Benchmarking AI Chatbots in Sociology and the Humanities: Evaluating the Capabilities and Limitations of Six Large Language Models
What kind of sociologist is your LLM?
Team Members
Mathilda APPERT--CURADO, Eldi BICARI, Ahmed DIAKITE, Kanako INOUE, Tania KETOGLO, Cyrille Anicet Bio KOUMA, Dounia PIHAN, Jeannie Luria RABEFALIANA, Justine XU
Project facilitators: Bilel Benbouzid (Université Gustave Eiffel), Noé Durandard, Irène Girard, Alexis Perrier (Université Gustave Eiffel), Carlos Rosas
Links
Poster Task 11. Introduction
The term ‘artificial intelligence’, while not new, has never received as much media coverage as it has in the last few years. According to Google Trends, over the last five years, the figures show that from November 2022, so from the time OpenAI launched ChatGPT to the general public, Google searches on artificial intelligence (AI) have not stopped increasing, and are even at their highest today. Seen as the technology of the future, it has in fact already infiltrated our daily lives in a more or less hidden way. However, technologies equipped with artificial intelligence have been available to the general public for several decades now, particularly in the field of video games. In tic-tac-toe or chess, for example, we have been able to ‘play against the computer’ since the 1950s, and although primitive, this remains a form of artificial intelligence or a mimicry of human intelligence by the machine. And yet, when you talk to the average person about artificial intelligence, nobody will talk about the same thing. The most informed minds talk about layers of complex calculation algorithms, and the least knowledgeable talk about robots replacing humans. The diversity of the different services and products that use artificial intelligence in one way or another makes it difficult to define.
However, the development of Artificial Intelligence (AI) and Generative Artificial Intelligence (GAI) reached a level as such researchers don’t even question its use anymore. In only two years, we have seen a significant change in the way people look for, view and create knowledge, and research on this topic is slowly emerging. For years already, researchers in “natural” sciences have been using technologies equipped with forms of AI, but it’s only since the deployment of ChatGPT that the general public have acknowledged the existence of such tools. It is also at this time that researchers in humanities and social sciences saw the potential of GAI for their work. Large Language Models (LLM) offer a new way of working with data in format other than numbers, like texts, sounds, films and images, displaying new possibilities for research, experimentation and simulation like never before. These tools, and their creators, present AI and GAI as solutions to revolutionize traditional research methods. In a world where meta-research (research on your research) becomes the norm, and scientific accuracy becomes more and more demanding, using large amounts of data to prove the relevancy of your research seems to be the most logical route. However, limitations and biases in LLM have also been put under the spotlight, questioning the reliability, ethics and transparency of these tools. These biases are notably apparent when GAIs are used in fields of social sciences.
Within scientific communities, there is a growing need for scientific rigour, and this involves in particular the use of statistical data to prove the relevance of our research. The concept of "meta-searching our research" (Burger & al. 2023) highlights the need to demonstrate the study's transparency, reproducibility, and potential biases. To do this, it is often necessary to carry out massive analyses of digital and/or textual data, with systematic literature reviews, and AI can act as an assistant in these processes. Burger and his colleagues, in an article on the role of narcissism in entrepreneurial activities (Burger, Kanbach, et Kraus 2024), talk about systematic literature reviews as the best way of understanding the issues in the limited field in which their subject falls. By identifying keywords to include and exclude, and selecting publications and dates, GPT-3 was able to select 68 articles, then classify them by theme, and generate summaries and a few graphs. In his article on the use of AI tools to manage research, Berger explains that AI can reduce human error. Unlike machines, humans sometimes skim through certain data, making careless mistakes. The machine, on the other hand, will systematically take into account all available data. The fact that the machine has adjustable parameters, or at least known parameters, makes the output of the machine constant, and therefore reproducible, thus fulfilling one of the main foundations of science. In the scientific process, peer review also plays a central role in scientific reliability, and this stage is often one of the longest and most costly for researchers, with round-trips being commonplace. AI can thus serve as a pre-peer review tool, offering instant feedback and assisting with re-reading protocols, drafts, and research plans. This use of AI has the potential to save both time and resources.
However, despite these advantages, our understanding of the reliability of conversational AI in sociology and the humanities remains limited. While research on the matter of biases in LLMs for research in social sciences and evaluations of chatbots exist in various scientific fields, most focus on the limitations in fields such as medicine, finance, and law.
Several reasons account for the scarcity of studies dedicated to the humanities:
-
Absence of specific tests: No tests are specifically designed to assess AI performance in scientific work within the humanities.
-
Disciplinary disparities: Research in the humanities generates less interest compared to more lucrative scientific fields like medicine, finance, and law. Consequently, AIs may produce less accurate results in these disciplines due to a lack of developer interest.
-
Difficulty in quantifying data: There is a lack of quantifiable data to measure the rate of inaccuracies in AI-generated content within the humanities. Evaluating LLMs for the humanities and social sciences is particularly challenging and requires a specific approach.
-
Specific biases: We still do not fully understand what types of biases specific to the humanities AIs might generate.
This lack of knowledge underscores the need to design tests and diversify testing methods to better understand the reliability and potential biases of AIs in the humanities.
Existing research has already demonstrated that the conceptualisation of LLMs is inherently shaped by biases. The knowledge embedded in these models derives from their training datasets extracted from the internet, which are neither neutral nor free from bias. Given that the internet contains a proliferation of harmful and prejudiced content, such material is often not entirely excluded from training. Consequently, LLMs have been shown to internalize social stereotypes, ideological and political biases (Chang & al. 2024). For example, recent studies have shown that on a more classical liberal to conservative spectrum, ChatGPT -4o and Claude seem to be more liberal in their political stance than Perplexity, which seems to be more conservative, while Google Gemini stands somewhere in the middle (Choudhary 2025). In another study conducted by Motoki and his team, where they asked ChatGPT questions related to politics and ideology, the chatbot presented a bias towards the Democrats in the US, Lula in Brazil, and the Labour Party in the UK (Motoki, Pinho Neto, et Rodrigues 2024). Given that social science disciplines are inherently influenced by political currents, it is legitimate to question whether generative AI can serve as a reliable and relevant research assistant.
Furthermore, these biases are not only a function of the training data but also reflect the predispositions of the developers who design these systems. While this issue has long been recognized within technological and academic circles, it has become increasingly apparent to the general public, particularly following the release of DeepSeek R1. For instance, attempts to prompt this LLM with inquiries regarding the 1989 Tiananmen Square events or the political status of Taiwan reveal clear limitations and alignments that may raise a few eyebrows. Additionally, the overrepresentation of white and male professionals in the fields of computer and data science further contributes to the propagation of systemic biases within these technologies (Dwivedi & al. 2023).
A second critical issue concerning the reliability of generative AI is that, despite LLMs’ ability to generate factually accurate content, they are also prone to producing misinformation or statements ungrounded in reality—a phenomenon known as hallucination (Naveed & al., 2023). Conceptually, LLMs function as systems designed to fulfill user demands, sometimes to the extent of fabricating information in order to do so. Since these models generate text based on probabilistic patterns rather than a commitment to factual accuracy, truthfulness might not be their primary focus.
Given these challenges, it is critical to assess the performance of LLMs, particularly in their ability to generate scholarly content in the humanities. While some research has been conducted on the biases and limitations of these models, fewer studies have systematically evaluated their potential to produce academically rigorous work.
Therefore, during the workshop, we attempted to build an evaluation of LLMs, combining quantitative and qualitative analyses to address this gap and better understand the capabilities of AIs to produce relevant and original scientific content in the humanities.
This project is situated within the broader debates on the capabilities and limitations of generative artificial intelligences (LLMs) in disciplines where interpretation, critique, and epistemological diversity are central, such as sociology and the humanities.
While LLMs have already been extensively evaluated in fields like medicine, law, and finance, these analyses often overlook disciplines where quantification is less directly applicable, and where cultural and epistemological biases have a more significant impact. The project aligns with the broader goal of social sciences research to identify how new technologies influence the production and dissemination of scientific knowledge. It also addresses the growing concerns around social justice and epistemological equity in artificial intelligence by investigating the structural biases and asymmetries in representation inherent in LLMs’ responses.
This project also seeks to investigate the ability of AI chatbots to assist sociologists in their academic work. Are these tools capable of going beyond systematically recommending the same prominent sociologists? If the responses predominantly highlight only the most popular of the discipline, such as the ones with the most media visibility, it would indicate that ChatGPT and similar models are not suitable assistants for serious scientific inquiry.
The findings will also contribute to the debate on the risks these tools pose for students, particularly in terms of learning, critical autonomy, and training in humanities methodologies. They will provide insights into the tensions emerging when algorithmic tools are integrated into academic work and pave the way for recommendations on the ethical and educational use of these technologies in higher education.
2. Initial Data Sets
Task 1
A list of 1000 research topics related to sociology was provided by the project facilitators. These research topics were collected from reputable educational websites offering research ideas for undergraduate and postgraduate sociology students. It should be noted that this initial dataset was not our object of study, but rather as source materials to develop our evaluation dataset which was expanded upon and further processed before being incorporated into our research. We explain more about the input data preparation in section 4.1.
Task 2
The database used in this study contains 1,307 rows and 7 columns, designed to analyze news articles from a sociological perspective. Each row corresponds to an article and includes several key variables. The “gen_text” column contains the full text of the article, while “resume_fr” and “resume_en” provide summaries in French and English, respectively. The thematic classification is handled by the supercategory column, which groups articles under general categories such as society or sport. The mistralai/Mistral-7B-Instruct-v0.3_completion and LLaMa columns contain responses generated by the Mistral 7B and LLaMa models based on a specific prompt. These responses contain several analyzable variables from a sociological standpoint. Among these, the main actors mentioned in the article are identified under “Protagonistes”, and two significant keywords are extracted under “Keyword 1” and “Keyword 2”. The scale of analysis is specified in the Unity of Analysis column, which distinguishes three levels: micro (individual interactions), meso (groups and institutions), and macro (societal structures and dynamics). The sociological discipline applied is indicated in the “Discipline” column. Furthermore, each article is associated with three sociologists (“Sociologist 1, 2, 3”) and the corresponding concepts (“Concept 1, 2, 3”), with links specified in Lien Sociologist-Concept 1, 2, 3. The objective is to identify the most relevant sociologist (Sociologist Selected) and justify this choice in the Reasoning column, highlighting a key aspect of the article (Aspect mis en avant). Finally, variables such as “Mots-clés” “Conceptuels” and “Contribution” help to clarify the contribution of the selected sociological concept.
Task 3
A separate full report has been made for Task 3, which you can find through this link (link to be added later). Brief overviews of this task’s results have been added to this report.
3. Research questions
Context
The emergence of large-scale language models (LLMs) has revolutionized many fields, especially in medicine, law, and finance, etc. The development of LLMs has been accompanied by the development of “natural language processing” (NLP). LLM is an evolution of NLP.
For example, a program called “ELIZA”, developed in the 1960s, was able to engage in simple dialogue with humans based on predefined rules. This was revolutionary for the technology of the time, but it could not understand complex contexts.
Then came machine learning, “Transformer”, published by a Google research team in 2017, became a groundbreaking model that revolutionized the world of NLP and continues to develop at a phenomenal rate to this day.
However, while these developments have occurred, the methods and frameworks used have not been fully developed.
In particular, social sciences and humanities have not yet been fully explored in the framework of AI evaluation. Given these disciplines' reliance on diverse methodologies, it is essential to investigate how LLMs engage with these disciplines. This section outlines key research questions for a detailed assessment of LLM competence in the humanities and social sciences.
Problem
As discussed above, despite the rapid development of LLM and its application in a variety of disciplines, the validity of LLM in sociology and the humanities remains uncertain. Unlike disciplines with clear quantitative measures, such as “natural” sciences and engineering, sociology in particular requires a deep understanding of non-lightweight contexts such as culture, history, and ideology, and relies on nuanced, theoretical analysis for its interpretation.
The lack of suitable evaluation indicators for LLMs in sociology and social sciences will create various risks in the future. For example, from its birth to the present, the LLM has been operationalized and applied particularly in science-oriented fields. This situation is likely to create academic bias. Such social science disciplines are often trained with data sets that reflect only already dominant perspectives, which may, for example, marginalize niche areas of study and non-Western epistemologies. Furthermore, AI-generated responses may even reinforce existing academic biases, as they tend to favor widely cited theories over emerging or marginalized perspectives.
In addition, AI has difficulty systematically measuring the sociological content it generates, making it impossible for anyone other than sociologists or researchers who are already educated or deeply knowledgeable in the social sciences to rigorously assess the performance and biases of its generated models.
In light of these issues, we have established a research question for each project to systematically assess the role of LLMs in sociology.
Although these questions differ from project to project, they have one thing in common: they seek to identify the limits of the sociological imagination exhibited by LLMs.
Task 1
This task investigates the patterns of sociologists recommended by LLM, and focuses on the diversity and potential bias in sociological references. The aim is to identify what types of sociologists LLM recommends and whether it has the ability to show diversity.
We also try to understand whether the language of the prompts has an effect on LLM's selection. For example, if the LLM is recommending mainly Western scholars, the question arises as to whether this is due to limitations in the training data or whether it is due to a bias in the system.
Furthermore, we will examine whether the LLM always recommends sociologists based on theoretical relevance, or whether the answers are shaped by the tendency of the algorithm to reinforce the dominant image of scholars. Is it possible to fine-tune the model to make recommendations that reflect the situation of sociology more globally?
We will check whether there is a pattern in the way LLM recommends sociologists and whether epistemological diversity is demonstrated. If the models always prioritize Western scholars, it may indicate that there is a systematic bias in the training data. Furthermore, we expect that some models will recommend more diverse but academically unproven scholars, or raise questions about their academic credibility.
Task 2
This task assesses the ability of LLM to apply sociological theory to real-world news articles, analyzing their consistency, accuracy, and bias.
Does the LLM consistently apply sociological theory when interpreting news articles? How does the LLM make conceptual connections coherent across different prompts and topics?
This task investigates inconsistencies in the ways different LLM's categorize and interpret news articles. It analyzes how internal biases and training methods may be at work when different models assign different theoretical frameworks to similar news content.
Furthermore, it investigates the potential for improved prompts to improve consistency in LLM's theoretical application. We will analyze the ability of multi-level prompts and structured input formats to improve consistency with established sociological methods.
We will also examine whether LLM shows any bias in its selection of sociological concepts and theorists when analyzing news. Do certain perspectives tend to be systematically prioritized over others? How do these biases affect AI's sociological reasoning?
This task anticipates that LLM may not be consistent in the way they apply sociological theory to interpreting news. While one model may show consistency in the relevance of concepts, another model may not be consistent in the theory across different prompts. Furthermore, biases in the selection of concepts and sociologists will be identified, revealing how LLM form sociological inferences.
Task 3
In this work, to verify its application in sociology, we analyzed topic modeling and research methods and sociological theoretical frameworks, using 900 French sociological paper abstracts from 1986 to 2023, and evaluated some of the open-source models such as Mistral, Qwen, and Llama, as well as the proprietary models Claude and ChatGPT, which are part of LLM.
Do the larger LLM models in this task make more balanced decisions? Do more sophisticated models like GPT and Claude show ideological biases despite their size and sophistication? We also examine the role of training data in bias formation in LLM. What are the epistemic implications of models trained on Western-centric data producing different sociological interpretations compared to models trained on global sources?
Furthermore, this task also investigates whether LLM from different regions exhibit different cultural biases. How do models like Qwen (China) and Llama (USA) differ in their theoretical prioritization? Can these differences be systematically categorized? Furthermore, we explore whether adversarial testing can reveal the underlying biases in LLM decision-making. Can targeted stress tests reveal the epistemological or ideological tendencies hidden in different AI models?
While different LLM are expected to show different ideological tendencies, the larger the model, the more balanced it is not necessarily. Models trained in the West may produce different sociological interpretations than those trained on global datasets, leading to epistemological disparities. For example, models developed in different regions, such as Qwen in China and Llama in the United States, are also expected to show clear cultural biases in their theoretical prioritization. It is expected that this confrontation test will further reveal potential biases in decision-making and demonstrate the need to improve the transparency and epistemological inclusiveness of models.
In this way, we believe that the results of this project will provide information for both AI developers and social scientists, and will promote interdisciplinary dialogue on the responsible integration of AI into the study and teaching of the humanities.
4. Methodology
Task 1
This study evaluates large language models (LLMs) in the context of sociology by adapting existing benchmarking protocols from other disciplines. Our methodological approach consists of several structured steps to ensure a rigorous and replicable analysis.
Literature Review and Rationale
We began with a literature review to assess the current state of LLM benchmarking in the social sciences. While extensive benchmarking frameworks exist for fields such as computer science and medicine, sociology lacks standardized evaluation methods. This gap can be attributed to the field’s epistemological diversity, where knowledge is more interpretative and less structured than in disciplines with clear canonical knowledge. Our study seeks to address this by proposing an initial framework for LLM evaluation in sociology.
Data Collection and Topic Generation
To build a dataset for testing LLMs on sociological topics, we curated 1,500 research topics from reputable educational sources. To expand the dataset, we used ChatGPT 4o with a few-shot prompting approach, ensuring each generated question maintained a clear sociological focus. The dataset underwent manual review to eliminate duplicates, improve clarity, and ensure diversity in theoretical and methodological perspectives.
Topic Classification Attempt
We experimented with categorizing the topics using the Universal Decimal Classification (UDC) system, which provides structured labels for sociological research areas. However, this approach proved problematic due to overlapping categories, inconsistencies between human and automated classifications, and imbalanced distribution across categories. Given these challenges, we decided to forgo classification in our final analysis but acknowledged its potential for future refinements.
Multilingual Testing
Recognizing the global nature of sociology, we examined whether LLM performance varied across languages. The dataset was translated into French, Mandarin, and German using the DeepL API, as ChatGPT -based translation produced inconsistent results. The translated topics were reviewed by native speakers to ensure accuracy. This multilingual dataset allowed us to assess how language influences LLM outputs and potential biases in scholar recommendations.
LLM Evaluation and Prompting Strategy
To ensure consistency in LLM responses, we designed a structured prompt to generate concise, well-formatted outputs. We tested five major LLMs—ChatGPT 4o, Claude Sonnet, Llama, Qwen, and Gemma—selecting them for their high performance and mix of open-source and proprietary origins. Each model was queried in multiple languages, with responses stored in structured datasets for further analysis. Mistral was also tested initially but excluded from the final analysis due to format inconsistencies and unreliable outputs.
Post-Processing and Analysis
All LLM-generated responses were cleaned and validated to remove extraneous punctuation, normalize character variations, and segment scholar recommendations for structured comparison. We flagged and filtered out hallucinated or non-relevant names using an automated confidence-scoring method, followed by manual verification of a sample set. This allowed us to benchmark LLM accuracy in recommending sociologists.
Additionally, we analyzed patterns in scholar recommendations across languages and models. We assessed scholar prevalence (how often a name appeared) and potential biases, such as overrepresentation of Western or canonical sociologists. We visualized these trends using distribution charts, heat maps, and word clouds to better understand the disparities across models and languages.
Task 2
Dataset Design and Balancing
As part of our study on the ability of a Large Language Model (LLM) to interpret current events through the lens of a specific sociological concept, we constructed a dataset based on articles from the French newspaper “Le Monde”.
Our initial exploratory analysis revealed an imbalance in the distribution of supercategories, with a high concentration of articles in the “politics and international relations” and “arts and culture” sections. This imbalance could introduce bias, limiting the diversity of topics covered and influencing the results of automated classification models.
To correct this asymmetry, we incorporated a complementary dataset selected based on the following criteria:
-
Thematic balance : Additional articles were sourced from underrepresented categories
-
Diversity of topics : Ensuring a broad range of subject matters
-
Temporal consistency : Maintaining chronological coherence with the initial dataset
This adjustment helped reduce the overrepresentation of dominant categories and resulted in a more evenly distributed dataset, ensuring better representation of the themes covered by “Le Monde”.
Once the final dataset was compiled (comprising 1 308 articles), a validation analysis was conducted to assess the effectiveness of the rebalancing process and confirm the dataset’s suitability for sociological analysis. By structuring the data more evenly, this approach enhances the reliability of automated processing and minimizes potential biases.
Prompt Design and Sociological Analysis Methodology
To utilize this dataset for sociological analysis, a structured prompt was designed to guide the interpretation of current events through a specific theoretical framework. The objective is to ensure a methodologically rigorous approach, broken down into several key steps:
-
Definition of the theoretical framework : The user adopts an analytical perspective by selecting a specific sociological theory. This choice ensures coherence in the interpretation of social dynamics and makes the analysis accessible to a broad audience.
-
Identification of key actors : A preliminary step involves identifying the main protagonists of the event to understand their roles and influences. This stage is essential for examining power relations and social interactions.
-
Event summary : The user provides a concise summary of the event, highlighting key facts and underlying social and political issues.
-
Selection of keywords and justification of the theoretical framework : Three relevant keywords are extracted from the article to identify central concepts. The chosen sociological theory is then justified based on its relevance to the issues raised by the event.
-
Selection and ranking of key sociologists : Three sociologists are selected based on the relevance of their work to the analysis. They are ranked according to their explanatory contribution.
-
Determination of the level of analysis : The analysis is positioned at the micro (individuals and interactions), meso (groups and institutions), or macro (social structures and global phenomena) level, depending on the nature of the event and the chosen theoretical framework.
-
Assessment of the confidence level in the analysis : The reliability of the interpretation is evaluated by assigning a confidence percentage. This estimate is based on several factors, including the robustness of the theoretical framework, the diversity of available perspectives, and the potential limitations of the chosen approach.
Application to LLAMA and Mistral Models
The constructed database, along with the designed prompt, was used to query the LLaMa and Mistral language models. This experiment aims to evaluate their ability to identify sociological concepts, link events to relevant theories, and structure an analysis that adheres to academic standards. The comparative analysis of the results produced by these models will highlight their respective performances in terms of accuracy, conceptual depth, and analytical coherence.
Task 3
Details on the dedicated report here (link to be added).
5. Findings
Task 1
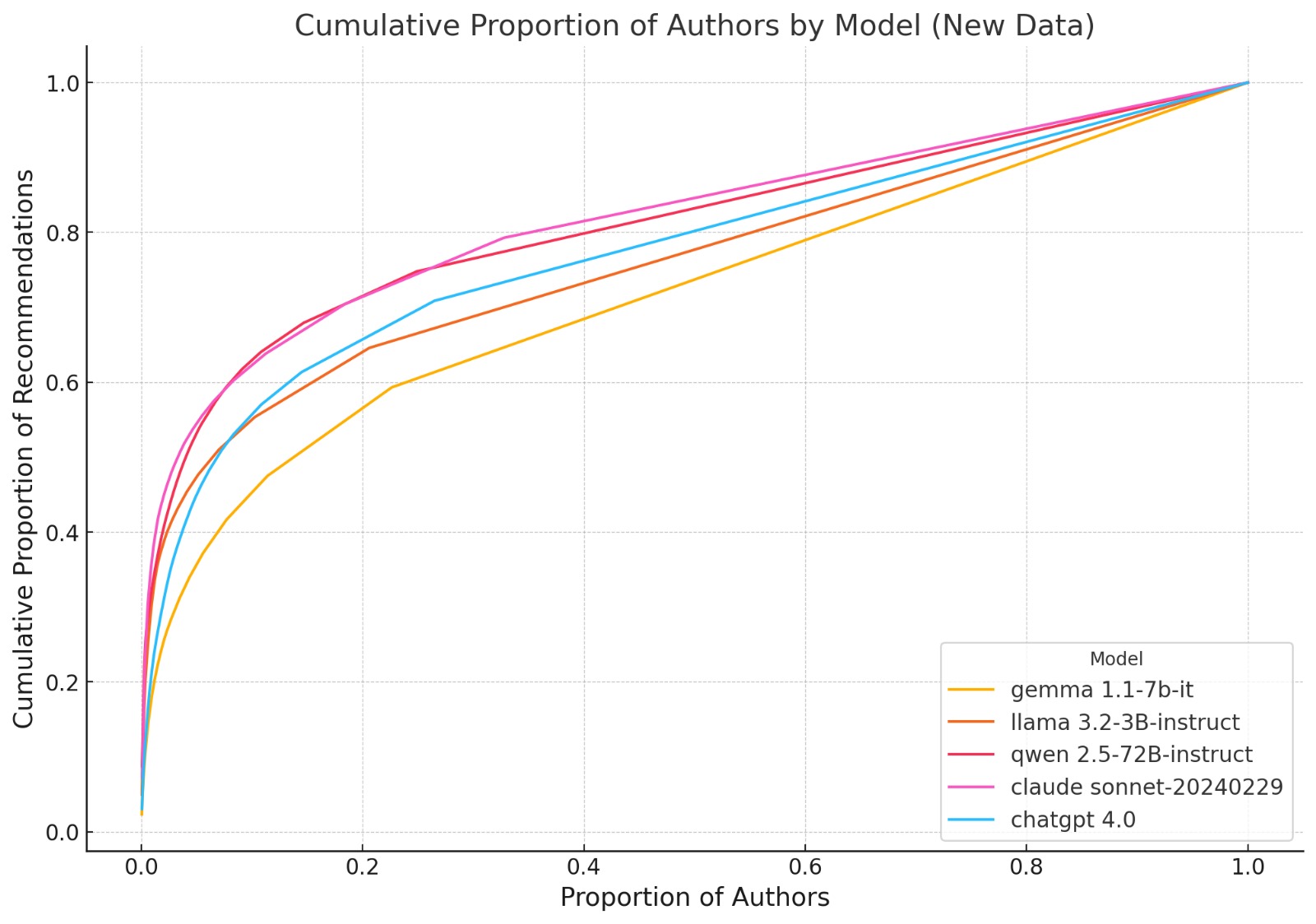
Analysis of the Cumulative Proportion of Authors Recommended by Language Models
Introduction
The graph presents the cumulative distribution of author recommendations across five language models: Claude Sonnet, ChatGPT -4, Qwen, Llama, and Gemma. The x-axis represents the proportion of authors, while the y-axis represents the cumulative proportion of recommendations, allowing us to analyze the diversity and concentration of recommendations across models.
Findings and Interpretation
-
Variation in Recommendation Diversity
-
Claude Sonnet (pink) and ChatGPT -4 (blue) exhibit the steepest initial growth, suggesting that these models distribute their recommendations more evenly across a larger set of authors. This implies a higher diversity in recommendations.
-
Gemma (yellow), in contrast, has the flattest curve, meaning a small proportion of authors account for a significant share of recommendations. This suggests that Gemma’s recommendations are more concentrated and less diverse.
-
Llama (orange) and Qwen (red) fall between these two extremes but still show a noticeable concentration of recommendations on a limited subset of authors.
-
-
Long-Tail Distribution and Model Bias
-
The presence of a long-tail effect in some models, particularly Claude and ChatGPT -4, indicates that they are more likely to recommend less frequent or niche authors, thereby promoting diversity.
-
Models like Qwen and Llama exhibit a more gradual increase, implying a focus on a relatively narrower set of well-established authors.
-
-
Counter-Intuitive Observations
-
Given its large parameter size (72B), one might expect Qwen to produce a broader range of recommendations. However, its curve is relatively steep, suggesting that despite its extensive training, the model remains concentrated in its author suggestions.
-
Claude and ChatGPT -4 show similar trends, which is noteworthy considering they originate from different training methodologies. This may suggest similarities in dataset composition or optimization strategies.
-
Gemma's pronounced concentration is surprising, as models trained on diverse datasets typically exhibit a more even recommendation spread. This suggests that Gemma’s algorithm may introduce stronger biases or rely on a more restricted corpus.
-
Implications
The findings highlight significant differences in how AI models generate author recommendations. Models like Claude and ChatGPT -4 prioritize diversity, making them more suitable for applications requiring a broad range of perspectives. Conversely, Gemma and Qwen appear to focus on a narrower subset, which may be useful for specialized domains but could also introduce biases. Understanding these disparities is essential for ensuring fairness and inclusivity in AI-driven recommendation systems.
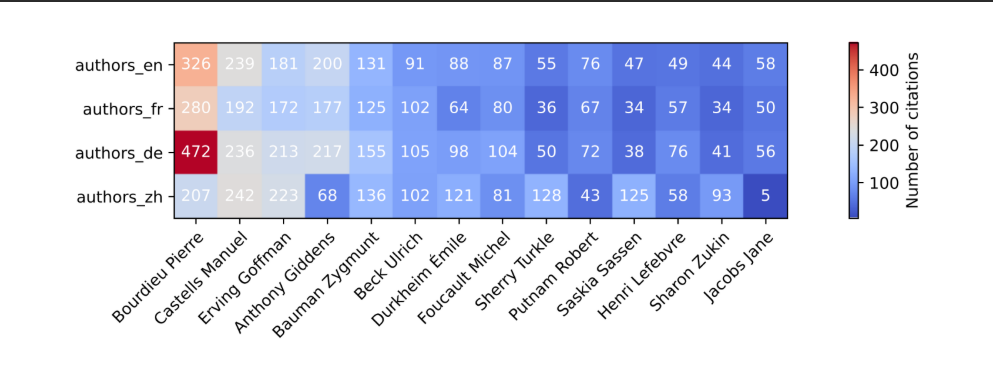
Heat Map 1: Number of Author Citations per Language
Analysis of Heat Maps: Diversity of Recommended Sociological Authors
Findings: This heat map illustrates the frequency of citations for the top 14 sociological authors across four languages (English, French, German, and Mandarin) when prompted to the language model Claude Sonnet-20240229. Notably, Pierre Bourdieu is cited most frequently across all languages, with a marked peak in German. This suggests a consistent preference by the model, regardless of language, which could indicate a strong training emphasis on his works.
Counter-Intuitive Findings: While one might expect the model to show considerable variability in author preferences across different languages due to cultural and linguistic differences, the heat map reveals minimal differences. This consistency across languages, especially with Bourdieu's dominant presence, suggests that the model's training data may disproportionately favor Western sociological thinkers, potentially underrepresenting non-Western perspectives.
Significance: The consistent cross-linguistic citation of certain authors suggests a potential bias in the training datasets towards Western sociologists. It raises questions about the inclusivity and diversity of the training data, as well as the model's applicability in diverse cultural contexts.
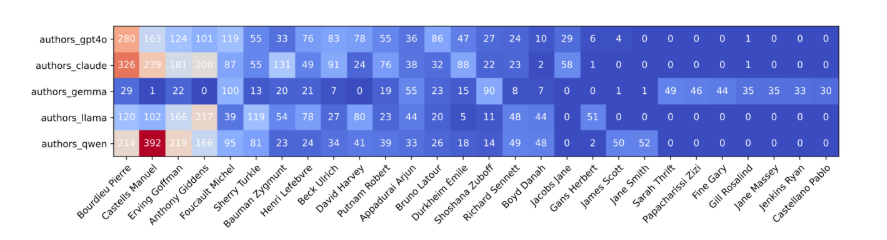
Heat Map 2: Number of Author Citations per LLM
Findings: This heat map compares the citation frequency of the same top authors among different large language models (LLMs) — Claude Sonnet, Gemma, Llama, and Qwen — using English prompts. Pierre Bourdieu remains the most frequently recommended author, followed closely by Manuel Castells, reflecting a similar trend observed in the language-based heat map. However, Gemma stands out for its distinct pattern; it recommends a broader and more diverse set of authors, as evidenced by its more varied and lower citation counts across the board.
Counter-Intuitive Findings: Gemma's behavior is particularly noteworthy. Despite being a smaller model (with only 7 billion parameters), it suggests a wider range of authors than its larger counterparts. This diverges from expectations that larger models with more extensive training datasets and capabilities might offer broader recommendations. However, the accuracy of Gemma's suggestions is questionable, as some recommended authors, like Sarah Thrift, do not have verified sociological credentials.
Significance: The diversity exhibited by Gemma highlights a possible advantage of smaller models in escaping the typical focus on a narrow set of well-cited authors. It underscores the importance of model design and optimization strategies over mere size in achieving diversity in AI-generated recommendations. This suggests that AI developers might need to consider balancing model parameter size with training data quality and algorithmic diversity to enhance the breadth and relevance of recommendations.

Word Cloud Analysis: LLM Model Comparison English Prompt: ChatGPT 4o, Claude Sonnet, Gemma, Llama, Qwen.
Overview of Findings:
The word clouds provide a visual representation of the frequency with which top sociological authors are recommended by four different large language models (LLMs) — Gemma 1.1-7b-it, Qwen 2.5-72B-instruct, Llama 3.2-3B-instruct, and Claude Sonnet-20240229, as well as ChatGPT 4.0. These visuals display the variations in model output when prompted in English, focusing on sociological themes.
Key Observations:
-
Prominent Authors Across Models:
-
Pierre Bourdieu and Manuel Castells appear prominently across nearly all models, underscoring their recognized status within the sociological discipline. This uniformity suggests a potential model training convergence on well-established Western sociological figures.
-
Erving Goffman and Michel Foucault also feature frequently, but with varying prominence across different models, indicating differing model sensitivities or data trainings that favor certain theorists over others.
-
-
Distinctive Features of Each Model:
-
Gemma: This model displays a remarkably diverse range of author names, including less traditional or mainstream sociologists like Shoshana Zuboff and Sarah Thrift. This suggests an exploration into more contemporary and interdisciplinary fields.
-
Qwen: Shows a more conventional approach with a focus on historically significant sociologists but includes a broad spread of names, reflecting a balance between mainstream and peripheral figures.
-
Llama: Similar to Qwen, but with a slightly narrower focus, predominantly highlighting established authors without much exploration into contemporary names.
-
Claude Sonnet and ChatGPT 4.0: Both exhibit a strong preference for classic, well-cited sociologists with a limited insertion of less dominant figures, suggesting a training dataset heavily influenced by traditional academic curricula.
-
Counter-Intuitive Findings:
-
While one might expect larger models like ChatGPT 4.0 and Claude Sonnet to offer a broader diversity of authors due to their extensive training datasets, they often echo the same set of well-known figures, highlighting a potential overfitting to mainstream sociological literature.
-
The presence of lesser-known or potentially irrelevant figures in Gemma’s output raises questions about the accuracy and reliability of its recommendations, juxtaposing its diversity against the precision of suggestions.
Significance and Implications:
The word clouds highlight each model's unique approach to generating sociological author recommendations. The reliance on established sociological figures by most models could indicate a lack of diversity in training data, potentially limiting the models' utility in exploring novel sociological perspectives or emerging scholars. Conversely, the diversity shown by Gemma, while commendable for its breadth, may necessitate further verification to ensure relevance and accuracy.
This analysis underscores the importance of carefully curating training datasets for LLMs to achieve a balance between diversity and accuracy in academic recommendations. It also prompts a critical examination of how AI biases can influence academic research outputs and the necessity for rigorous validation of AI-generated content, especially in scholarly settings where precision is crucial.
Conclusion:
The word cloud analysis serves as a diagnostic tool, revealing not only the potential and limitations of each LLM in recommending sociological authors but also illustrating the broader implications for AI in academic research. It highlights the ongoing challenge of ensuring that AI tools support a broad spectrum of academic inquiries without sacrificing the rigor and relevance required for scholarly work.
Task 2
In this section, we compare the Llama and Mistral models in their ability to recognize and associate sociological authors and concepts. We describe their differences, as well as their coherence and pertinence. Llama is a model developed by Meta, an American company. Mistral AI, on the other hand, was designed by a French company. We examine how these two approaches influence their performance and results.
1. Comparison of the selection of sociological authorsWe compare the way Llama and Mistral select sociological authors. This analysis shows their choices, their differences and their coherence.
1. Consistency between domain of knowledge and keyword selection on LlamaThe density chart shows that Llama labels keywords in the appropriate theoretical domains consistently. Ulrich Beck, who specialises in the sociology of risk and reflexive modernity, is the most cited author, ahead of Erving Goffman, specialist in interactionist and ethnomethodological sociology, and Pierre Bourdieu, who specialises in critical sociology and constructivist structuralism. Karl Marx, a specialist in critical sociology and historical materialism, is not far behind Bourdieu, although he is cited less frequently.
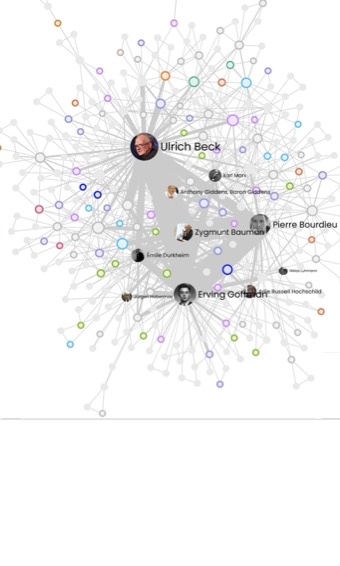
Figure 1: Mapping of authors associated with keywords according to LlaMa
2. Inconsistency between the modelsProportionally, out of 40 sociological authors, Llama got 20, as did Mistral. However, the authors cited are not exactly the same. Between them, the models mention Pierre Bourdieu, Emile Durkheim, Erving Goffman and Ulrich Beck. Pierre Bourdieu is overwhelmingly cited by Llama, as is Emile Durkheim, who manages to come second in this distribution, while Mistral cites hardly any Emile Durkheim, and much less Pierre Bourdieu. Some authors are also cited by only one model, and we find little concordance.

Figure 2: Distribution of sociological authors cited by Llama and Mistral
It's worth noting that Llama, the American model, quotes more often from a French sociologist as Pierre Bourdieu, while Mistral, the French model, refers more often to Ulrich Beck, a German sociologist. This trend raises questions about how each model weighs up its sources and sociological references. Furthermore, we note that Bourdieu is the sociologist most often cited by Llama, while he only comes third for Mistral. Llama also seems to have a tendency to over-cite the same author, which may indicate a bias in his reference selection algorithm.
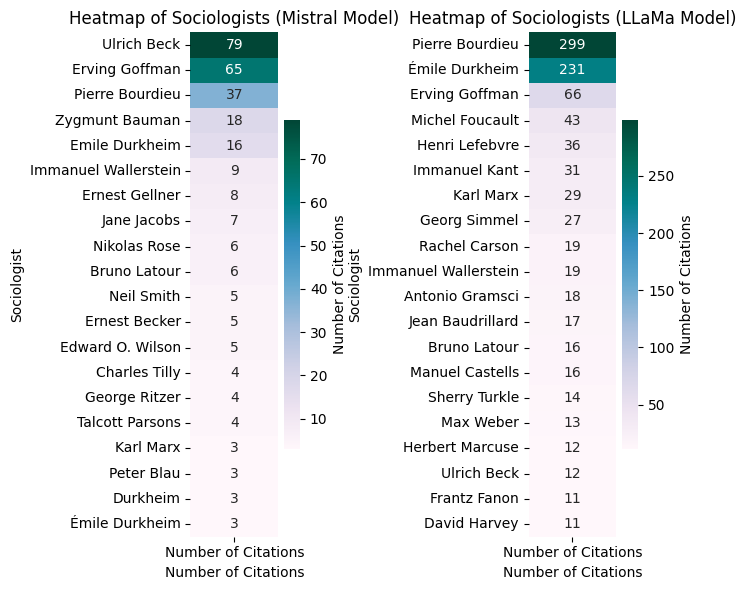
Figure 3 : Comparison of sociological authors cited by Llama and Mistral
2. Differences in the selection of sociological conceptsThe Llama and Mistral models show differences in the selection and association of sociological concepts. Llama seems more precise in identifying concepts and associating them with keywords.
1. Little agreement between modelsThe pie chart shows little agreement between the models: Llama selects more sociological concepts than Mistral. Only 20 common concepts were found out of a total of 547 identified. Mistral lists 193, while Llama 334.
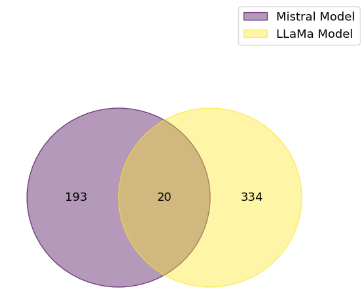
Figure 4: Comparison of the number of sociological concepts cited by Llama and Mistral
2. Consistent association of concepts and keywords selection on LlamaThe density chart shows that LLama labels keywords in the appropriate theoretical domains consistently. Society, which is generally at the heart of sociological analysis, is cited very often, and is well associated with the keywords “collective consciousness” and “social order”. Themes such as politics and the economy are also often cited by Llama and associated with the right keywords.
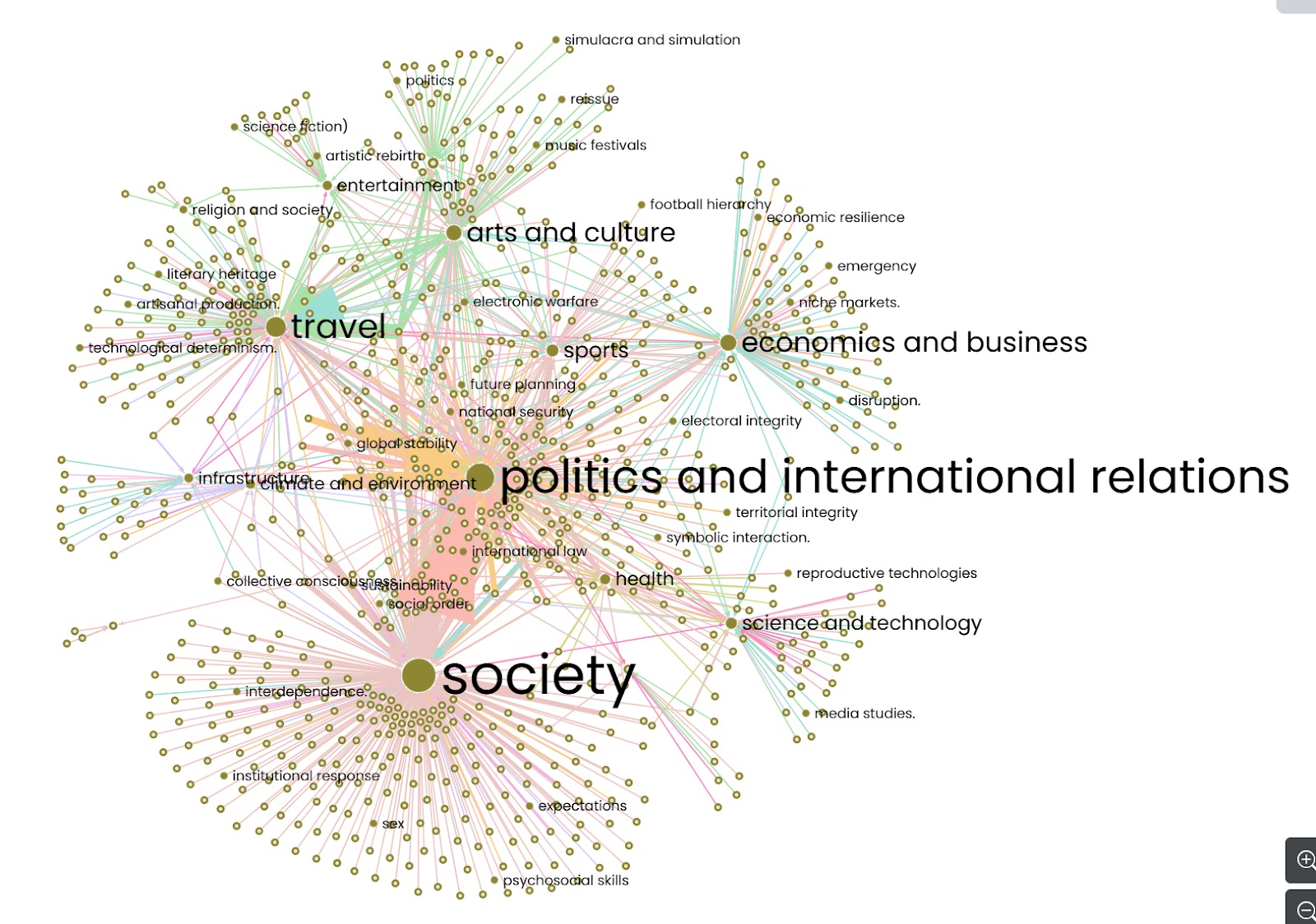
Figure 5 : Llama's association of sociological concepts with keywords
3. Differences in article categorizationThe Llama and Mistral models differ in the way they classify press articles. From the start, divergences were noted in their contextual classification. This calls into question the effectiveness of their approaches.
1. Inconsistency in Article Categorization Between ModelsAt the start of the analysis, differences appeared in how the news articles were categorized. Llama tends to place articles into broader, more general categories, while Mistral is more specific and assigns articles to narrower categories. This difference in categorization leads to inconsistencies between the two models, making it difficult to compare their results directly. The way each model handles categorization also raises concerns about how well they understand the context of the articles. If a model doesn’t categorize the articles correctly, it could affect the overall analysis and lead to less reliable conclusions. This highlights the importance of choosing the right approach for categorizing information to ensure accurate results.
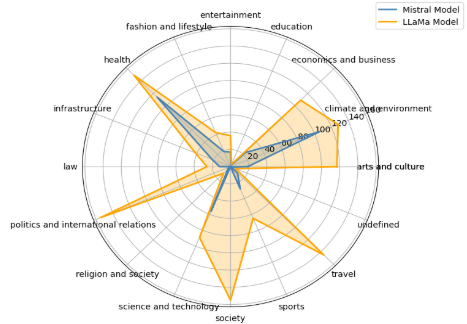
Figure 6 : Comparison of Llama and Mistral's categorization of articles
2. Inconsistency in Keywords Selection Between ModelsKeywords help us understand the choice of concepts and theories within a model. The distinctly different selection of keywords by the models, reflecting their differences in contextual categorization, reveals how they interpret concepts and theories. For Llama, the first keywords selected are “Colonial Legacy”, “Political Legitimacy”, and then “Tourism Cultural Heritage”. In contrast, Mistral prioritizes “Climate Change” and “Sustainability”. These differences not only highlight the models’ varying interpretations but also suggest that each model places emphasis on different societal issues, reflecting their unique understanding of the topics at hand.
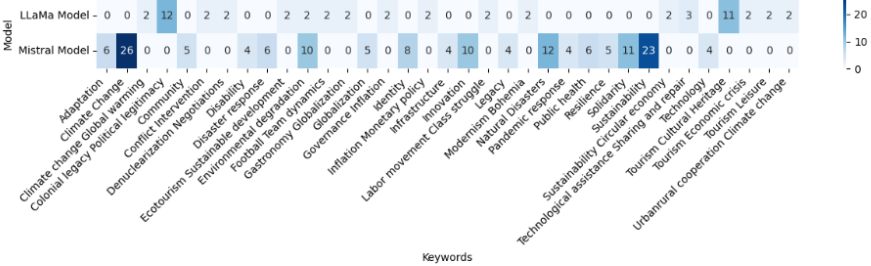
Figure 7. Top 20 Frequent Keywords in Each Database
3. Consistency between authors and conceptsThere’s a consistent selection of authors and concepts in the models, reflecting their lexical strength. Mistral frequently features “Risk Society” and Goffman’s theory, whereas Llama often includes Bourdieu’s “Cultural Capital” and “Habitus”.
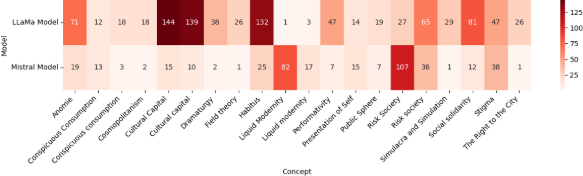
Figure 8. Occurrences of common concepts in Both Databases (Top 20)
ConclusionThe two previous models showed that they mainly cited well-known general sociologists such as Pierre Bourdieu, Erving Goffman and Ulrich Beck. However, the amount of quotations from these authors depends on the different models: Mistral seems to concentrate more on Ulrich Beck, Erving Goffman and Pierre Bourdieu, while Llama seems to quote more from Pierre Bourdieu, Emile Durkheim and Erving Goffman. Ulrich Beck appears at the bottom of the list of authors cited, even though his theories on the sociology of risk and reflexive modernity could be entirely appropriate for analysing the various articles on current events.
In terms of sociological concepts, only 20 common sociological concepts were cited out of a total of 547 sociological concepts. 193 were listed by Mistral and 334 by Llama, who seems to associate sociological concepts rather well according to the keywords used to analyse the news articles.
Task 3
In the third section of our analysis, we delve into the divergences in theoretical approaches adopted by various large language models (LLMs), underscoring the significant variations and preferential orientations that distinguish each model.
Prevalence of Qualitative Methods: Interviews and ethnography are recognized as the most utilized qualitative methods across the three models. Mistral distinctively highlights comparative analyses, suggesting a unique focus not observed in other models. Notably, quantitative methods are seldom mentioned.
Diversity in Theoretical Approaches: Open-source models such as Qwen predominantly favor Critical Theory, whereas proprietary models like GPT show a preference for Constructivism, and Claude leans towards Structuralism. Mistral, however, presents a more balanced distribution of theoretical approaches.
Influence of Sociological Theories: Generally, models do not exhibit variation in theory preference based on the topic, except for Mistral, which more frequently associates topics of 'Identity and Diversity' and 'Family and Life Course' with Marxist and Interactionist theories.
Bias in Model Responses: Adversarial testing on Qwen, which exhibits a pronounced bias towards Critical Theory, demonstrates that even altering descriptions in the prompt does not shift the model's preference, indicating that such biases are deeply ingrained in the training data.
Insights on Model Size and Bias: Contrary to common assumptions, larger models do not necessarily display more balanced decision-making. Additionally, there is no discernible pattern of cultural biases among American models like Claude, GPT, and Llama. Mistral is noteworthy for its balance and diversity in theoretical approaches, which suggests that biases are likely rooted in the training datasets.
For further details, the complete report of Task 3 is available here.
6. Discussion
Task 1
This project underscores the varying degrees of accuracy and diversity in recommendations generated by different LLMs. The inputs in German and French consistently result in lower accuracy and diversity, pointing to potential gaps in language-specific training resources. Interestingly, despite English being the primary language of development for many models, it does not consistently deliver the highest accuracy, prompting further scrutiny into the adequacy of sociological references within the training corpora.
The prevalent bias towards recommending well-known Western sociologists such as Pierre Bourdieu and Manuel Castells highlights a significant limitation within the training datasets, which tend to overlook non-Western scholars and perspectives. This not only perpetuates dominant academic narratives but also underscores the critical need for more diverse and comprehensive training materials. Although models like Gemma strive to mitigate these biases by offering a wider array of recommendations, this diversity sometimes sacrifices accuracy, with recommendations occasionally including non-relevant or non-academic figures. The apparent diversity in Gemma's recommendations raises important questions about whether it truly diminishes representational bias or merely shifts it towards favoring less scholarly or pertinent contributors.
These observations carry important implications for both researchers and developers. Enhancing training datasets to encapsulate a broader spectrum of sociological views is crucial for diminishing biases and augmenting the pertinence of model outputs. Researchers are advised to approach LLM outputs with a critical eye, ensuring thorough scrutiny to validate accuracy and relevance. Optimizing models for language-specific performance could also address discrepancies in output quality, especially for underrepresented languages like German and French. Additionally, achieving a balance between accuracy and diversity remains a pivotal focus in model development; while diversity is essential for reducing representational bias, it must not compromise the outputs' relevance to the scholarly domain.
In summary, while LLMs possess considerable potential as tools within academic research, their present limitations in terms of accuracy, diversity, and inherent biases highlight an urgent need for ongoing improvements in training and model development strategies. Addressing these challenges will not only enhance the utility of LLMs in scholarly contexts but also foster a more equitable and inclusive academic discourse.
Methodological Reflections
Our approach contributes to the development of sociology-specific LLM benchmarking by focusing on a key dimension—LLMs’ ability to suggest relevant scholars for research topics. Through this evaluation, we highlight:
-
How LLMs interpret sociological topics
-
Their potential biases in recommending scholars (e.g., prioritization of Western theorists)
-
The role of language in shaping scholarly references
However, our study has limitations. We focused only on scholar recommendations, whereas LLMs could be used in sociology for broader applications such as computational social science. Additionally, our attempted topic classification was inconclusive, and our model selection was limited to five LLMs, meaning results may not generalize to all models. Finally, as LLMs evolve rapidly, our findings represent a snapshot in time rather than definitive conclusions.
Despite these challenges, our methodology provides a structured foundation for future research, offering insights into how LLMs engage with sociological content and highlighting the need for continued refinement in evaluating their scholarly outputs.
Task 2
The differences between Llama and Mistral highlight key issues in using artificial intelligence for sociological analysis, particularly regarding source and reference selection. Llama adopts a more consistent approach, associating sociological concepts with themes such as “Colonial Legacy” and “Political Legitimacy”, reflecting a deeper understanding of historical and political dynamics. In contrast, Mistral emphasizes contemporary topics like “climate change” and “sustainability”, which may align with current debates but could overlook more foundational sociological concepts.
The inconsistency in article categorization and keyword selection suggests that Llama uses a classical theoretical framework, while Mistral incorporates more contemporary criteria. This difference in methodology influences results, as overly broad or narrow categories may lead to biased interpretations by favoring certain perspectives.
These discrepancies do not undermine the validity of each model but highlight biases in data selection and sociological interpretation. The criteria used for selecting authors, concepts, and keywords directly impact the orientation of analyses. If these criteria are poorly defined or biased, they can affect the relevance of the conclusions drawn, illustrating the importance of clear and balanced models for sociological analysis. Other aspects may have led to bias or were not noticed in our analyses and results. Notably with regard to the origin and popularity of authors chosen by LLMs to analyse news facts. Another critical point that we missed was the plurality of LLMs selected. Only were retained: Llama and Mistral. This is what we will cover in this section
1. Choice of sociological authors 1. OrigineThe two LLMs used in Task 2 of this project are LLaMa developed in the United States, and Mistral, from France. Since our study focuses on sociological biases, it is relevant to question whether the origin of the chosen sociologist and that of the LLM used could introduce a bias. As highlighted by Karën Fort and Aurélie Névéol in their work (Ethics and NLP: 10 years after, ATALA, 2024), these factors can influence the results produced.
To further explore this issue, we could have extracted the origins of the sociological authors identified by the LLMs by automating their retrieval via Google. These data could then have been added to our database in a dedicated column. Correlation analyses, particularly through matrix visualizations, would have allowed us to assess whether there is a link between the authors' origins and the LLM that identified them. Such an approach could have provided valuable insights into potential biases in the selection of references based on the origin of the model used.
2. PopularityAnother potential bias in our study concerns the selection of sociologists by LLMs based on their popularity. Indeed, the same current event can be analyzed from different theoretical perspectives, and multiple sociologists may have developed similar approaches. However, some researchers specialize in specific fields, making their work more relevant for analyzing certain events than that of authors who have only published a few books or articles on the topic.
LLMs, however, may rely on quantitative criteria to determine the "best" sociologists, primarily based on the number of publications and their academic visibility. This could favor the most prolific or widely cited authors, potentially overlooking other contributions that might be more pertinent but less recognized.
To delve deeper into this issue, we could have scraped data from Google Scholar to collect:
-
The total number of works written by the sociologists identified by the LLMs.
-
The total number of citations of these works.
These two variables could have been combined to establish a popularity score for each author. A sociologist with numerous widely cited publications would receive a high score, whereas one with fewer publications and citations would have a lower score. However, it would also be crucial to account for cases where an author has published only a few works but has been highly cited, indicating a significant academic impact despite limited output.
Finally, we could have conducted correlation analyses between this popularity score and the LLMs' selections to assess whether a sociologist’s academic visibility influences their likelihood of being chosen to analyze current events, and to what extent this bias affects the generated results.
2. Few LLMs testedFinally, another bias in our project concerns the number of LLMs tested. We focused on LLaMA (developed in the United States by Meta) and Mistral (developed in France), whereas several other models could have enriched our analysis, such as Gemini, Claude Sonnet, DeepSeek, and ChatGPT.
-
Gemini, developed by Google DeepMind in the United States, is particularly strong in multimodal reasoning, integrating text, images, and audio, and excelling in the comprehension of complex documents.
-
Claude Sonnet, designed by Anthropic (United States), specializes in long-context language modeling, providing nuanced understanding, better handling of extended dialogues, and a strong focus on safety and ethical AI alignment.
-
ChatGPT, developed by OpenAI (United States), is known for its versatility and ability to generate detailed and well-contextualized responses. It excels in creative writing, code generation, and advanced contextual understanding.
-
DeepSeek, developed in China, is designed to handle large volumes of textual data, with a strong emphasis on research and information analysis. It is particularly effective for in-depth searches and analytical responses.
Integrating these additional LLMs could have provided even more diverse results, allowing us to cross-analyze perspectives and examine potential differences in the selection of sources and sociologists. While the results obtained with LLaMA and Mistral are already highly relevant, comparing them with a broader range of models would have enriched our study and provided deeper insights into the biases specific to each LLM, considering their origin, training data, and areas of specialization.
Task 3
The findings of this research highlight key insights into the capabilities, limitations, and biases of Large Language Models (LLMs) in the context of sociological research. One of the most striking observations is the prevalence of qualitative methods, particularly interviews and ethnography, in the models’ classifications. This suggests a possible alignment with dominant trends in contemporary sociology but also raises concerns about potential biases in dataset representation. The relative underrepresentation of quantitative approaches, despite their established presence in the field, could indicate either gaps in training data or the models’ preference for recognizing certain methodologies over others.
A significant issue emerged with the score method, which was tested and subsequently abandoned due to hallucinations. Its use demonstrated that a generative intelligence generates responses even in the absence of data. Fact-checking revealed that in some cases, a score of 5 (the highest level) was assigned despite the complete absence of any mention of the method in the corresponding abstract. After a series of tests and prompt modifications to assess its performance, it was concluded that none of the models were capable of handling this information accurately, leading to the abandonment of the methodology.
A major methodological challenge also emerged when analyzing theoretical frameworks. Different models exhibited strong biases toward specific epistemological traditions, such as Qwen’s emphasis on Critical Theory, GPT’s preference for Constructivism, and Claude’s inclination toward Structuralism. The results of adversarial testing suggest that these tendencies are not solely a function of the prompt but are deeply embedded within the training corpora. This underscores the influence of pre-existing data structures and model architectures in shaping AI-generated responses.
Regarding the analysis of theoretical frameworks, one of the emerging hypotheses related to the polarization of results suggests that when encountering certain specific words, LLMs automatically assigned a corresponding label, rather than engaging in a more interpretative or philosophical reading of the text. While in the analysis of research methods, LLMs had the opportunity to identify key terms and infer the methodology accordingly, the task of recognizing theoretical approaches proved to be more complex. Even though LLMs were provided with a list of theoretical frameworks as a reference, they produced widely divergent interpretations, failing to apply a more nuanced analysis of the text.
Additionally, our findings challenge common assumptions about model size and diversity of outputs. While proprietary models such as Claude and GPT operate with significantly larger datasets and computational resources, they do not necessarily yield more balanced results. On the contrary, smaller open-source models like Mistral demonstrated a more even distribution of theoretical approaches, suggesting that scale alone does not guarantee epistemological plurality.
Beyond methodological considerations, this study raises fundamental epistemological questions. To what extent do LLMs reflect existing biases in academic knowledge production? Are these biases a function of AI design, or do they mirror deeper structural inequalities within academia itself? The fact that non-Western and marginalized sociological traditions were often overlooked by the models indicates an urgent need for a more inclusive and diversified approach to training data selection.
Finally, the study also reveals a practical tension between the utility of LLMs as research assistants and their inherent limitations. While these tools can effectively classify and summarize sociological texts, their interpretative capabilities remain constrained. The reliance on correlation rather than deep understanding means that LLMs often reinforce dominant paradigms rather than critically engaging with alternative perspectives.
7. Conclusion
The overall conclusion of the workshop is that all AI models tested display different behavior regarding classification, identification and author recommendation for sociological research. From what we hypothesised and tested, the differences in behaviors and outputs from the selected LLMs are numerous, and show limitations in the efficiency and reliability of AI models usage for research in the humanities.
From Task 1, we found that the LLMs tested show different arrays of diversity when it comes to sociological authors recommendation, with some prioritizing a select list of authors, and others displaying a larger set of names. While conceding that Pierre Bourdieu is a prominent author for sociology, he might not be the most relevant author for selected subjects. The same goes for Michel Foucault, Anthony Giddens, Erving Goffman or Manuel Castells. A second level of analysis shows that the language used to prompt also changes the outcome of our demands, and not necessarily prioritizing the authors from the language which the model was prompted. For example, when prompting Claude in German, it cited Pierre Bourdieu almost twice as much compared to in French. Additionally, some models have been shown to hallucinate author names, thus showing the unreliability and inconsistency of AI models in author recommendation, regardless of the LLM and the language in which it was prompted.
From task 2, it was shown that while Llama and Mistral were able to make coherent connections between new articles, sociological concepts, sociologists and key words, both displayed different behaviors and outcomes, with only 20 concepts in common. Llama demonstrates a certain consistency between the areas of knowledge and the selection of keywords, while tending to over-cite certain authors such as Pierre Bourdieu. Mistral, on the other hand, highlights authors such as Ulrich Beck and gives less importance to Émile Durkheim and Pierre Bourdieu. The two models show inconsistencies in the selection of authors and in the categorisation of articles. In addition, the study shows little agreement between the models regarding the selection of sociological concepts, with Llama identifying a significantly higher number than Mistral, although Llama associates these concepts with greater consistency. These differences not only highlight the models’ varying interpretations but also suggest that each model places emphasis on different societal issues, reflecting their unique understanding of the topics at hand. These discrepancies highlight the importance of considering the potential biases of the models and the way in which they interpret and structure sociological information.
Finally, task 3 reveals divergences in theoretical and methodological approaches for the different LLMs tested. Qualitative methods, such as interviews and ethnography, were favored, while quantitative methods were rarely mentioned. Except for Mistral, other models displayed a bias towards certain theoretical approaches, showing that the scale of the model alone does not guarantee epistemological plurality. Moreover, adverse testing has revealed biases that are deeply rooted in the training data, and not just related to prompts. These findings underline the need for a critical approach when using these tools in sociological research, as well as the need to diversify training data to mitigate bias.
Overall, in accordance with what has already been shown in research about political biases in different LLMs, this study highlights the variability in how different LLMs engage with knowledge related to humanities and sociology, particularly in author recommendation, concept selection, key-word association and methodological orientation. The tests designed to challenge the selected models might have been different across all tasks, but we were able to make significant discoveries that might help shape more reliable tests in the future. Across the tasks, we found that LLMs prioritize certain authors, concepts, and methodological approaches inconsistently, over-representing some while omitting others. Moreover, linguistic variations in prompting further influence the models' responses, revealing an additional layer of bias and unpredictability. The discrepancies in recommendation and association display that these models do not offer a comprehensive or neutral representation of theories and concepts in sociology, but rather reflect the biases embedded in their training datasets. These findings call for a critical approach to the use of existing LLMs in sociological research. Bearing in mind that the operating principle of text generative AI is based on probabilities, the conclusions we have drawn from this benchmark are not entirely surprising, and in line with our hypotheses and previous research on model bias. We can therefore question the use of generative AI as an appropriate and efficient method for sociological research.
8. References
Burger, Bastian, Dominik K. Kanbach, et Sascha Kraus. 2024. « The Role of Narcissism in Entrepreneurial Activity: A Systematic Literature Review ». Journal of Enterprising Communities: People and Places in the Global Economy 18(2):221‑45. doi: 10.1108/JEC-10-2022-0157.
Burger, Bastian, Dominik K. Kanbach, Sascha Kraus, Matthias Breier, et Vincenzo Corvello. 2023. « On the Use of AI-Based Tools like ChatGPT to Support Management Research ». European Journal of Innovation Management 26(7):233‑41. doi: 10.1108/EJIM-02-2023-0156.
Chang, Yupeng, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, et Xing Xie. 2024. « A Survey on Evaluation of Large Language Models ». ACM Transactions on Intelligent Systems and Technology 15(3):1‑45. doi: 10.1145/3641289.
Choudhary, Tavishi. 2025. « Political Bias in Large Language Models: A Comparative Analysis of ChatGPT -4, Perplexity, Google Gemini, and Claude ». IEEE Access 13:11341‑79. doi: 10.1109/ACCESS.2024.3523764.
Dwivedi, Yogesh K., Nir Kshetri, Laurie Hughes, Emma Louise Slade, Anand Jeyaraj, Arpan Kumar Kar, Abdullah M. Baabdullah, Alex Koohang, Vishnupriya Raghavan, Manju Ahuja, Hanaa Albanna, Mousa Ahmad Albashrawi, Adil S. Al-Busaidi, Janarthanan Balakrishnan, Yves Barlette, Sriparna Basu, Indranil Bose, Laurence Brooks, Dimitrios Buhalis, Lemuria Carter, Soumyadeb Chowdhury, Tom Crick, Scott W. Cunningham, Gareth H. Davies, Robert M. Davison, Rahul Dé, Denis Dennehy, Yanqing Duan, Rameshwar Dubey, Rohita Dwivedi, John S. Edwards, Carlos Flavián, Robin Gauld, Varun Grover, Mei-Chih Hu, Marijn Janssen, Paul Jones, Iris Junglas, Sangeeta Khorana, Sascha Kraus, Kai R. Larsen, Paul Latreille, Sven Laumer, F. Tegwen Malik, Abbas Mardani, Marcello Mariani, Sunil Mithas, Emmanuel Mogaji, Jeretta Horn Nord, Siobhan O’Connor, Fevzi Okumus, Margherita Pagani, Neeraj Pandey, Savvas Papagiannidis, Ilias O. Pappas, Nishith Pathak, Jan Pries-Heje, Ramakrishnan Raman, Nripendra P. Rana, Sven-Volker Rehm, Samuel Ribeiro-Navarrete, Alexander Richter, Frantz Rowe, Suprateek Sarker, Bernd Carsten Stahl, Manoj Kumar Tiwari, Wil Van Der Aalst, Viswanath Venkatesh, Giampaolo Viglia, Michael Wade, Paul Walton, Jochen Wirtz, et Ryan Wright. 2023. « Opinion Paper: “So What If ChatGPT Wrote It?” Multidisciplinary Perspectives on Opportunities, Challenges and Implications of Generative Conversational AI for Research, Practice and Policy ». International Journal of Information Management 71:102642. doi: 10.1016/j.ijinfomgt.2023.102642.
Karën Fort, Aurélie Névéol. Ethics and NLP: 10 years after. Journée d’études ATALA ”éthique et TAL : 10 ans après”, 2024. hal-04533870
Motoki, Fabio, Valdemar Pinho Neto, et Victor Rodrigues. 2024. « More Human than Human: Measuring ChatGPT Political Bias ». Public Choice 198(1‑2):3‑23. doi: 10.1007/s11127-023-01097-2.
Additional references
Christou, Prokopis. 2023. « Ηow to Use Artificial Intelligence (AI) as a Resource, Methodological and Analysis Tool in Qualitative Research? » The Qualitative Report. doi: 10.46743/2160-3715/2023.6406.
Davidson, T. (2024). Start Generating: Harnessing Generative Artificial Intelligence for Sociological Research. Socius, 10. https://doi.org/10.1177/23780231241259651
Dellermann, Dominik, Adrian Calma, Nikolaus Lipusch, Thorsten Weber, Sascha Weigel, et Philipp Ebel. 2021. « The future of human-AI collaboration: a taxonomy of design knowledge for hybrid intelligence systems ».


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
BenchmarkLLM-1.pdf | manage | 4 MB | 09 Feb 2025 - 22:29 | JustineXu | |
| |
BenchmarkLLM-2.pdf | manage | 6 MB | 09 Feb 2025 - 22:29 | JustineXu | |
| |
BenchmarkLLM-3.pdf | manage | 4 MB | 09 Feb 2025 - 22:29 | JustineXu |
Ideas, requests, problems regarding Foswiki? Send feedback