, with a younger demographic viewing AI as both an opportunity and a threat. Both platforms address the tension between democratization and expertism, with LinkedIn professionals concerned about reinforcing hierarchies and TikTok users worried about immediate job security risks. These conversations highlight a cultural and generational divide in perceptions of AI’s role in coding, influenced by the media through which people engage with these topics. Policy and Educational Adjustments: The insights gained could inform targeted adjustments in technology education and policy-making. By understanding the specific concerns and hopes of different demographic groups, educators and policymakers can develop initiatives that address these needs, making technology more accessible and its benefits more equitable. Future Research Directions:- Cross-Demographic Studies: Further research could explore how AI-related discussions vary across other demographic markers such as age, professional experience, and educational background within and across different platforms. This would provide a richer understanding of the multifaceted perceptions of AI.
- Longitudinal Analysis: Investigating how perceptions of AI in coding evolve over time as technology advances and becomes more integrated into daily practices would be valuable. This could help track shifts in public opinion and identify emerging concerns or hopes regarding AI.
- Comparative Platform Studies: Expanding the study to include other platforms like GitHub or Stack Overflow could offer insights into how professional coders versus hobbyists or students perceive AI. Such studies could also examine how professional discourse differs from casual or educational discussions about AI.
- Impact of AI on Educational Pathways: Researching how AI tools are changing the educational pathways for aspiring coders and developers could provide valuable insights. This includes the role of AI in educational curricula and its impact on the skills that educators emphasize as critical for future professionals.
7. Data Sets
LinkedIn merged dataset of all posts: https://4cat.digitalmethods.net/results/6020238f2a2f63d7b73bef21a0a8c26c/ TikTok merged dataset of all posts: https://4cat.digitalmethods.net/results/71cef1aac3d8e9af1d43de854caaa4e4/ TikTok merged dataset of all comments: https://4cat.digitalmethods.net/results/52125ad4c78817a2133d85d6df294dae/8. References
Venturini, Tommaso, and Anders Kristian Munk. Controversy mapping: A field guide. John Wiley & Sons, 2021.
Marres, Noortje. "Why map issues? On controversy analysis as a digital method." Science, Technology, & Human Values 40.5 (2015): 655-686. Why Map Issues? On Controversy Analysis as a Digital Method
Beltrán, Héctor. “Code work: Thinking with the system in México”. American Anthropologist 122, nr. 3 (2020): 487–500.
Bialski, Paula. Middle Tech: Software Work and the Culture of Good Enough. Princeton, UNITED STATES: Princeton University Press, 2024. http://ebookcentral.proquest.com/lib/kbdk/detail.action?docID=30966054.
Breslin, Samantha Dawn. “Computing trust: on writing ‘good’ code in computer science education”. Journal of Cultural Economy 17, nr. 6 (2024): 737–56. https://doi.org/10.1080/17530350.2023.2258887.
Beltrán, Héctor, Code Work, Princeton University Press, 14. november 2023. https://press.princeton.edu/books/hardcover/9780691245034/code-work.
Coleman, Gabriella. “CODE IS SPEECH: Legal Tinkering, Expertise, and Protest among Free and Open Source Software Developers”. Cultural Anthropology 24, nr. 3 (2009): 420–54. https://doi.org/10.1111/j.1548-1360.2009.01036.x.
Coleman, E. Gabriella. Coding freedom: The ethics and aesthetics of hacking. Princeton University Press, 2013.
De Souza, Cleidson, Jon Froehlich, og Paul Dourish. “Seeking the source: software source code as a social and technical artifact”. I Proceedings of the 2005 international ACM SIGGROUP conference on Supporting group work, 197–206, 2005.
Kelty, Christopher. “Geeks, Social Imaginaries, and Recursive Publics”. Cultural Anthropology 20, nr. 2 (2005): 185–214.
Otto, Eva Iris, Jonathan Holm Salka, og Anders Blok. “How app companies use GitHub: on modes of valuation in the digital attention economy”. Journal of Cultural Economy 16, nr. 2 (4. marts 2023): 242–59. https://doi.org/10.1080/17530350.2023.2186916.Parikka, Jussi. “Cultural Techniques of Cognitive Capitalism: Metaprogramming and the Labour of Code”. Cultural Studies Review 20, nr. 1 (19. marts 2014). https://doi.org/10.5130/csr.v20i1.3831.
Peeters, Stijn, og Sal Hagen. “The 4CAT Capture and Analysis Toolkit: A Modular Tool for Transparent and Traceable Social Media Research”. SSRN Scholarly Paper. Rochester, NY: Social Science Research Network, 28. september 2022. https://doi.org/10.2139/ssrn.3914892. Rogers, Richard, and Xiaoke Zhang. "The Russia–Ukraine War in Chinese Social Media: LLM Analysis Yields a Bias Toward Neutrality." Social Media+ Society 10.2 (2024): 20563051241254379.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback