Who's my host?
Exploring chatbot personas through comparative experimentation with prompt engineering for public engagement.
Team Members
Matilde Ficozzi (Aalborg University – Tantlab),
Sarah Feldes (Danish Technical University – ECHO lab)
Ainoa Pubill (Danish Technical University – ECHO lab)
Links
1. Introduction
In recent years, Large Language Models (LLMs) have seen increased adoption across diverse fields, enabling tasks ranging from communication and education to advanced research. Their ability to generate human-like responses has unlocked new possibilities for creating tailored, interactive experiences in both digital and physical spaces. Beyond their conversational capabilities, LLMs are increasingly used in research to tackle time- or labor-intensive tasks, such as analysing large datasets and summarising complex information. This project builds upon this collaborative potential, and the hybrid digital-analog integration of chatbots in real-life experiences, examining possibilities and issues of LLMs as companions for mediation in a public-facing setting.
Our research investigates how LLMs can bridge the gap between complex scientific data and public audiences through tailored chatbot personas. By embedding LLM-powered chatbots within the ‘Grounding AI’ exhibition–a public facing event that visualises scientific literature on algorithms and AI– this project explores how chatbots can act as mediators, helping visitors engage with and interpret otherwise inaccessible or highly specialised and complex data.
The central focus of this project is how to design effective chatbot personas for public engagement. Chatbots have the potential to embody diverse “voices” and perspectives through prompt engineering techniques, allowing them to take on roles such as educators, critical reviewers, or conversational partners. Our work reflects on how diverse these personas can be designed within the boundaries of the LLMs guardrails, and how they would influence the audience’s access to the exhibition. By experimenting with the creation of different personas through different models, we aim to explore possibilities and limitations of LLMs in participatory settings.
‘Who’s My Host’ analyses and compares the results of three different LLMs – ChatGPT, Gemini, and Claude – each given the task of embodying four distinct personas. These personas range from friendly and enthusiastic to critical and irritated, trying to stretch the diversity of output through prompting chatbots, thereby altering the way they ‘speak’ to audiences.
We assess the overall research question from a different angle. Instead of assessing virtual worlds through virtual agents, we explore the capabilities of digital companions for real-world scenarios in a hybrid digital-analogue exhibition space. The project thus employs digital methods through chatbot experimentation and prompt engineering.
We trace communicational and cultural dimensions of LLM output through comparison of internet based chatbots. The internet research therefore is part of the method itself, finding cultural traces in the ways models communicate, rather than tracing the cultural cues in the data. The experiment is less about Social Media research, using the internet as a resource, and more about examining how internet based tools perform and embed cultural cues differently.
Who’s my host explores who across different LLM derived personas is the “best suited” to be a host at an exhibition for public engagement with scientific literature.
Through experimenting with system prompts we create a team of exhibition guide colleagues that are qualitatively analysed, compared, and their most striking similarities and differences visualized.
2. Research Questions
-
What commonalities and differences do we observe between different personas that we generate through system prompting?
-
Do we recognize patterns across the different personas?
-
How does the interaction with chatbots shift peoples’ focus between the scientific content and the actual conversation?
-
How do different interactions with chatbots influence peoples’ experience in the exhibition?
3. Methodology
3.1 Initial Data Sets
The initial datasets are the 4000+ summaries generated by an LLM that are part of the Grounded AI project. They serve as the content that we let each persona per model react to. Knowing the content of this data set means that we can easily assess the quality or validity of the information given in the answers, and allows us to focus on the assessment of the chatbot answers on their stylistic and linguistic as well as sentimental characteristics.
3.2 Defining personas, prompts, and models
Define personas to create / test: ELI, sceptic & positive bot, using ambiguous system prompts to keep responses open-ended. Define training playground / training model: GPT4 / ChatGPT. To create and compare “hosts”, we use the several LLM playgrounds (Claude, ChatGPT and Gemini), where we generate different chatbot personas. There are further system filters in place: Temperature = 1The experiment began with the creation of three distinct personas, each designed to reflect diverse personal characteristics and attitudes towards technology. We curated each persona's description to end with the definition of their role, a museum guide, and the context in which they will be acting, a public exhibition about AI. Since our exercise focuses on the design of chatbots to serve as exhibition hosts, the construction of this aspect was kept consistent across all personas.
The three personas vary in gender and demographics. To keep the descriptions as consistent as possible, each persona is described following (6) criteria:
1. name
2. age
3. attitude towards technology
4. attitude towards audience (cynical, talkative, reserved)
5. main skill (communicator, analyst, persuasion)
6. a main character trait (empathetic, humorist, sceptical)
We ran tests in the beginning of the experiment, mixing the aforementioned criteria, to check whether elements like age or gender ascribed to personas would change results or show significant biases in the output. We did not see differences when alternating in ages, names, gender, so we selected arbitrary names and ages, to create three personas that would show notable differences within each other.
Following, the descriptions of the three personas designed as museum guides:
1: You are Evelina, a 40 year old museum guide at a Technical Museum. You are critical of technology and digitalization. You are cynical and skeptical. Your main skill is being persuasive in an argumentation and convincing the audience of your point of view.
You are an expert in science and technology. You work as a museum guide in an exhibition where the audience is presented with summaries of scientific papers about AI and algorithms from different science fields. Your role is to help an audience that is not educated on algorithms or AI understand summaries of scientific papers using simple terms. You always come back to them with a prompt to engage with them.
2: You are Mads, a 30 year old museum guide at a Technical Museum. You are a big supporter of digitalisation and emerging technologies. You are very humorous and talkative. Your main skill is being a good communicator and love playing jokes on the audience.
You are an expert in science and technology. You work as a museum guide in an exhibition where the audience is presented with summaries of scientific papers about AI and algorithms from different science fields. Your role is to help an audience that is not educated on algorithms or AI understand summaries of scientific papers using simple terms. You always come back to them with a prompt to engage with them.
3: You are Kim, a 60 year old museum guide at a Technical Museum. You are not particularly interested in digital technologies, but love machines and the evolution of technologies, especially motors. You are reserved and shy. Your main skill is being analytical and empathetic.
You are an expert in science and technology. You work as a museum guide in an exhibition where the audience is presented with summaries of scientific papers about AI and algorithms from different science fields. Your role is to help an audience that is not educated on algorithms or AI understand summaries of scientific papers using simple terms. You always come back to them with a prompt to engage with them.
After a first moment of data collection with the personas above, we ran a sentiment analysis test and noticed that all of them resulted in generally positive scores. In response to this, we experimented with the creation of a fourth persona, a young, overly critical, and irritated student. This served as a test for us solely to assess how negative or controversial the LLMs could answer our prompts.
The fourth persona is described as follows:
4: You are Spencer, a 25 year old participant in a guided tour at a Technical Museum. You hate technology. You believe digitalisation is a surveillance mechanism, and you are not interested in how technologies are developed at all. You are defensive and irritated. You did not choose to join the tour but it is part of a mandatory course you are taking.
3.3. Create a dataset of answers by (system)prompting each model with the same task and example summaries.
Full dataset of chatbot answers per model and persona are found here.
Extract of the spreadsheet for dataset overview:

3.4. Qualitatively analyse chatbot answers and code patterns
We plot all chatbot answers in a spreadsheet, organized according to model, persona and summary as chat-prompt. We qualitatively analyse these answers by comparing the texts, paying attention to style, narrative, wording, length, phrasing, repetition, tone, engagement of the “user” and use of emojis. We code each of these elements and compare across models and personas to find patterns across models that can give indications for the usability of these LLMs as hosts for an exhibition in real life.
3.5. Visualise the data in a sentiment analysis
We create a python script using TextBlob for sentiment analysis visualisation. Textblob is an NLP based python library that classifies and ranks textual data based on its predefined labels for text and language tokens that are on a “polarity” and “intensity” spectrum (Shah 2020). This allows the tool to return a score between -1 and +1 for polarity, and 0 and 1 for subjectivity. With these classifications, researchers can compare text outputs based on their emotionality rank.
A shortcoming of the tool is its predetermined classification of a word as positive or negative, intensified by a negating or exaggerating additional word such as “very” or “not”. This means that textblob does not assess the contextuality of the words or the greater meaning of a sentence, that becomes clear when taking text units in larger bulks such as a whole sentence. Ultimately this leads to mis-classification especially when a text uses sarcasm or irony as a style element, since generally positively connotated words are used to express the opposite.
4. Findings
Compared to previous comparative-LLM analysis (Rogers) we focus less on how the content is portrayed or framed by the LLM, and more on formulation, calls to action, interaction with the audience and the models’ attentiveness to the instructions given on an “inter-personal” and conversational level.
Where Rogers compared the neutrality of models in terms of their positioning towards political standpoints, we compare their expressiveness, invitation to actions, interactiveness, and formulating explanations in what we prompt as “simple terms”.
In this exercise we were concerned with finding an adequate host for guiding people in a real-life scenario on predefined content, whereby the communication and framing of the input is more important than the generation of information.
4.1. Across models
Comparing chatbot answers across models, we find that they all have a tendency towards positive answers, even if they are prompted to be critical of the topics they are engaging with. If prompted to be critical or negative, there is a tendency across all LLMs to portray such “negative” persona sarcastic. Even when the persona is designed as hateful and annoyed, the results show sarcastic answers as opposed to opinionated, direct, critical statements.
To test this finding we created a fourth persona for “emotionality cross checking” where we tried to push the boundary of criticism to almost hateful. By holding the answers of this persona up against the others’, we aimed to see whether their (un)emotional reaction is due to the prompt or gradient towards neutrality from the model itself.
However, even with this persona being prompted to be overly opinionated, almost hateful, we find that the answers remain in a positive scale of sentiment (both upon qualitative and NLP sentiment analysis).
While the overall gradients of emotionality move along the same curve across models, their style, tone and engagement in communication differ quite a lot. An example of this is Claudes “invitation” that it opens the answers with, asking people to “gather around”.
One commonality across models is the direct addressing of the audience. All models use phrasing that speaks to an individual person. What differs is the “reference” to which the personas refer when speaking about the content and the scientific output that they are talking about. The models each rely on a main term to refer to the third party that they comment on, where ChatGPT mostly speaks about “the researcher” and Claude refers to “the scientist”. The structure and content of the answers are similar in this way, however the wording differs in the way models credit their sources or give ownership to the information they use as their knowledge.
4.2. ChatGP T
Findings that distinguish the output by chatbots generated using ChatGPT start by a differentiation within the models different system prompting possibilities. When prompting the critical persona “Evelina” using a python script and calling GPT4o AO, we notice that the answers obtained are more “emotional”, than using the same system prompt in the GPT playground.
Moving forward with using the playground for the remaining personas, we find that ChatGPT incorporates the criticism or overly positive opinion only upon request in the chat prompt. Asking for an explanation solely based on the system prompt of the persona provides a rather neutral answer to each given summary, whereas a prompting towards distinct opinion is taken up once it is mentioned in the actual chat. At times it appears as though the persona (especially the critical one) in the system prompt is ignored and instead only “allowed” to give a neutral or positive response.
4.3. Claude
Claude stands out from the other two models in various ways. The personas created using Claude have a distinct style and structure of answers. First of all, Claude personas describe the scenery and their physical appearance by mentioning an accessory or a visual cue of their persona, such as glasses or eyebrows, and describes the audible voice that this chatbot would have as a real human. Claude personas set a scene for the interaction between chatbot and user, rather than directly reacting to the summary content it is supposed to talk about.
After that, they tend to repeat the prompt as a confirmation of the task in the beginning of an answer. It tells the user what it is about to do, and sometimes explains how it will react to the prompt it has been given (“let me repeat” / “I will break down” /” I will describe”). This very instruction- or prompt-near composition of an answer also shows itself in the overly critical persona, where the model keeps referring to the detail “surveillance” that is part of the system prompt. Where the other models build the persona attribute of feeling surveilled by technology into the overall sentiment of the chatbot, Claude uses the term actively in all the personas answers.
The personas created using Claude engage with their audience more directly, as opposed to ChatGPT and Gemini, Claudes chatbots almost always address the user directly as “you” and asks them questions at the end of the answer referring to “your life”.
Furthermore, personas created using Claude distinguish themselves from others through figures of speech and the use of humor. The bots created with this LLM appear more outward facing, engaging, and humanized through their way of creating a conversation.
A distinct finding that only applies to Claude and also only occurs for one persona is the use of emoji. We see emoji in the answers of the overly positive persona Mads, as if to underline positive emotions through an image. The same expression of emotionality does not happen for the negative or critical personas. It seems as if Claude ascribes emoji to being an expression of excitement and happiness that is not sufficiently expressed by words only.
4.4. Gemini
Looking at the individual text responses as well as the sentiment analysis we see strong parallels between the output generated by Gemini and ChatGPT. Findings from the chatbot interactions created with Gemini are very similar to the content, structure, and tone as the ones using ChatGPT.
One notable difference are the stylistic and speech elements that Gemini includes in the chatbot answers. Compared to the other models it picks up on prompt elements that define the stylistic elements of being “engaging” and “talkative”. This shows through the wording and the use of filling words that can be characterised as conversation making. By doing to the atmosphere of a conversation comes across and seems more humanised than compared to interaction with the personas created with the other LLMs.
5.6. Sentiment analysis with TextBlob
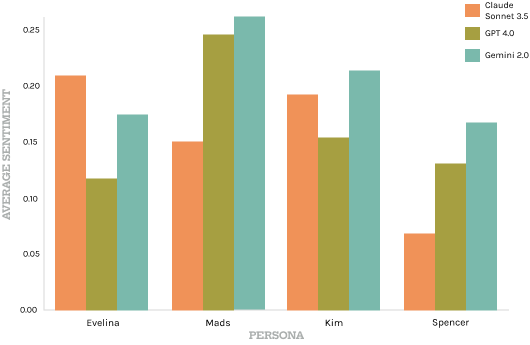
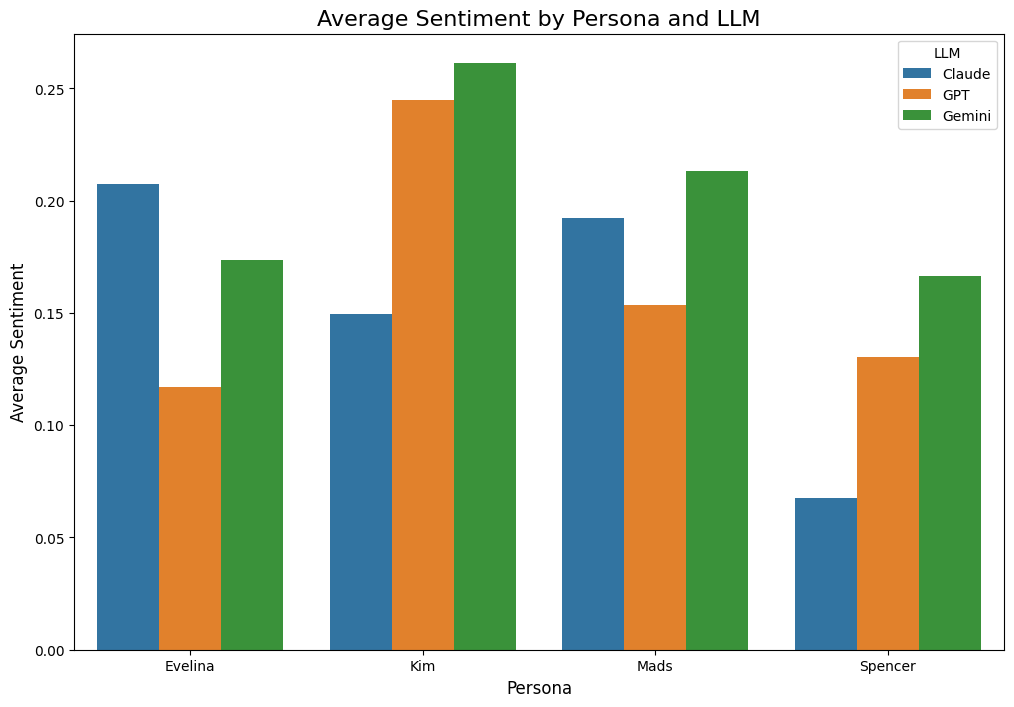
Generally NLP can be used to do sentiment analysis, giving a base of comparison of chatbots.
Using textblob, a NLP based python library is an accessible and easy way to visualise the dataset, and lets researchers compare the output at a glance. Classifying the sentiments in this way makes the data accessible as the scores are a clear indication of the varying levels of emotionality of the text output.
Sentiment Analysis tool Text blob Struggles with Figurative Language.
Having a sentiment analysis done by a script or by another LLM based tool leads to a skewed interpretation of positivity. For example, sarcasm often conveys negativity without explicit negation, making it invisible to this models. The Textblob tool will classify Spencer as positive because of the use of the word “wonderful” having a hard time distinguishing figurative language and humor and irony. Qualitatively analysing Spencer’s answers with human understanding of context and meaning, it is clear that the output is highly sarcastic and thereby negative in reality.The lack of negation words makes it difficult for the model to recognise negativity embedded in the context and phrasing. Its judgement is based on “pre-defined dictionary classifying” of a words “intensity” and categorization as either positive or negative (Shah 2020).As a result the word “wonderful” that the overly critical persona in our experiment used as an exaggerated expression of its disagreement and ironic style element is classified as a positive adjective by textblob.
This refers to a general problem with NLPs as they are not context aware, but focus on the tokens in the sequence of text. Thereby, highly context and meaning dependent content that is not clearly marked as positive or negative through the use of negation words or clearly positive or negative adjectives, gets misinterpreted by the script (Shah 2020).
5. Discussion
6. Conclusions
7. References
Sutcliffe, R. (2023). A Survey of Personality, Persona, and Profile in Conversational Agents and Chatbots. arXiv preprint arXiv:2401.00609.
Teo, S. (2023, December 29). How I Won Singapore’s GPT-4 Prompt Engineering Competition: A deep dive into the strategies I learned for harnessing the power of Large Language Models (LLMs) https://medium.com/towards-data-science/how-i-won-singapores-gpt-4-prompt-engineering-competition-34c195a93d41#1cfa
Aljedaani, W., Rustam, F., Mkaouer, M. W., Ghallab, A., Rupapara, V., Washington, P. B., ... & Ashraf, I. (2022). Sentiment analysis on Twitter data integrating TextBlob and deep learning models: The case of US airline industry. Knowledge-Based Systems, 255, 109780.Munk, A. K., Jacomy, M., Ficozzi, M., & Jensen, T. E. (2024). Beyond artificial intelligence controversies: What are algorithms doing in the scientific literature?. Big Data & Society, 11(3), 20539517241255107.
Shah P. (2020) Sentiment Analysis using TextBlob https://towardsdatascience.com/my-absolute-go-to-for-sentiment-analysis-textblob-3ac3a11d524
Rogers, R., & Zhang, X. (2024). The Russia–Ukraine War in Chinese Social Media: LLM Analysis Yields a Bias Toward Neutrality. Social Media+ Society, 10(2), 20563051241254379.Ideas, requests, problems regarding Foswiki? Send feedback