It's Giving AI: exploring and investigating generative AI aesthetics
Team Members
Facilitators: Houda Lamqaddam, Gabriel Pereira, Kwan Suppaiboonsuk
Participants: Larissa Akemi, Haoyuan Tang, Rishika Rai, Meng Liang, Teresa Liberatore, Lisa Plumeier, Christian Bitar Giraldo, Alice Picco, Emma Garzonio, Chufan Huang, Nicoletta Guglielmelli
Contents
- Team Members
- Contents
- 1. Introduction
- 2. Initial datasets
- 3. Research Questions
- 4. Methodology
- 5. Findings and Discussion
- 5.1 Week 1
- 5.2 Week 2
- 5.2.1 Concept or Language: What is lost in AI image generation?
- 5.2.2 The Ghost of the Default Aesthetics: Exploring GenAI ’s Affordances and Limitations
- 5.2.3 Finding play within communities: Playful interactions with generative AI
- 5.2.4 Generative AI in Narrative Games: Impact, positive aspects and limitation through case studies
- 6. Conclusions
- 7. References
1. Introduction
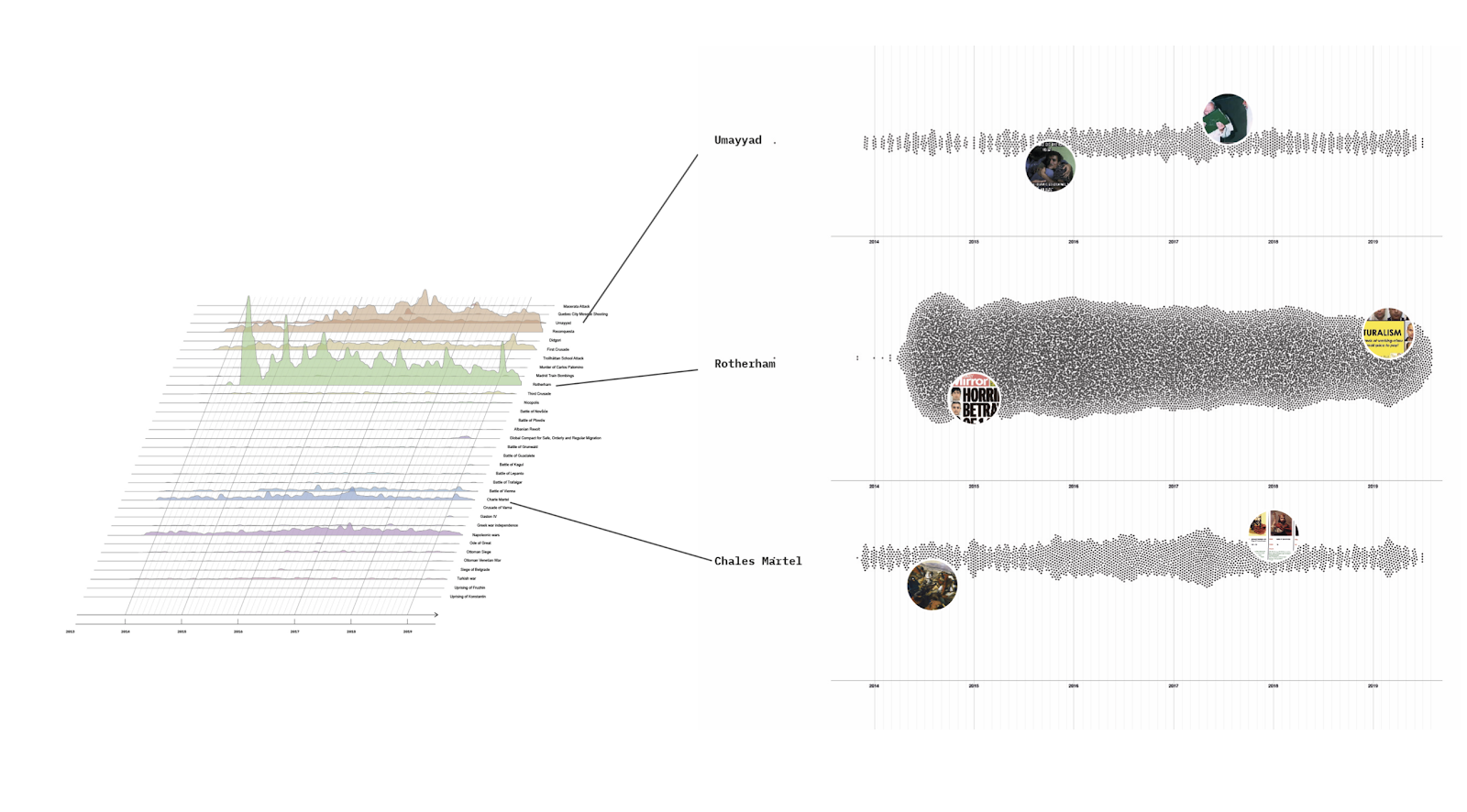
The hype around Generative AI (GenAI) is taking the world by a storm. Controversies abound in the media around how these technologies may change our relation to creative and cultural labor. An example of this has been the outcry over the use of GenAI in book covers, and how this would devalue the work of illustrators and other artists. Despite these issues, online communities of artists and practitioners have been cropping up around GenAI image generation and its tools/platforms. For example, the AIArt subreddit has 250k members and the #AIArt tag on Instagram has over 14 million posts.
This project sought to understand the aesthetic characteristics of GenAI images posted in such online communities. It was developed in two steps: in the first week, we used digital methods to analyse AI art images and their aesthetic characteristics. These results informed our work on the second week, which involved investigating how these images redefine our conception of creativity and how they are intrinsically connected to the tools/platforms' affordances.
In this final report, we present the outcome of the several sub-projects that emerged from this intensive research.
2. Initial datasets
Data on Generative AI images and communities were scraped from various web platforms (Reddit, Instagram, and Facebook) to serve as an initial starting point.
Provided datasets for Reddit are for the AIArt and Midjourney subreddit, retrieved from The Pushshift Reddit Community Archive (Baumgartner et al., 2020). as a .zst compression of ndjson files. For each community, two separate ndjson files are provided: one for all submissions, another for all comments. Some data descriptors were selected and further processed into a csv file for analysis on 4CAT (Peeters & Hagen, 2022). Descriptors initially identified as relevant for the project were fields like image url, title of submission, and name of submission (which serves as a unique id to identify comments linked to the submission). Depending on the sub-research questions, other fields like upvote count and score are also used in analysis.
Scraped using a script on Chrome DevTools, this dataset captures the official Midjourney community on Facebook and contains up to 30,000 images. Dataset descriptors are image url, post url, and alt text provided for image.
Datasets from Instagram represent not only communities, but also individual creators, which were selected due to the stylistic variations and the amount of AI generated images posted. Posts are scraped using Zeeschuimer and brought into 4CAT for analysis. Relevant descriptors are image url, caption text, and post link. Coincidentally, some of the creators are also educators with activity on YouTube, LinkedIn, and own blogs. These were used to perform qualitative analysis for some of the subquestions.
AI-generated
Beyond the initial datasets stated above, to investigate some of the subquestions, some datasets were also created using image generation across different platforms, including Midjourney and Stable Diffusion.
3. Research Questions
The project departed from two sets of research questions, one for each week of the Summer School:
Week 1: What are the particular aesthetic characteristics (form, content, style) of GenAI images? How do these characteristics inform our understanding of the new conditions of creativity in GenAI times? How are computational methods limited in their understanding of GenAI aesthetics?
Week 2: How are the GenAI aesthetic characteristics related to particular algorithmic affordances/platforms/tools? How are these aesthetics related to particular digital community practices?
Each of these were further developed into sub-research questions that were specific to each sub-project.
4. Methodology
In the first week, we explored data using computational/digital methods techniques to analyze both the images (using computer vision), and the accompanying posts and communities (Rogers 2019). We complemented this quantitative approach with a qualitative exploration and reflection on the image aesthetics, as well as the discourse of artists.
To build the data sets, we conducted scraping using 4CAT (Peeters & Hagen, 2022) and Zeeschuimer (Peeters, 2022). We then used 4CAT and other digital methods tools for visualizing networks and patterns across the data. We also used newly implemented 4CAT functions for computer vision analysis using different commercial algorithms (e.g. Clarifai and Google Cloud Vision).
In the second week, our exploration of GenAI aesthetics continued using a variety of qualitative and computational methods. We investigated how communities of practice and platform affordances shape image production, but also with analysis of the outputs of different prompts (Munn et al., 2023). We also experimented with analysis of game design and other digital methods.
5. Findings and Discussion
The group split across the two weeks into sub-groups. Each subgroup developed different research investigations. Each subgroup worked on a different research question, which built upon the project's overarching goals. Here, we present each sub-project, including its findings and a short discussion based on it.5.1 Week 1
5.1.1 The development of faces in Gen AI
Sub-research question: How does the development of and discourse around Generative AI affect the representation of faces between 2022 and 2024?
This research focused on the development of AI generated images by investigating the development of the creation of faces over a period of 3 years (2022-2024). We followed the content of 3 popular “AI Art” creators & educators (@julian_ai_art, @jennatwitsend, @stelfiett) through their Instagram, YouTube, LinkedIn, and personal blogs. These creators were chosen because they were both AI artists and educators, exemplifying a trend of artists taking to social media to educate others on how to use AI prompts and Photoshop. To trace the discourses around the developments in the technology, we supplemented this corpus with material from the blogs of different GenAI developers, such as Midjourney, Stable Diffusion, and DALL-E. The project aimed to understand how ”upgrades” in generative AI led to particular image aesthetics for portraits (e.g. photorealistic) but also to trace the discourse around new features.
The main finding is that there is a complex interplay between GenAI technologies, the AI art creators, and their communities. We have identified a trend over 2022-2024: first, towards replicating well-known faces; second, toward more photorealistic images; third, creating storytelling across face replication. The AI artists' process is a back-and-forth between tools such as Photoshop and GenAI models. However, at the same time, artists/educators discuss how new features (e.g. Character Reference) can be adopted for creativity. Across the different actors' discourse, there is a focus on generative AI to support the creative storytelling process. What this creativity discourse misses, however, are the emerging political and ethical debates around these tools.

The full poster is available here.
Discussion
Through this research, we can determine that not all artists rely solely on AI-generated images to create "clean" artworks, but rather use a combination of tools such as AI-generated technology, Photoshop, and photos to create more realistic images. Through this process, AI artists defend themselves as "artists who use GenAI as a 'tool' to create artworks."
From a technical development perspective, of the models used by creators (DALL-E, Stable Diffusion, and Midjourney), Midjourney is the only one that has developed features specifically for creating portraits based on its model development. Midjourney's advanced algorithms focus on capturing fine details and nuances of facial features, allowing for a higher level of realism and personalization in portrait art. The emphasis on portraiture allows artists to create images that are not only visually stunning but also emotionally engaging, capturing the essence of a subject that was previously difficult to capture using traditional methods.
Furthermore, the integration of these tools demonstrates a significant evolution in the artistic process, with the line between human creativity and machine support blurring. Artists are now freer to experiment with new styles, techniques, and compositions, pushing the boundaries of creativity while maintaining control over the end result. The synergy between human intuition and generative AI technology fosters a collaborative environment where new forms of expression can flourish, ultimately expanding the possibilities of art in the digital age.
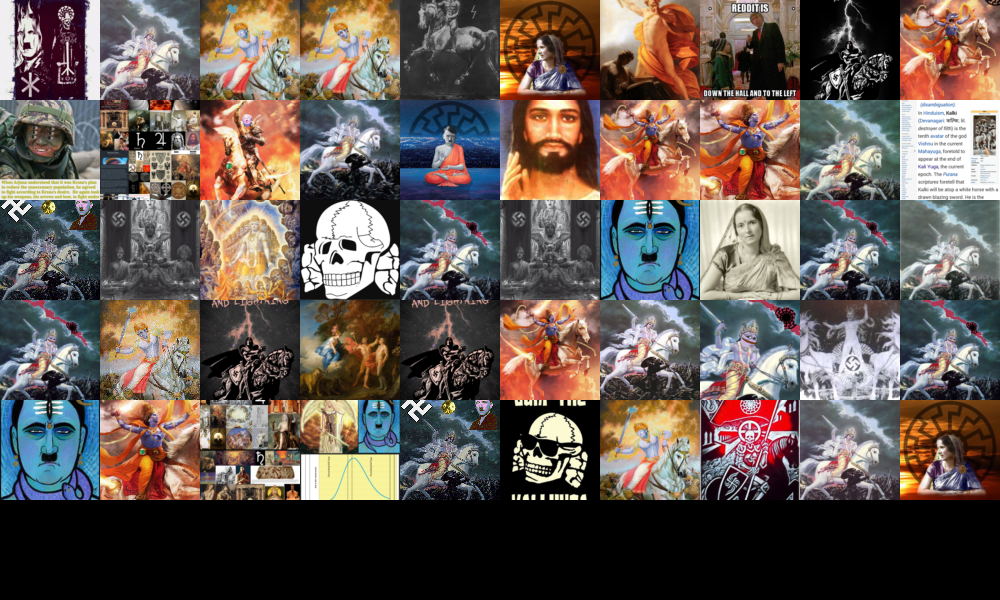
5.1.2 What can we see from AI-generated images depicting impossible things?
Sub-research question: What can we see from AI-generated images that depict impossible things?
This project explored the nature and impact of AI-generated "impossible" images. The first section utilises a qualitative analysis to identify the unique traits that make these images "impossible." Inspired by the viral AI-generated picture of Pope Francis in a Moncler puffer jacket, the research focuses on the concept of impossibility within AI-generated imagery. By leveraging ChatGPT to formulate prompts and Stable Diffusion to produce images, the project examines how AI constructs alternate realities featuring celebrities and well-known personalities in fantastical, implausible contexts.
Impossible images that go viral provide valuable insights into what people are curious about or want to see. These images capture the public's imagination and reveal trends in cultural and social interests. They also highlight the extent to which AI can blur the lines between reality and fiction, which can have significant implications. For the untrained eye, these images might appear real, leading to potential consequences such as the spread of misinformation and fake news. The ability of AI to create convincing yet impossible scenarios necessitates a critical approach to media consumption and emphasises the importance of media literacy in discerning fact from fiction.
This project was conducted by generating a list of prompts depicting "possible representations of impossible realities," including influential or popular people. For example, the viral image of Pope Francis in a duffle jacket served as inspiration. These prompts were then used to generate a batch of images with Stable Diffusion. The generated images were positioned on a Cartesian axis where the y-axis indicates the degree of impossibility, and the x-axis indicates adherence to the prompt. It is important to note that these metrics are subjective, and the interpretation of impossibility and adherence can vary among viewers. By analysing these AI-generated images, the project aims to understand the characteristics that make an image seem impossible and to explore the broader implications of such images in media and society.
The final section explores the use of such images as prompts for generating narratives and fictional worlds. This involves creating detailed descriptions of landscapes, entities, and cultural constructs that defy real-world logic, ultimately analysing these narratives to understand how AI expands the boundaries of creative storytelling. The narratives were examined for complexity and coherence, considering how well they integrated the impossible elements into a logically consistent world within the narrative framework. Taking the generated world "Virelia" as an example, the narrative of Virelia showcases a high level of complexity and coherence, integrating the impossible elements of the world seamlessly into a logically consistent story. The AI generated a narrative where Liora’s interactions with the Skywhales, guided by the spiritual and ecological constructs of Virelian society, underscore the depth of world-building achieved. This analysis examines how elements such as the Skywhales' bioluminescence and the symbiotic relationships within the ecosystem are woven into the plot, reflecting the AI's capacity to create intricate stories from unconventional prompts. The project explores how AI-generated imagery depicts 'impossible' scenarios and the potential for using AI to create narratives that push the boundaries of the imagination.

The full poster is available here.
Discussion
This project on AI-generated "impossible" images has provided valuable insights into the intersection of artificial intelligence and human perception. It has showcased the capabilities of AI in creating images that challenge our understanding of reality while also revealing its limitations in grasping physical laws and cultural contexts.Our analysis highlighted the subjective nature of interpreting "impossibility." What one person finds implausible may seem realistic to another, emphasising the influence of individual experiences and cultural backgrounds. The potential for misuse of these convincing yet fabricated images raises important ethical concerns, particularly regarding misinformation and public manipulation.
The viral nature of certain impossible images reflects collective cultural fascinations and can shape trends in art and media. As the line between real and AI-generated imagery blurs, there is an increasing need for media literacy and critical thinking skills to navigate this evolving landscape. This research aimed to highlight the importance of interdisciplinary approaches, combining insights from computer science, psychology, and cultural studies. Ultimately, the project not only illuminates the current state of AI image generation but also prompts us to consider its broader implications for our perception of reality and the future of visual communication. As AI technology advances, ongoing studies like this will be essential in addressing the challenges and opportunities it presents.
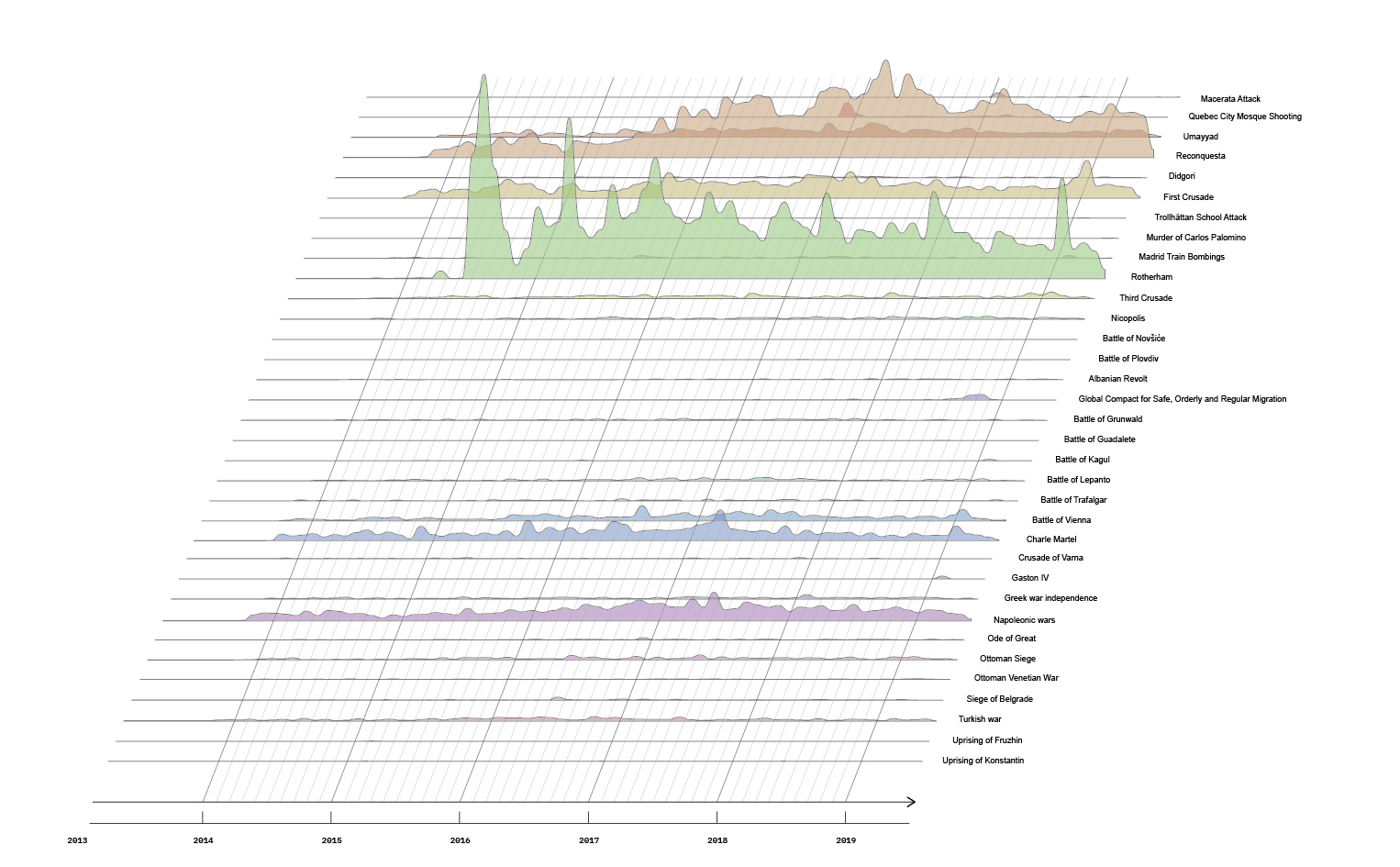
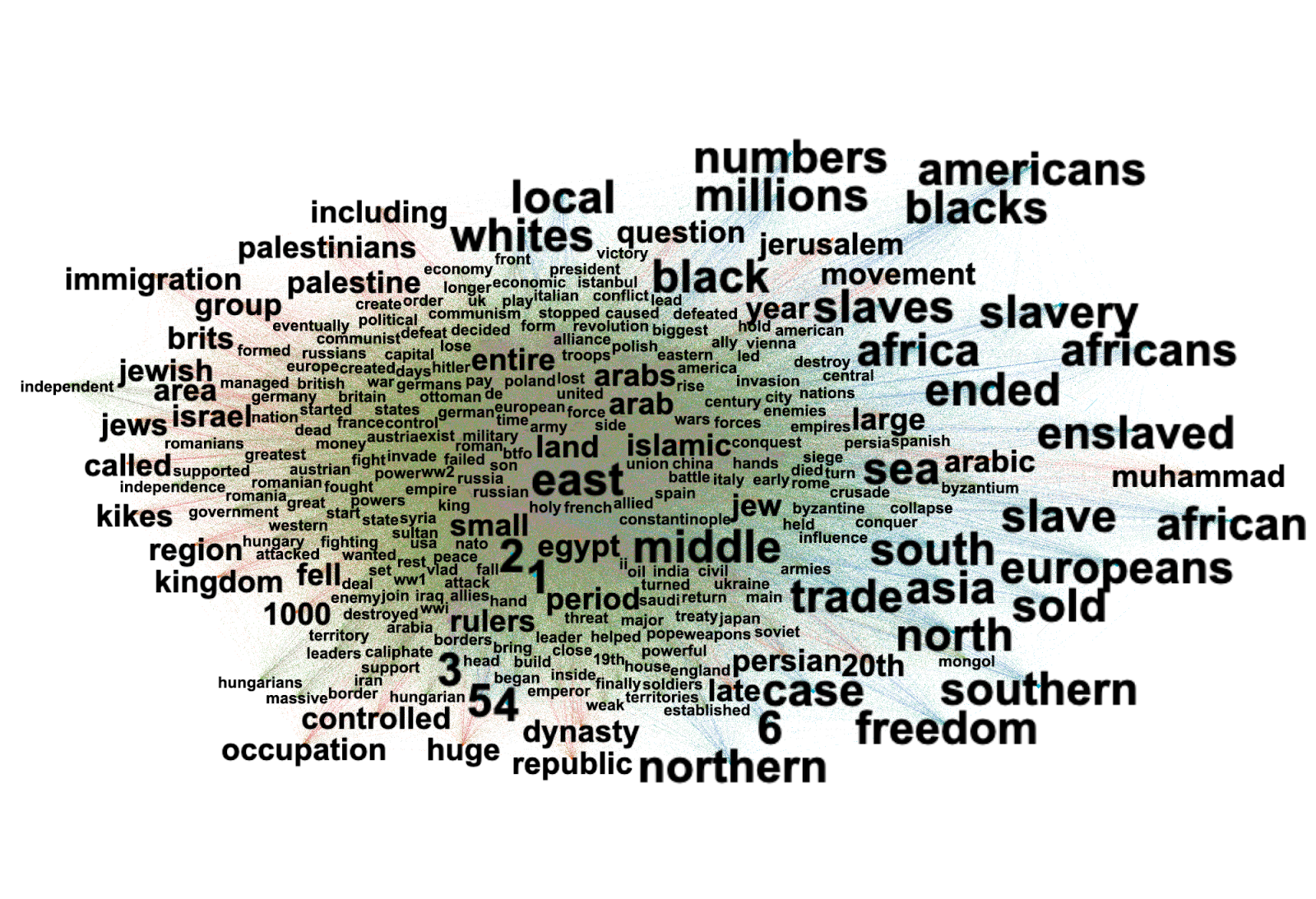
5.1.3. Understanding AI-generated image popularity on the Midjourney subreddit
Sub-research question: What are the elements or icons that make an AI-generated image popular on Reddit?
This study explored the dynamics of AI-generated image popularity on Reddit's Midjourney subreddit. While our initial goal was to identify definitive patterns in popular and unpopular posts, our process revealed the complexity of this task. We developed a custom popularity metric and used advanced tools like Google Vision API and OpenAI 's BLIP2 for image analysis. Our preliminary findings, with a dataset of 520 images, suggested that popular posts tend to feature broader concepts (eg 69% of images have the label "sky", 47% have "smile", 39% have "happy"), while less popular posts often contain more specific elements, mainly related to facial features (eg. 15% have "chin" and "forehead", 13% have "lip"). However, due to dataset limitations and the inherent subjectivity of image popularity, we couldn't draw strong conclusions. The study highlights the challenges in quantifying aesthetic preferences for AI-generated content on Reddit.
For future research, we recommend expanding the scope to include a larger dataset of images. Additionally, incorporating more qualitative methods such as discourse analysis could provide insights into how these images are perceived and received by viewers. To better understand the relationship between visual aesthetics and image reception, future studies could employ visual rhetoric analysis or semiotics. These approaches, combined with a larger and more diverse dataset, would offer a more comprehensive understanding of the factors influencing the popularity of AI-generated images in the Midjourney subreddit, and the methodology could be expanded to other platforms.

The full poster is available here.
Discussion
Exploring the aesthetic of images generated with AI text-to-image models comes hand in hand with the exploration of what makes them likeable within a human audience. Are there common patterns among images liked the most? Are they different from the patterns of the least liked ones? Our findings suggest that the Midjourney subreddit audience likes AI-generated images representing broader concepts more than other content. However, further research is needed to develop stronger conclusions.
5.2 Week 2
5.2.1 Concept or Language: What is lost in AI image generation?
Sub-research question: How do the most popular text-to-image models deal with multilingual prompts, when asked to generate photos of politicians? Does using different languages carry any cultural cue in the image generation?
The field of generative artificial intelligence (GenAI) has seen extensive research focused on its capabilities and limitations, particularly in handling multilingual prompts and cultural representation. The study by Spennemann (2024) on GenAI models' impact on cultural heritage management underscores the importance of accurately capturing and representing cultural nuances, which is essential in political contexts where visual cues can shape public discourse. The persistence of stereotypes in AI-generated images, as revealed by the ViSAGe project (Lin et al., 2024), raises concerns about the reinforcement of cultural biases through generative models. These findings emphasise the need for critical evaluation and refinement of training data and algorithms to ensure that AI-generated images do not perpetuate harmful stereotypes, particularly in politically sensitive portrayals.
Furthermore, (Cooper & Tang, 2024) identified stereotypical elements in AI-generated science education imagery, stressing the importance of scrutinising AI outputs to avoid reinforcing outdated or biased representations. This concern is equally pertinent in the realm of political communication, where the accurate and nuanced depiction of political figures is essential for maintaining cultural integrity and avoiding the perpetuation of stereotypes. In the context of multilingual prompts, the study by (Yang et al., 2024) found that straightforward prompting strategies yield the best results. This insight is crucial for optimising the generation of culturally appropriate political portraits in multiple languages, ensuring that the resulting images align with the cultural and linguistic context intended by the prompts.
Overall, these studies highlight the complexities involved in generating culturally and politically nuanced images using AI. They underscore the importance of ongoing research and development to enhance the cultural and conceptual accuracy of AI-generated images, particularly in the politically charged domain of visual communication.
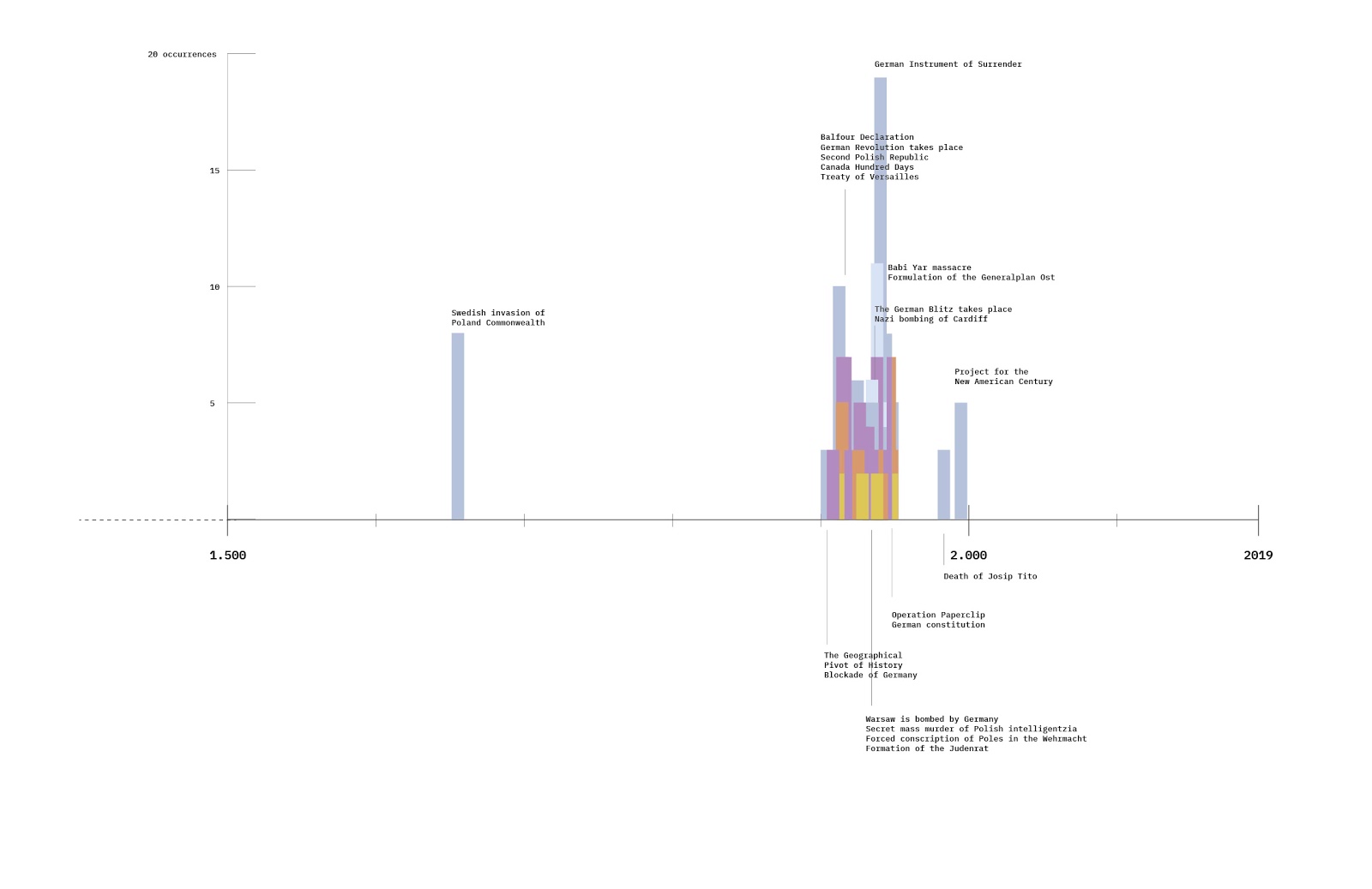
This research represents an exploration of how different text-to-image models generate political portraits in Italy, China and the Netherlands, using multilingual prompts, and investigates whether using different languages carries any cultural cues in image generation.
The study compared the performance of three generative AI models (OpenAI /Dall-E, MidJourney, and Stable Diffusion) when prompted in English and native languages (Italian, Chinese, and Dutch). When prompting in English, the models were required to generate a country-specific political image: "Photo of a [Chinese / Italian / Dutch] politician", while when using the three native languages the prompt only required a “Photo of politician” (Foto di un politico, Foto van politicus, 政治家的照片) with no further country-specific cue other than the language itself.Each prompt was standardized across languages and models to ensure consistency. For each combination of country, language, and model, 12 images were collected, resulting in a dataset of 108 images.
Through qualitative analysis, the visual representations generated by each model were compared to assess the impact of language and cultural context on genAI images. Reverse-image search on a subset of particularly representative items allowed us to trace back some benchmark images, showing the potential use of iconic and country-specific imagery in training datasets.
Other relevant findings addressed structural differences between the 3 models, mainly in relation to:
-
Language: prompting in native languages, Dall-E tends to overlook the language factor, while SD and MJ detect the linguistic dimension but fail to generate content that is consistent with the prompt's request;
-
Visual formats: homogeneous visual structure for Dall-E’s images, showing male figures and iconic country-specific architecture, with a detectable trend of USA/Western feature representation, while SD and MJ recall more “artistic” and “photographic” imagery;
-
Cultural cues: SD and MJ respond to country-specific cues by generating images that explicitly recall historical politicians and iconic imagery of the different countries (e.g. black and white neorealistic Italian movies, Chinese art)

The full poster is available here.
Discussion
Being the “political portrait” historically rooted in and incorporating the iconic traits of the surrounding visual culture, it proves to be an interesting case study for the analysis of the (potential) alignment between language and cultural representation in GenAI images. It allowed for an interesting investigation of each model’s adherence to and deviation from local visual cultures and iconic imagery.
Reflecting on the findings of this project, it becomes evident that the aesthetic characteristics of GenAI are closely related to the specific algorithmic affordances, platforms, and tools. These aesthetic traits not only reflect the technical capabilities of the models but also align with particular digital community practices. Stable Diffusion and MidJourney, for instance, can recognize and incorporate linguistic elements to some extent; however, the content they generate often diverges from the expected cultural context. Their outputs tend to be more artistic and photographic, showcasing historical and iconic representations of the specified cultures. This suggests that these models may have been trained on a diverse and in-depth range of visual materials, resulting in a broader visual style in their generated images. In contrast, DALL-E produces more uniform and consistent images, failing to capture linguistic nuances but providing stable visual outputs. This could be due to a more uniform training dataset or an algorithm that standardises visual representation when handling multilingual prompts.
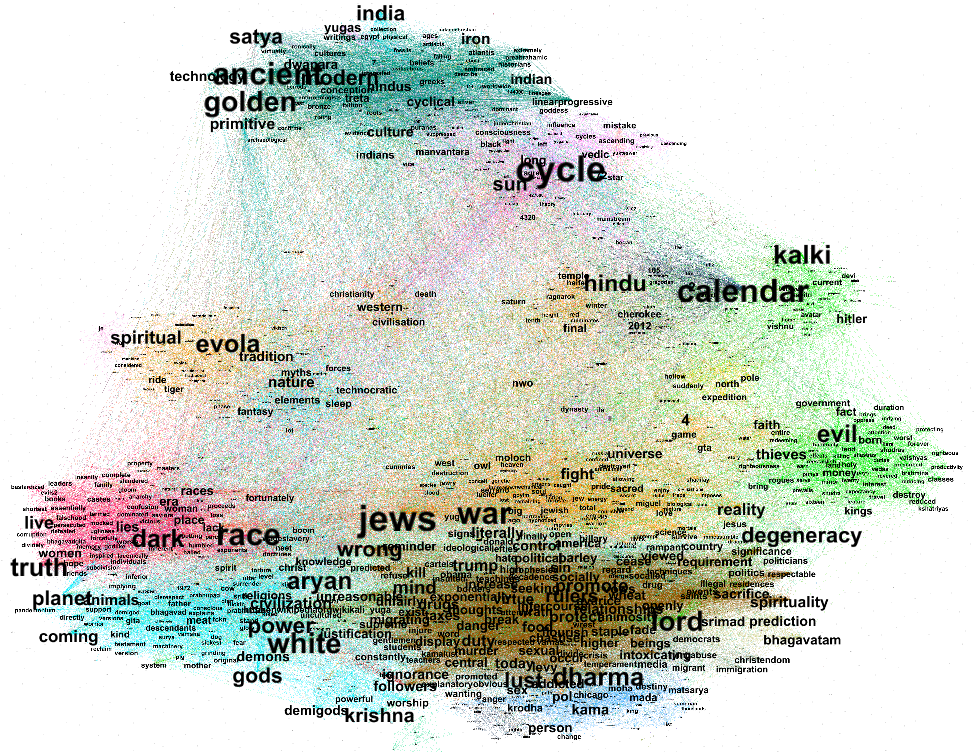
5.2.2 The Ghost of the Default Aesthetics: Exploring GenAI ’s Affordances and Limitations
Sub-research questions: How do users pin down the aesthetics and affordances of GenAI models by working with or against them?
This research focused on the affordances and aesthetics of different GenAI models that are being used in the AIArt communities. As a follow up to week 1, we traced AI generated images by investigating the content of the same three “AI Art” creators & educators (@julian_ai_art, @jennatwitsend, @stelfiett) on Instagram, Youtube and their personal websites. We combined a close reading of the three accounts, their work, and their interactions with their community into three different explorations of the field. First, we collected discursive elements to better understand the creators’ and communities’ sensemaking of their interactions with the models. Second, we used these observations in combination with the creators’ shared prompts to test out the models based on our findings. Third, we focused on the models’ capabilities to create consistent character storytelling. Through this process, we traced the models’ contributions to the creators’ processes and gained insights on the complex back-and-forth interplay of GenAI and its users. At the same time, the observations helped us to collect and try out implications about the perceived “default” aesthetic the models carry.

The full poster is available here.
Discussion
Our results show that the complex back-and-forth process of AI creators, models and communities is hinting towards a default aesthetic that all of the models’ are carrying. By tracing the additional tools that the creators use and following the actions found in their discourse we were able to show that the models - when isolated in image generation - are still carrying aesthetic stereotypes linked to social variables of beauty, age, race, and gender. Following creators’ work and trying to recreate their process can be a valuable method to understand the relationship between the model and the artwork.
By tracing the additional tools that the creators use, following their actions and looking into the suggestions given by their followers we were not just able to show that models when isolated in image generation are still carrying aesthetic stereotypes, but also how creators and their followers try and navigate (or even resist) these aesthetics.
5.2.3 Finding play within communities: Playful interactions with generative AI
Sub-research question: How do online communities engage playfully with generative AI tools?
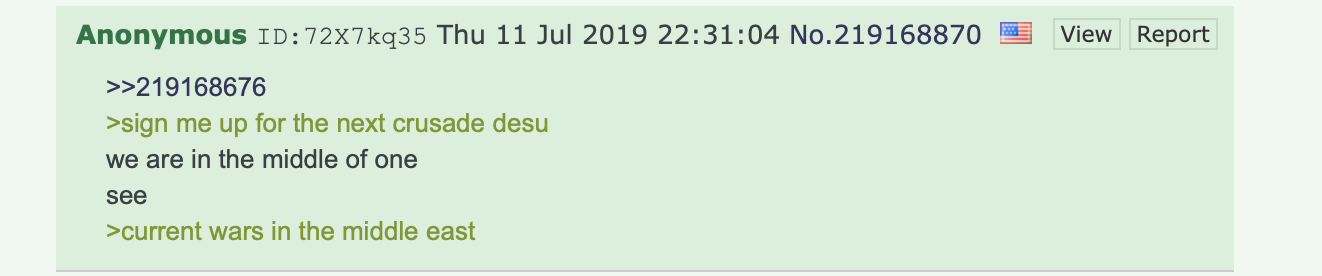
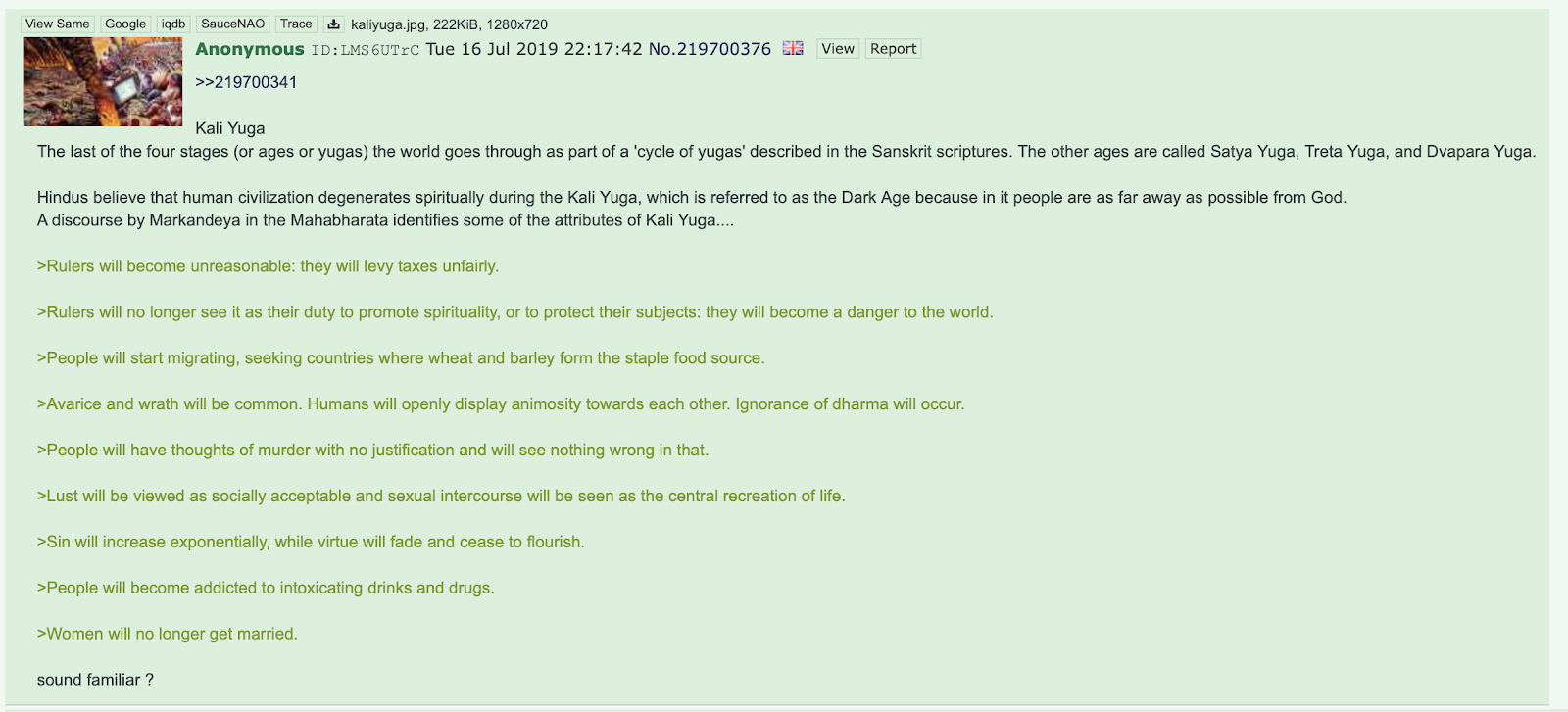
This study examined playful interactions with generative AI tools in online communities, focusing on two key phenomena: 'Is this AI?' and 'How do I make this?'. The first involves users attempting to discern AI-generated content, reflecting societal unease with AI advancements. The second describes users seeking specific prompts to replicate desired AI-generated images, transforming online forums into virtual marketplaces for AI instructions. These behaviours demonstrate how AI tools are reshaping online discourse and creative processes, blending curiosity, scepticism, and a desire for creative control.

The full poster is available here.
Discussion
The relevance of this study lies in its exploration of societal reactions to generative AI, specifically through two key behaviours: “Is this AI?” and “How do I make this?”. Users frequently question whether content is AI-generated, judging the authenticity of the art and the creator. This scrutiny, embodied in the phrase "Is this AI?", highlights a collective concern over AI advancements and their impact on the perception of reality. The trend of users asking "How do I make this?" reveals a shift towards leveraging AI to achieve specific visual outcomes, indicating a reliance on AI, maybe to compensate for a lack of certain skills, seeking shortcuts to achieve desired outcomes.
Both behaviours display a relationship with AI tools, where people seek to demystify technology while also leveraging it to enhance their own capabilities. We’re seeing a societal adaptation to AI, where users leverage these tools to bridge their creative abilities, reshaping how content is generated, perceived and integrated into daily life.
5.2.4 Generative AI in Narrative Games: Impact, positive aspects and limitation through case studies
Sub-research question: How can generative AI change the gameplay and the narrative in games?
This research explored the implications, benefits and limitations of using generative AI in narrative video games. Through two distinct case studies—AI Dungeon and 1001 Night—the study explores how generative AI can transform traditional gameplay into dynamic, creative, and exploratory experiences. Each case study highlights the capabilities of AI to foster an environment of playfulness by enhancing narrative flexibility, user agency, and the generation of interactive content. The findings underscore the potential of generative AI to promote an exploratory and enjoyable environment and contribute to a sense of playfulness.
The case study of “AI Dungeon” explores how generative AI enables unique narrative experiences that allow more possibilities and player agency than the “traditional” interactive narrative structures used in video games. It aims to understand how these experiences foster environments that promote engagement through imaginative storytelling and interaction. The playful interaction is assessed by examining the branching and diversity of the stories, the player’s freedom to influence and create within the game, and unpredictability of the narrative experience.
The case study of "1001 Night" aims to explore the experimental deployment of AI in gameplay. In this game, the objective is predetermined and fixed for players, while the Generative AI (GenAI) serves as a tool to help players achieve this goal. The integration of AI enhances the gaming experience by providing dynamic assistance and innovative solutions to challenges within the game, showcasing the potential of AI in interactive entertainment.
Qualitative narrative analysis and content analysis was employed to analyse the narratives generated by the games to check the frequency and patterns of narrative flexibility, player agency, and narrative coherence. Analyse the differences between the narrative structures in generative-AI-driven games like AI Dungeon and the narrative structures of traditional text adventure games like Zork (Infocom, 1977). The analysis identified three main features and differences:
1. Narrative Flexibility and Branching
The narrative in AI Dungeon is generated in real-time through AI, which allows for a highly flexible narrative structure. This means that the game can create and modify storylines based on any input provided by the player, leading to unpredictable and varied narrative outcomes that were not explicitly programmed by developers. Traditional text adventure games typically have a set number of predetermined paths and endings. These games are built on a branching narrative structure where players' choices lead them down different paths, but each of these paths is pre-written and has a finite number of outcomes. This structure limits flexibility but ensures narrative coherence and tight control over the storytelling experience.
2. Player Agency and Interaction
In AI Dungeon, player agency is maximised because the AI can respond to nearly any text input. This means that players can engage with the game world in highly creative and personalised ways. In traditional text adventure games, player interaction is constrained to a set of predefined choices or commands. Players need to type the correct keywords to trigger the answers and keep the game going. Player agency is thus structured and bounded by the game’s design, which can limit creativity but provides a more controlled narrative experience.
3. Narrative Coherence and Consistency
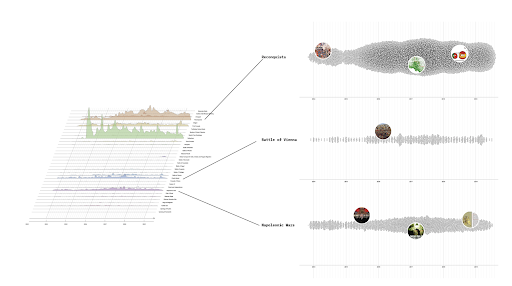
AI Dungeon sometimes produces responses that are contextually irrelevant or inconsistent with previous narrative elements. This can lead to disjointed story experiences where the flow and logic of the narrative may be compromised. But sometimes the fun comes from unexpected "broken" stories (figure 3). Traditional text adventures tend to have better narrative coherence and a consistent storyline, with clear development and resolution of plot elements. The controlled environment ensures that the narrative remains coherent.
Finally, we developed an experimental game, Liminal. The experience of the game asks: How may we think of prompting as a continuously unfinished and ever-elusive process? What if we keep AI at the stage of liminality? How does the scale of GenAI change our relation to creativity? These questions can be reflected in the design of the game, and also in the discussions it generated.
The full poster is available here.
Discussion
The two case studies illustrate the two primary ways GenAI can be deployed in commercial digital games. Firstly, GenAI can be integral to developing core gameplay elements, particularly in narrative and storytelling. The specific application of GenAI varies: it can either be the gameplay itself, driving exploration and adventure, or it can serve as a tool to achieve specific objectives within the game. In the latter case, GenAI supports the player in reaching predefined goals by enhancing the gameplay experience. The choice of deployment depends on the intended player experience and the game's design goals.
However, there are limitations to the use of GenAI in digital games. One significant challenge is the controllability of the generative AI results. Ensuring that the AI-generated content aligns with the game's design vision and maintains a high quality can be difficult. Additionally, players' interactions with the game can sometimes exploit or "hack" the generative system, leading to unintended outcomes or breaking the immersive experience. Balancing creative freedom and control over AI-generated content is crucial to prevent these issues and ensure a seamless, engaging player experience.
6. Conclusions
This intensive research enabled a diverse, multi-faceted exploration of Generative AI aesthetics. Returning to the larger research questions we started, we found that there was plenty of nuance in the aesthetic characteristics of these images. Different projects demonstrated and tested some of the different tactics that creators use to generate their images—from using the affordances of the existing tools to wrangling a diversity of non-AI software. Considering the wide usage of GenAI, we found that it is important to focus on specific communities or approaches—for example the "impossible images", the AI creator/educators, or specific games. Different projects also used multiple forms of prompting, however we often found it difficult to fully situate the generated results considering the opacity of some platforms and their settings (e.g. DALL-E).
Ultimately, this project shows the importance of further research in this field. Each project demonstrated that there were many understudied elements of Generative AI aesthetics. There are many different dimensions which can be combined to influence the aesthetics used by creators—including the artistic process itself, but also the platforms and models used, combinations of prompts/styles, or even the communities. There is a lot to still be broken down to actually define what GenAI aesthetics are, or if there are any overarching ones—giving plenty of room for future projects.
Future research can, for example, further apply digital methods to other (specific) AIArt communities, in order to understand and compare their different approaches/aesthetics. This research would also benefit from more closely engaging with the artists/creators themselves in order to fully represent (and understand) their methods. Finally, though we tested out several GenAI models for image generation, we did not fully unveil their infrastructure for this project—leaving plenty of room for future analysis of these GenAI pipelines and their influence in the aesthetics.
7. References
Aesthetics of Photography (25 July 2024) Unveiling the Digital Canvas: Exploring AI-Generated Images through Philosophical and Aesthetic Perspectives. Aesthetics of Photography. https://aestheticsofphotography.com/ai-generated-images-philosophical-aesthetic/
Arctic Shift Project. (2024, July 10). Datasets for subreddits r/AIArt, r/ChatGPT, r/MidJourney, and r/StableDiffusion. Retrieved from https://arctic-shift.photon-reddit.com/download-tool
Baumgartner, J., Zannettou, S., Keegan, B., Squire, M., & Blackburn, J. (2020, May). The pushshift reddit dataset. In Proceedings of the international AAAI conference on web and social media (Vol. 14, pp. 830-839).
Cooper, G., & Tang, K.-S. (2024). Pixels and Pedagogy: Examining Science Education Imagery by Generative Artificial Intelligence. Journal of Science Education and Technology, 33(4), 556–568. https://doi.org/10.1007/s10956-024-10104-0
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., & Ramanan, D. (2024). Evaluating Text-to-Visual Generation with Image-to-Text Generation (arXiv:2404.01291). arXiv. https://doi.org/10.48550/arXiv.2404.01291
Munn, L., Magee, L., & Arora, V. (2023). Unmaking AI Imagemaking: A Methodological Toolkit for Critical Investigation (arXiv:2307.09753). arXiv. http://arxiv.org/abs/2307.09753
Peeters, S., & Hagen, S. (2022). The 4CAT capture and analysis toolkit: A modular tool for transparent and traceable social media research. Computational communication research, 4(2), 571-589.
Peeters, S. (2022). Zeeschuimer (version 1.10.1) [Computer software]. Digital Methods Initiative. 10.5281/zenodo.11258763
Rogers, R. (2019). Doing digital methods. SAGE.
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crowson, K., Schmidt, L., Kaczmarczyk, R., & Jitsev, J. (2022). LAION-5B: An open large-scale dataset for training next generation image-text models (arXiv:2210.08402). arXiv. https://doi.org/10.48550/arXiv.2210.08402
Spennemann, D. H. R. (2024). Will Artificial Intelligence Affect How Cultural Heritage Will Be Managed in the Future? Responses Generated by Four genAI Models. Heritage, 7(3), Article 3. https://doi.org/10.3390/heritage7030070
Yang, A., Li, Z., & Li, J. (2024). Advancing GenAI Assisted Programming—A Comparative Study on Prompt Efficiency and Code Quality Between GPT-4 and GLM-4 (arXiv:2402.12782). arXiv. https://doi.org/10.48550/arXiv.2402.12782


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback