Mapping, Tracking, and (Re)Making of the Counter-Imaginaries of AI across the Web
poster1-websites ; poster2-wikipedia ; poster3-twitter ; poster4-linkedin
Team Members
Participants: Barbora Bachanová, Max Casey, Anastasia (Ray) Dolitsay, Chen Fan, Roosmarijn Hompe, Julia Krönert, Nora Rado, Benedetta Riccio, Iara Schiavi, Xenia Sikora, Zhiyi Xie, Qingyu Yang, Mattia Zanotti
Facilitators: Natalia Stanusch, Richard Rogers
Contents
Summary of Key Findings
This project set off with two main research goals: first, to repurpose digital methods across a selection of platforms to track AI imaginaries; and second, to reassemble these AI imaginaries. While exploratory both in the concept and method, this project consists of a total of four case studies that achieve the above-mentioned research goals with attention to platform vernaculars, specificities, and limitations. The first case study, focused on a selection of websites related to AI, used a relational qualitative and quantitative analysis of keywords and images to reveal major imaginaries that AI actors perform through their websites. The second case study, on Wikipedia, reconstructed AI imaginaries which had been shaping the Wikipedia article on artificial intelligence, while also tracking the evolution of these imaginaries through time. Both Twitter and LinkedIn case studies used the firing of Sam Altman from OpenAI as an entry point to map the clash of imaginaries. X/Twitter case study treated X/Twitter as a discourse space to map out the dominant voices, focusing on retweets as an expression of the X/Twitter vernacular. LinkedIn case study focused on hashtags but also mentions of Sam Altman across a sample of posts of various actors. Here, different imaginaries were tracked in the aspirational LinkedIn space that Altman materializes.
We note that the dominant AI imaginary, present in all four case studies, is a corporate imaginary, where seeming neutrality pairs with techno-optimism and is shared among closely aligned clusters of actors. We argue that AI imaginaries and counter-imaginaries assembled in this project tend to reflect the vernacular of a specific platform or digital ecology (LinkedIn, Websites), as well as the positioning of the dominant actors within a given network cluster (X/Twitter, Wikipedia). Nonetheless, we also found openings for counter-imaginaries within the spaces we surveyed, especially visible in absences of particular issues or voices that we observe as blank spots on the AI imaginary map.
1. Introduction
Sociotechnical imaginaries, or imaginaries that concern specifically the entanglements of science, technology, and society, are not entirely new, but rather have penetrated societies and industries for centuries. For Sheila Jasanoff and Sang-Hyun Kim, sociotechnical imaginaries are “assemblages of materiality, meaning, and morality that constitute robust forms of social life. (…) [They] can be articulated and propagated by other organized groups, such as corporations, social movements, and professional societies” (Jasanoff and Kim 2013; 2015). Sociotechnical imaginaries enact various approaches, visions, and ideas on the same sociotechnical issues. In this project, we built off Jasanoff and Kim’s notion that sociotechnical imaginaries are “collectively held, institutionally stabilized, and publicly performed visions of desirable futures” (2015, p. 322), and we further define imaginaries as constructed out of a set of elements (such as words, aesthetics, objects, images), that are not necessarily of this moment (that is, are future-oriented), and which envisage effects or uses based on shared understandings that concur to a formulation of a tangible but evolving fields of fears, hopes, and possibilities.
Sociotechnical imaginaries today seem to be diffuse and inchoate in comparison with other historical imaginaries that were consolidated by and controlled by institutions, like Christian doctrine in the Middle Ages. The state of digital communication itself, widespread, diffuse, pervasive, and decentralized, seems to defy our sense of who is controlling the discourse or the direction of the sociotechnical imaginaries. But that sense of diversity and decentralization is not as impenetrable as it seems. AI is a centralized industry. This is not a surprise, but an inevitable outcome of the merger mania of Silicon Valley in which big players like Meta, Google, Microsoft, Apple, and Amazon bought up dozens and hundreds of small technological companies and consolidated their internet oligarchy.
As the AI Now Institute put it in a recent report, “there is no AI without the Big Tech” (Kak & West, 2023). The significance of the relatively centralized AI industry is that however different the Big Tech players may be, they have interests in the same regulatory policies and narratives. These are “visionaries,” apparently, with a cyclopean vision. However, there are alternatives to Big Tech’s vision already present. We can therefore make visible those exhibiting counter-proposals to AI developments and alternative paths that could be taken right now, instead of solely focusing on what Big Tech wants us to focus on. Thus, this project aimed to map the dominant imaginaries, counter-imaginaires, as well as possible new spaces of alternatives to Big Tech’s visions and narratives.
Imaginaries are made, therefore, it is possible to trace the labor of their making. To do so, this project took inspiration from Actor-Network Theory, STS, and controversy mapping (Venturini & Munk, 2021; Rogers et al., 2015) in tracing (counter-)imaginaries of AI. It is a response to critically study the concentration of power behind the political economy of AI (Bode & Goodlad, 2023), as well as to broaden the understanding of cultural forces that shape AI industry (Kak & West, 2023). While tracking the dominant imaginaries, the four case studies paid particular attention to presences and absences of discourses and issues across imaginaries.
2. Initial Data Sets
Case study: Websites
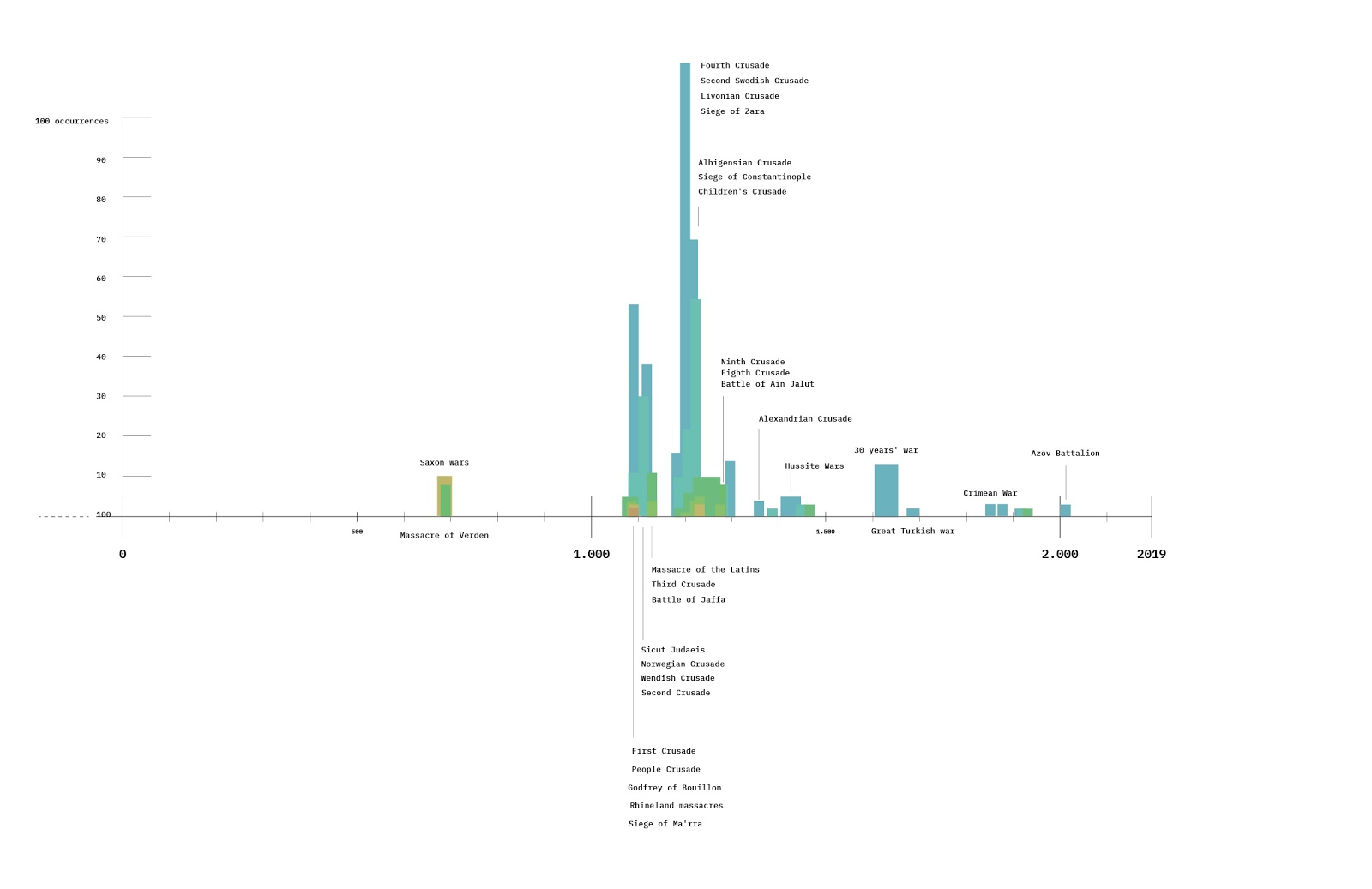
The list of websites was formed by collecting the first fifty results of six Google queries ([AI research], [AI justice], [AI safety], [AI ethics], [AI risk], [AI harms]). Google was chosen as it is the most popular search engine in use. The search was conducted on a research browser, with language set to English and with no VPN. Only organic results were taken into account (no videos, images, Wikipedia, or sponsored results). Following qualitative coding, only websites of AI-related organizations were chosen, which included industry websites, NGOs, governmental pages, and various international organizations. Of the 102 websites compiled, one was not accessible during further research, limiting the dataset to a total of 101 pages.
Case study: Wikipedia
The main source for the Wikipedia dataset was the current and archival versions of the Wikipedia page on ‘Artificial Intelligence.’ Using Wikipedia’s own infrastructure, such as the history of page’s edits, its wiki objects, as well as ‘see also’ pages, Wikipedia data was accessed, scraped, and repurposed using different tools: Contropedia, WayBack Machine, and Seealsology (see Methodology section below for more details).
Case study: X/Twitter
To create a dataset from X/Twitter, a clean research browser was used to create a new account. A random username was created with an online username generator. To get access to the X interface, three interests had to be selected to personalize “what do you want to see on X;” ‘technology,’ ‘science,’ and ‘business and finance’ were chosen. After that, Zeeschuimer was used to scrape tweets. Using a dataset containing a list of AI organizations (see Case study: Websites), from each organization, three X/Twitter accounts of people working in that organization were accessed and scrapped until November 16 (one day before Altman was fired from OpenAI). The accounts were manually searched for within the organization's ‘people’/’about us’ pages, and then by searching for the same names on X/Twitter. This search approach most often targeted the CEOs and managerial positions of most organizations. One has to note that for some organizations no associated people had Twitter accounts, while for others their accounts were private or with no tweets. One also has to note that due to recent X/Twitter restrictions, only a couple hundred tweets can be accessed from a single account a day. However, this restriction is glitchy, and in reality the number of displayed tweets varies and can be somewhat bypassed by reloading the page in longer time intervals. Hence, the scrape had to take place throughout several days (from January 1st until January 7th, 2024) . Once the dataset was completed, the data of over 1700 tweets was uploaded to 4CAT, where ‘filter by value’ processor was used to filter out tweets containing only keywords "Altman" and/or "OpenAI." New dataset had around 280 tweets in total.
Case study: LinkedIn
To create a dataset from LinkedIn, an account had to be made. Clean research browser was used and a research account was made, using an online name and last name generator. One had to further choose several attributes to complete the creation of the account, such as Zone choice (‘Amsterdam, the Netherlands 1012 XT’), the type of qualifications (‘Researcher,’ ‘Freelancer’), and the name of the company one works at (‘Yes’). We assume that it is relevant to mention these choices as they might have, in some capacity, influenced the content that we scraped. Once the account was set, the search function of LinkedIn was used to perform a set of queries. The queries were performed on 14 December, 2023, roughly a month after the firing and rehiring of Altman. The following queries were performed: [Sam Altman], [#samaltman], and [@samaltman]. The “Sort by'' option was set to the default “top match,” while the timeframe was set to “past month.” Once the ‘bottom’ of the results page was reached, another query was performed with the “latest” setting of “Sort by'' function. Zeeschuimer was used to scrape all the posts. The three datasets, containing over 1900 LinkedIn posts in total, were then combined into one dataset.
3. Research Questions
Main research question:
What does the ‘making’ of sociotechnical imaginaries of AI look like, and what query design and research methods can we use to trigger the imaginaries to reveal themselves and become traceable networks?
Sub research questions:
Who are the actors performing AI imaginaries and how do they respond, relate, contest, or reinforce the dominant sociotechnical imaginaries in the context of AI?
How do counter-imaginaries argue with and correspond to the dominant imaginaries?
How can we query to discover counter-imaginaries within dominant ones?
4. Methodology
By utilizing digital methods and tools such as 4CAT (Peeters and Hagen 2022), AI-assisted tools, as well as textual and visual analysis on a selection of the web – over a hundred Websites, Wikipedia, LinkedIn, and X/Twitter – this project reconstructs imaginaries and counter-imaginaries of AI with respect to platform (and, one might say, ‘web’) vernaculars. The following case study-specific methodologies were employed:
Methods for Websites
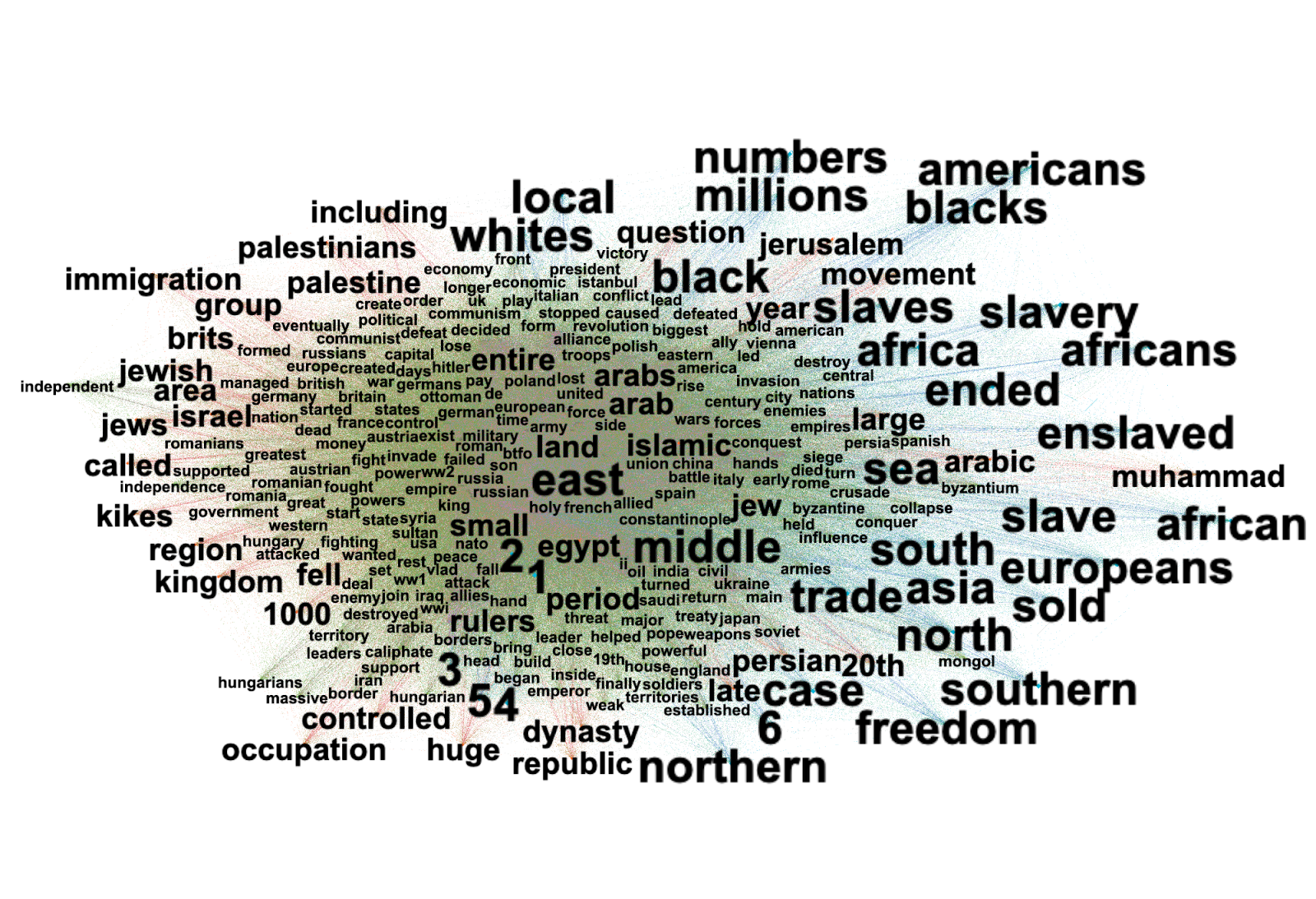
Firstly, the initial list of 101 websites was used to manually access each site to distill keywords-as-issues that each organization highlighted on their page. Once the keywords were distilled, we collectively narrowed down over 800 keywords to a total of 414, while retaining specific issue language as well as unique keywords per each organization. Employing the Lippmannian device, we queried 101 websites through search engine Bing for these keywords, setting the result per query to 1. Here we chose Bing instead of Google because Google is known to require a fill in of CAPTCHAs after a small number of automated queries, which would block the Lippmannian device. The Lippmannian device queries each URL page placed in the source text box for each keyword placed in the keyword box. As some websites in our dataset were repeated, this resulted in a reduction of queried URLs from 101 to 96. The list of all the keywords and their total occurrences per all websites was then uploaded to generate a tag cloud.
Secondly, using Google Chrome extension Instant Data Scraper, images were scraped from each of 101 websites in the initial dataset. Then the images were uploaded into 4CAT in order to group them into visual clusters of similarity using PixPlot visualization tool. PixPlot is a digital humanities tool which relies on Uniform Manifold Approximation and Projection (UMAP), “a dimensionality reduction technique (…) that seeks to preserve both local clusters and an interpretable global shape” (DHLab, nd). PixPlot uses image-recognition to locate objects within the image and categorize them into clusters based on visual similarity. Next, we performed participatory mapping of the space by annotating the images together (Niederer & Colombo, 2019) for the collective imagination of alternative versions of the issues under study (Colombo, 2018). Thus, a qualitative visual analysis was employed to then perform a relational analysis between the clusters of images to keywords. By this, we respected actors’ language in the issue space while relating it to their visual programs. Then, we conducted an inductive analysis to derive posteriori themes from the data. To ensure coder reliability, all authors independently coded clusters-keywords relations. We refined our codes until a consensus was reached.
Methods for Wikipedia
To use Wikipedia’s ‘Artificial Intelligence’ article as data source for reassembling and tracking AI imaginaries, Wikipedia’s infrastructure was accessed through several tools: Contropedia, Wikipedia’s own interface, WayBack Machine, and Seealsology. We begin with a premise that Wikipedia articles are intrinsically unstable and thus, as Contropedia makes visible, Wikipedia articles can provide insights into various societal controversies (Borra et al, 2015, p. 196; Borra et al, 2021, p. 711). Contropedia is a tool which maps Wikipedia’s articles as spaces of controversy, where the most edited wiki objects (that is, the content linked to within the architecture of Wikipedia) in the page are measured as controversy pointers across the history of an article's existence. Thus, Contropedia served us as an assist in a qualitative analysis of a Wikipedia article (Contropedia does not measure all the edits within sections, paragraphs, or sources as it is focused on wiki objects). The map of controversies that Contropedia provided us with was closely analyzed and annotated, and served as a guide in further close-reading of the edit history of Wikipedia’s article on AI.
An ethnographic content analysis and coding was employed for the mapping imaginaries. Once we established an initial coding scheme and hierarchy of controversies based on Contropedia, a qualitative close-reading followed. At this stage, we focused on a narrower timeframe of content analysis, comparing two versions of Wikipedia’s AI article: one from November 28th, 2022 - the last version edited before ChatGPT was released publicly - and the current version (January 10th, 2024). We focused on coding changes and edits that would allow us to, first, map how the release of ChatGPT changed the way Wikipedia's AI article arranges itself, and, second, how these changes fit into AI imaginaries scheme. When we reached data saturation, we visualised the imaginaries and counter-imaginaries in the form of a dendrogram graph.
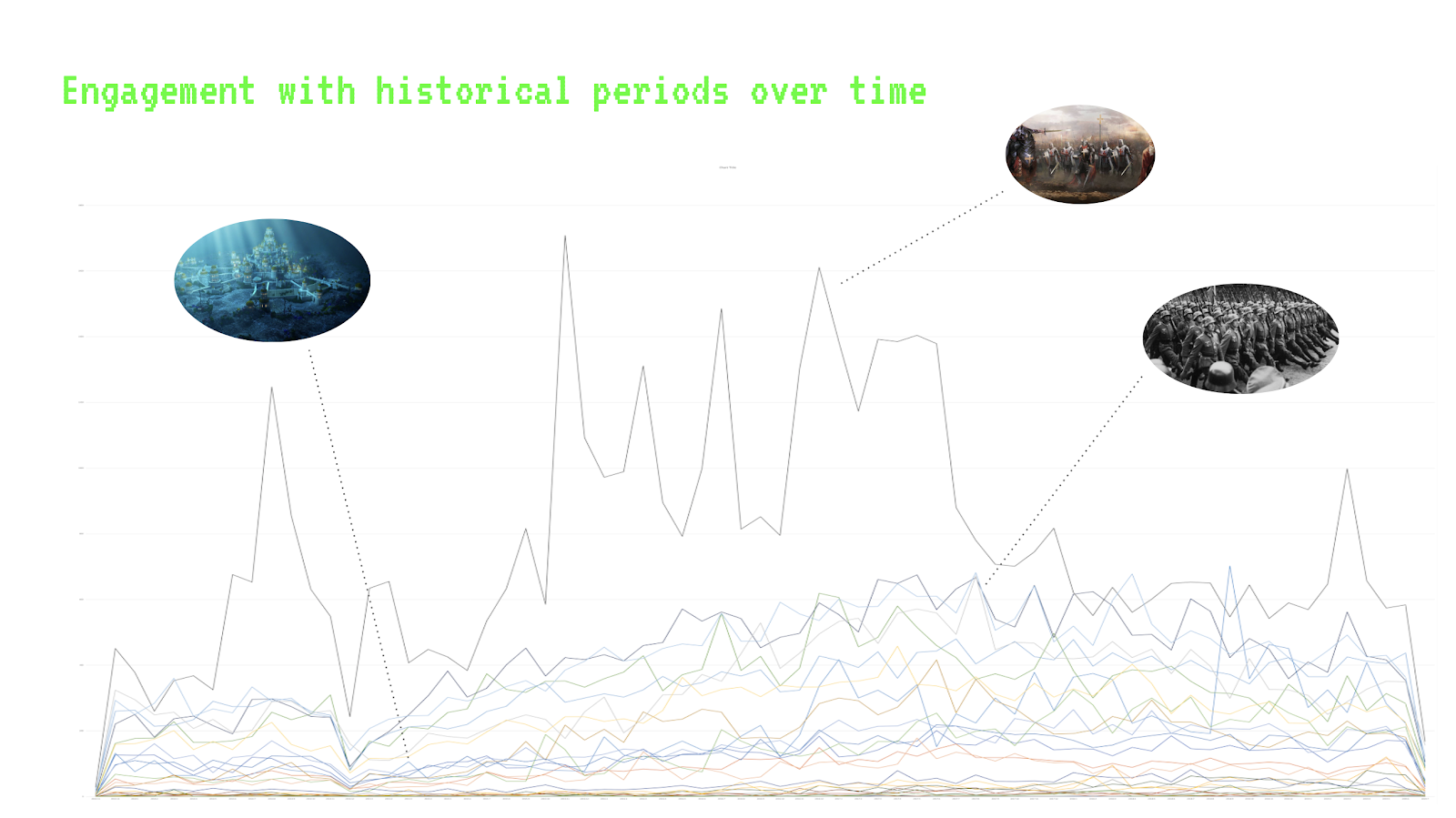
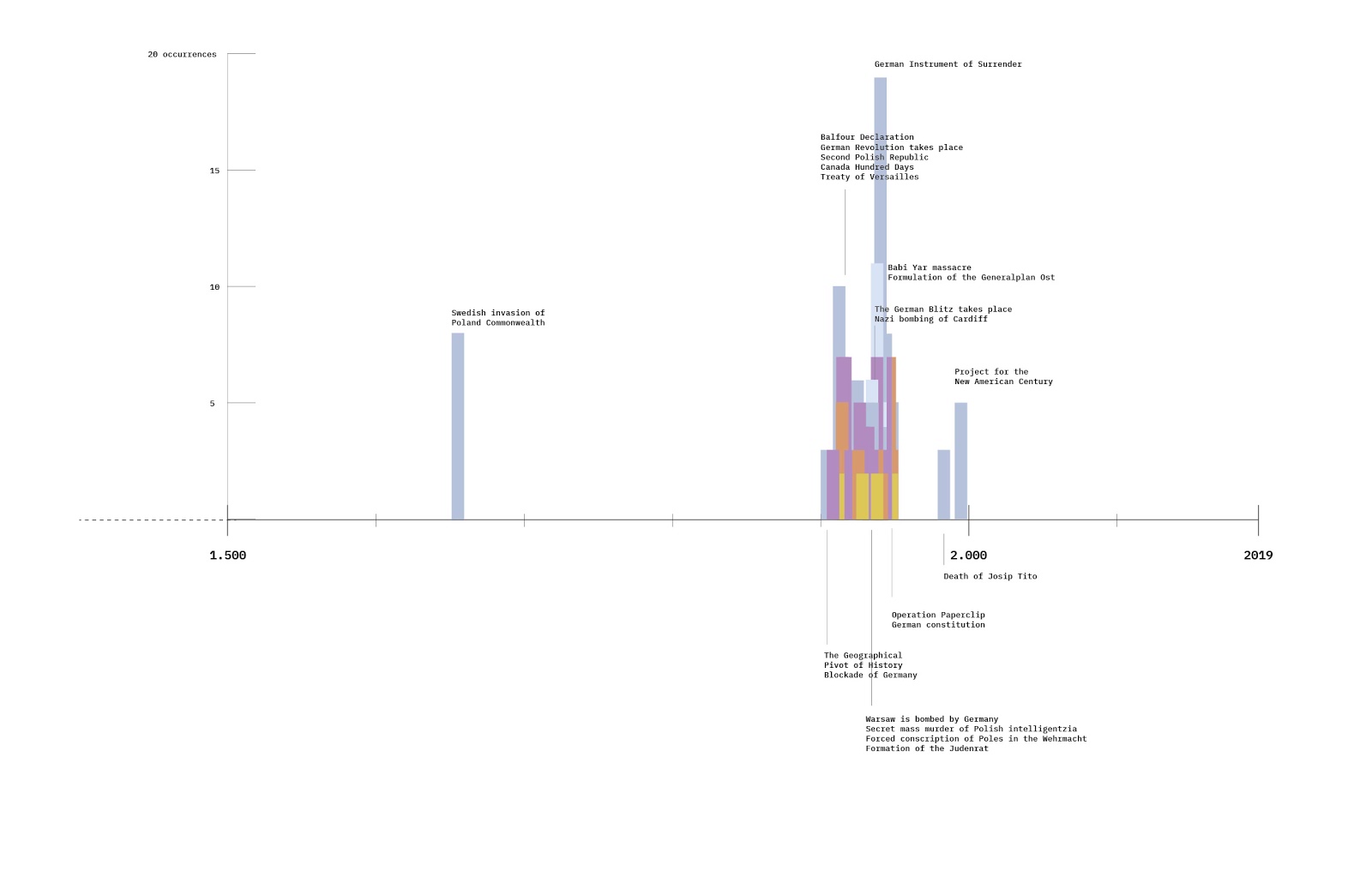
WayBack Machine was used to trace the evolution of the ‘Table of Contents’ of Wikipedia's AI article in half-a-year intervals since its beginning (December 2003-January 2024). The digital history of a single website is an approach which allows one to view a history of a site “through the interface” (Rogers, 2018, p. 44). Wayback Machine is a natively digital tool that allows one to view different versions (or URLs) of a given website which were archived into Wayback Machine’s Internet Archive. Wayback Machine presents the results (the ‘captures’ of a given website) in a chronological order, containing the exact day when the page was captured, allowing for “the history of the website in the style of time-lapse photography” (Rogers, p. 196, 2019). We visualized the changes of ‘Table of Content’ of Wikipedia's article on AI in a GIF format and as a timeline.
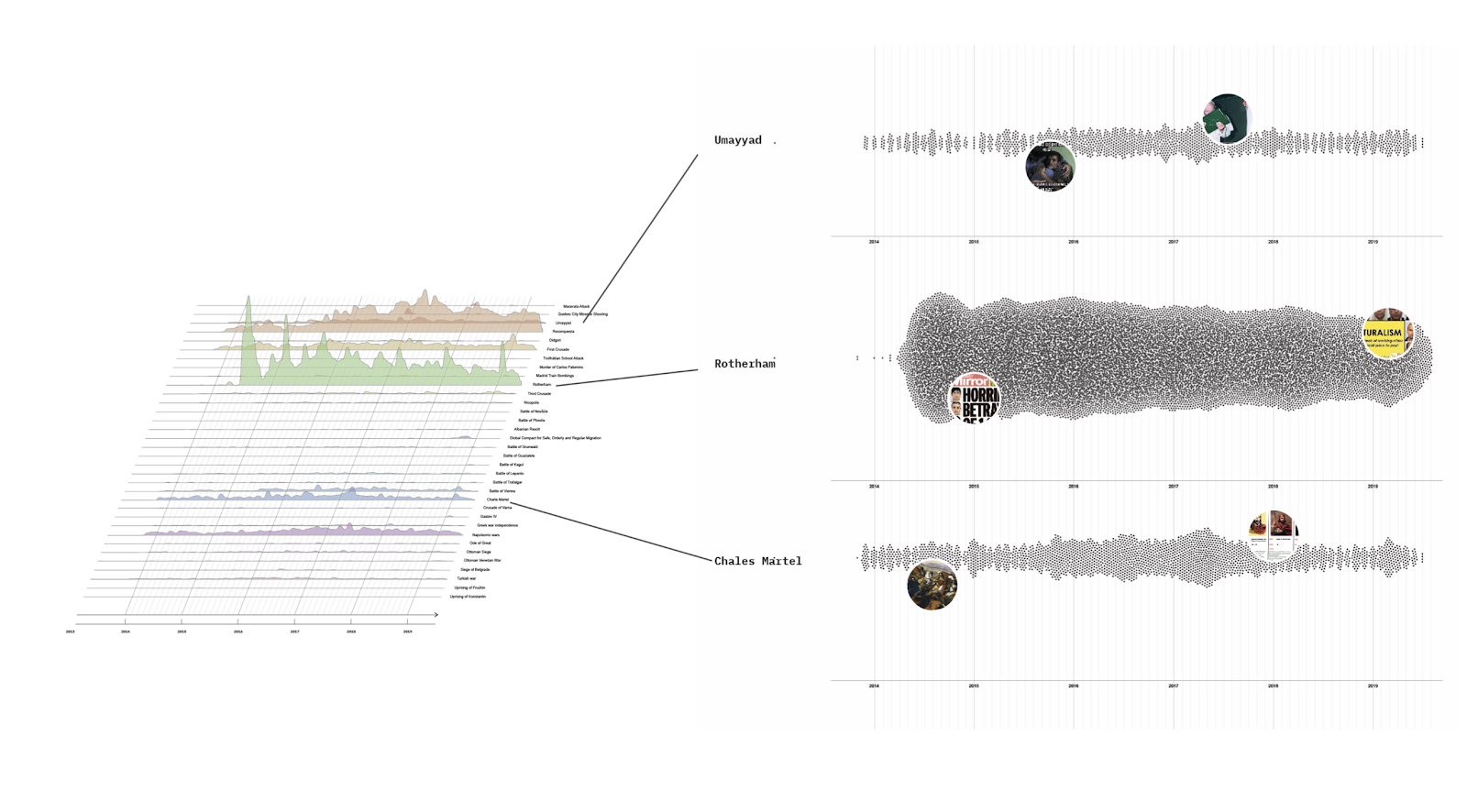
Seealsology was used to retrieve a network of Wikipedia articles connected to the “Artificial intelligence” page. Seealsology is a crawler, that is a digital tool that allows to map out the network of hyperlinks linked to an initial web page or a set of web pages, referred to as ‘seed’ (Venturini & Munk, 2022, p. 164). Seealsology is a tool which focuses specifically on the hyperlinks present in the ‘see also’ section of Wikipedia articles. We then imported the network into Gephi for further analysis. We ran the Modularity statistic (Modularity = 0,832) to detect community clusters within the network of linked sites. A manual identification of the denser zones of the network followed, as we manually labeled main and smaller clusters. We then performed a manual thematic classification of the clusters of pages.
Methods for X/Twitter
The methodological approach to X/Twitter focused on mapping the dominant voices, alignment, and positioning within emerging semantic clusters of collected tweets. The major obstacle of working with X/Twitter data lies in the reduced possibilities of scrapping tweets following the limiting of X/Twitter API access. Therefore, instead of focusing on hashtags and likes, we focused our analysis on retweets. A high number of retweets can be an interesting signal in an analysis of actors and communities on Twitter (Van Es & Schaefer, 2017). Analysis of retweets also follows an approach that accounts for social media metrics other than vanity ones (Rogers, 2018). To analyze retweets as a metric on X/Twitter, we created a network graph where original authors (actors that posted a tweet) exist as a source, while retweeters (actors who retweeted the tweet) are the target. The software used for the visualization was Gephi.Once a retweet network was established in Gephi, a further close-reading followed.
Another methodological limitation we faced at this point was due to the fact that the scraped data did not contain the tweets originally posted, only the retweeted tweets. Therefore, we could not measure the total number of likes of the original tweet, only the already-retweeted ones. We nonetheless wished to further establish an attribute according to which we could, first, localize the dominant actors in each cluster and, second, choose a sample of dominant tweets from each cluster for close-reading. In Gephi, we continued using a total retweet number as an attribute that linked the authors of tweets.
Within the same relational network, we chose the top 4 most engaged with tweets from two most prominent actors in each of dominant clusters for close reading. We have to note that due to limitations of data as well as time constraints, we had to accept some inconsistencies across clusters. In order to protect the privacy of the users’ contained in our data, we anonymized usernames of accounts with less than 5000 followers, while treating users with over 5000 followers as public figures (we were guided here by an older Twitter rule – pre-Musk – which introduced such distinction).
The aim of the close reading was to code what each dominant cluster represents thematically and what AI imaginaries each of the clusters enacts. Next, we employed Generative AI – LLMs and text-to-image models – to further code and abstract our findings. We fed five most-engaged tweets from each cluster as part of a prompt for ChatGPT. In designing prompts, we followed Benedetti (2023) guide on prompt design. In this way, we treated ChatGPT as an agent but also a research tool, prompting it for extracting and coding (Borra 2024). We prompted ChatGPT to produce a thematic summary in the form of a tweet itself, expressing the essence of the selected tweets from each cluster. We run three different prompts for each cluster-query, and then we collectively chose which of the three outputs is the most accurate summary compared to our manual coding. Next, the ‘summary tweets’ generated by ChatGPT were used as prompts in DALLE-2 and Stable Diffusion, with an attempt to represent the content of the tweet visually. Then, each ChatGPT -generated ‘tweet’ was assigned an AI-generated image.Methods for LinkedIn
A mix of qualitative and quantitative methods, as well as close-reading and distant reading, was applied. As co-hashtag network analysis can assist in identifying recurring topics and dominant narratives in discussions about an event on social media (Rogers, 2024), we applied 4CAT and Gephi to perform a co-hashtag network analysis across all posts in the dataset. Following a close-reading of the hashtags and most engaged-with posts in each cluster of the network, we added thematic labels. These clusters roughly display the main sub-topics discussed on LinkedIn related to the Sam Altman ‘drama’.
We analyzed most engaged-with posts as well as a random sample of posts to develop the codebook. We employed a "hybrid approach" to code the posts (Kecojevic et al., 2021; Swain, 2018). To develop and refine themes in an interpretative process (Morse, 2015), we initially engaged in deductive exploration of the data to examine a priori domains of interest evoked by the result of co-hashtag network analysis. To ensure coder reliability, the coders independently coded ten posts from each of the four co-hashtag clusters. We then resolved differences through collaborative discussions and refined our codes until a consensus was reached on the final list of key themes.
In order to better reflect the (lack of) diversity of the actors who were speaking in and to the space of Sam Altman on LinkedIn, we abstracted two image walls which consisted of actors’ avatars who @mentioned Sam Altman (over three hundred avatars in total). We focused on mentions rather than hashtags to better reflect LinkedIn vernacular. The imagewalls were used to visualize the diversity of actors in this space (‘the faces of AI’), showing an abstraction of gender and ethnic diversity of actors involved. Machine learning algorithm and a python script were used to first crop the faces out of actors’ avatar images, and then to assign (or rather, predict) a percentage score for each of the two categories (see discussion for critical examination of these results). To further map out the dominant voices in the space, we put together a list of the actors with most engaged-with posts, containing their professional titles as stated by them in the LinkedIn bio (‘speakers of AI’).
5. Findings
Anaestheticizing AI: Visual and Linguistic Registers of AI Imaginaries

Across the websites we examined, AI imaginary occupies a space of contestation but one where corporate and industry interests dominate. An analysis of keyword occurrences across the websites shows that while technical language and preoccupations are prevalent, so are the social and ethical concerns (such as ‘disinformation,’ ‘privacy,’ or ‘biases’). We found that a sociotechnical imaginary of AI exhibits different concerns regarding, amongst others, matters of efficacy and ethics. Yet this AI imaginary ecompasses concerns that are contrasted by a pool of reassuring terms, such as ‘accountability,’ ‘comprehensive,’ ‘inclusive,’ ‘equity,’ and ‘compliance.’
Keywords which denote the labor or materiality of AI – such as the workers who label, finetune, moderate, and co-produce datasets and training materials – are basically invisible in the cloud of AI issues. The corporate imaginary of concern and efficiency turns a blind eye on the human aspect of AI-making, as well as the larger questions of labor, especially in the Global South. If we consider such obfuscation of labor behind the AI pipeline in combination with the popularity of keywords such as ‘equality’ and ‘equitable,’ or ‘community’ and ‘human rights,’ we note a seeming reflection of the AI industry's imaginary of masking inequalities within its systems.
The visual representation of AI across diverse entities is consistent but rich, incorporating an array of elements. Common elements are easy-to-understand or instructional infographics or illustrations in Memphis style, characterized by the use of geometric shapes and bright colors. Visualizations often emphasize networks and data concepts, featuring interconnecting lines. In depictions of AI, interconnected lines often form larger, symbolic shapes like brains or eyes. Human representation in the context of AI extends to visualizing aspects of humans as data, exemplified by using human faces as fingerprints. The focus on networks is further emphasized by a visual language that lacks hierarchical depictions.
The predominance of blue in the visual imaginary of AI speaks to the desire of corporate and government actors to reduce fear and obscure the potential harms of AI. Highlighting the prevalence of blue in AI stock photos, Alberto Romele argues that blue works as a “calming, peaceful, distant, anesthetising color” (2022, p. 13). Given the importance of futurity for imaginaries, the prevalence of blue instills the sense that AI will bring about positive change, or at least will not lead to conflict. While AI is often depicted with dynamic, bending lines, government entities (which, after all, must safeguard boundaries) are characterized by thick, definitive lines or symmetrical designs associated with neoclassicism. This serves both sides’ interests: corporate AI culture is perceived as innovative within bounds (they are ‘bending’ rules not ‘breaking’ them) while government organizations are presented as preserving a safe status quo for citizens.
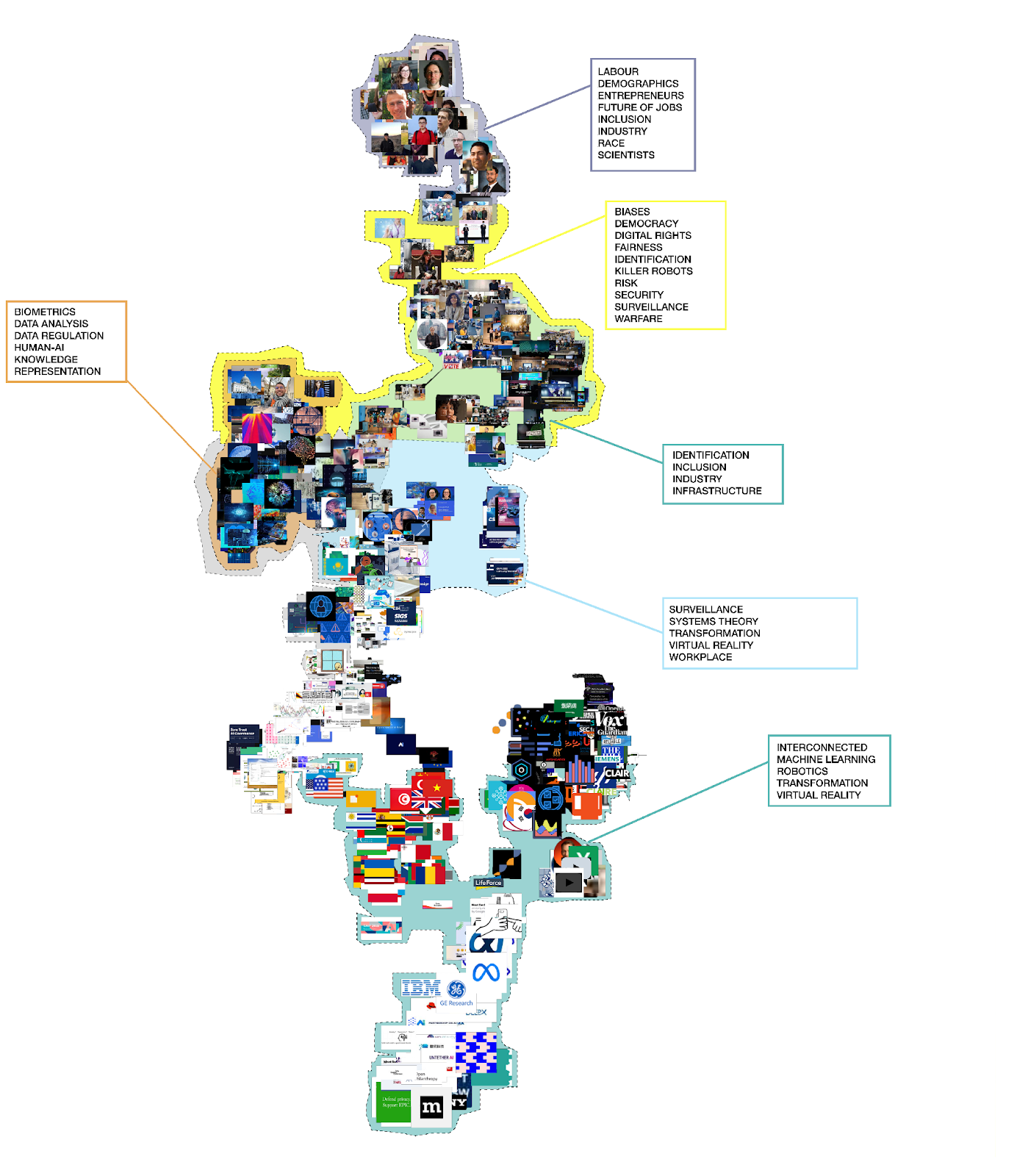
We note that the dataset of websites included a variety of actors, ranging from industry voices to governmental sites and NGOs which were critical of the AI industry. Nonetheless, it appears that across the websites dominant AI imaginaries and their counter-imaginaries deploy similar visual and linguistic registers. Here, again, a certain corporate - or commercial - imaginary overlaps, contributing to the cohesiveness of the portrayed sociotechnical imaginaries. We also would like to point out that the majority of websites returned in the initial Google query represent organizations or governments from Global North. Similarly to discrepancies of AI materialities and labor, many relevant websites are hidden from view in the hierarchy of relevancy dictated by Google sorting algorithm and SEO tactics. The emerging imaginary reinforces the situation where the labor that underpins AI is exported to the Global South and is rendered invisible within its overall imaginary constructed in the Global North.
Going Corporate: Reassembling AI Imaginaries in Wikipedia across Space and Time


The combined analysis of Wikipedia’s article on “Artificial Intelligence” using Contropedia, close-reading, WayBack Machine, and Seealsology, revealed that the corporate imaginary has been slowly overtaking the article. We note that the corporate imaginary of AI was increasingly shaping Wikipedia's AI article following the introduction of ChatGPT in November 2022. However, we note that such corporate turn has been a longer trend in Wikipedia’s article on AI rather than a rapture. This trend – the influence of “corporate-objective” AI imaginary – involves a reduction of various narratives (and, as we assume, enactments of diverse imaginaries of AI) into a discussion of AI primarily as a technology. The corporate-objective AI imaginary incorporates seemingly objective and technical narrations. This imaginary allows a few critiques (or controversial issues) of AI to be mentioned (such as weaponized AI), yet only superficially, with no indication of the pressing issues of exploitation, climate crisis, and privacy invasion.
The corporate-objective AI imaginary is exemplified by the edit history of the Patents section of Wikipedia’s AI article. The Patents section contained multiple paragraphs documenting the history of patenting AI-related technologies, yet today, only a single sentence from this section remains within Wikipedia’s AI article. While the history of the developments in the AI field are still a crucial part of the article, the Patents section that highlighted legal ownership, shareholders, and profit flows, has been deleted over time. Instead, we notice a growing focus on the technicality of how artificial intelligence ‘works’ outside of actual labor and social relations – the “computational” AI imaginary. It is expressed through a factual and scientific vernacular, pointing to the technology’s complexity and relation to computer science.
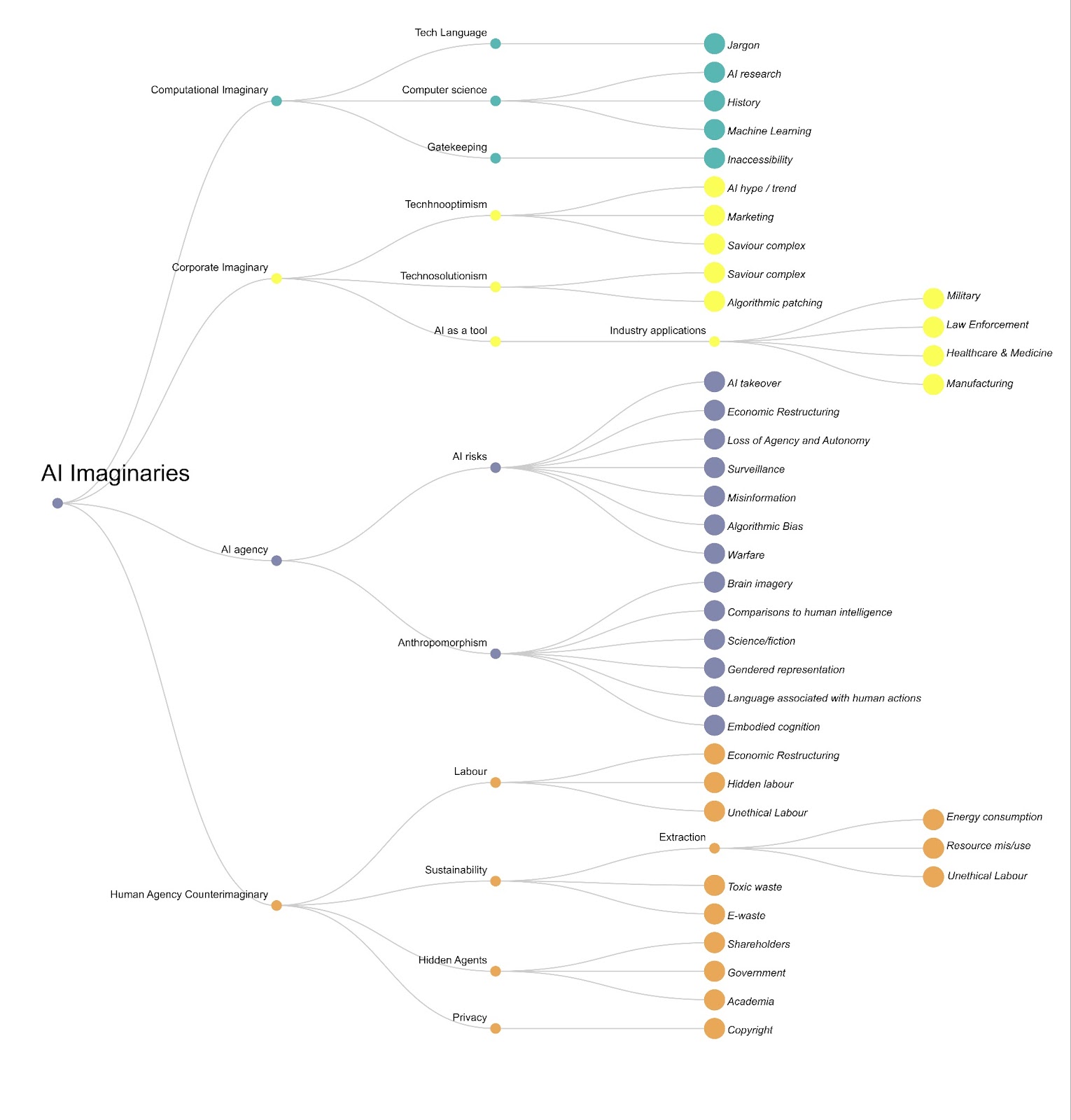
Following the release of ChatGPT, there has been a significant surge in corporate-objective AI imaginary as well as furthering of computational AI imaginary. While the expression of ‘neutrality’ around AI on Wikipedia is partially a reflection of a site-wide desire for neutrality and objectivity of universal knowledge, such neutrality might also expose an issue of AI industrialisation. As AI is embedded deeper and deeper into the ordinary, it becomes normalized, creating an imaginary of ‘normalcy.’ Such an imaginary of the ordinary can become problematic when the deeper and broader impacts of AI technologies become buried under the rubble of daily noise.
The imaginary of ‘normalcy’ that connotes seeming neutrality of AI contrasts sharply with the imaginary of techno-optimism and techno-solutionism. In Wikipedia’s article, we found several cases where AI’s problem-solving ‘capabilities,’ particularly in medicine and research, were presented with the spirit of techno-solutionism and optimism. Techno-solutionist perspectives call for further technological advancements to solve existing social, environmental, political, and technological problems, disregarding the complex embeddedness of AI technologies in existing (often oppressive) structures. Techno-optimism sees AI advancement as a synonym of human advancement. In Wikipedia’s AI article, there has been an increase in the imaginary of techno-optimism and techno-solutionism, and it is especially prominent in the included perspectives of authorities such as ‘AI experts’ and ‘AI developers.’
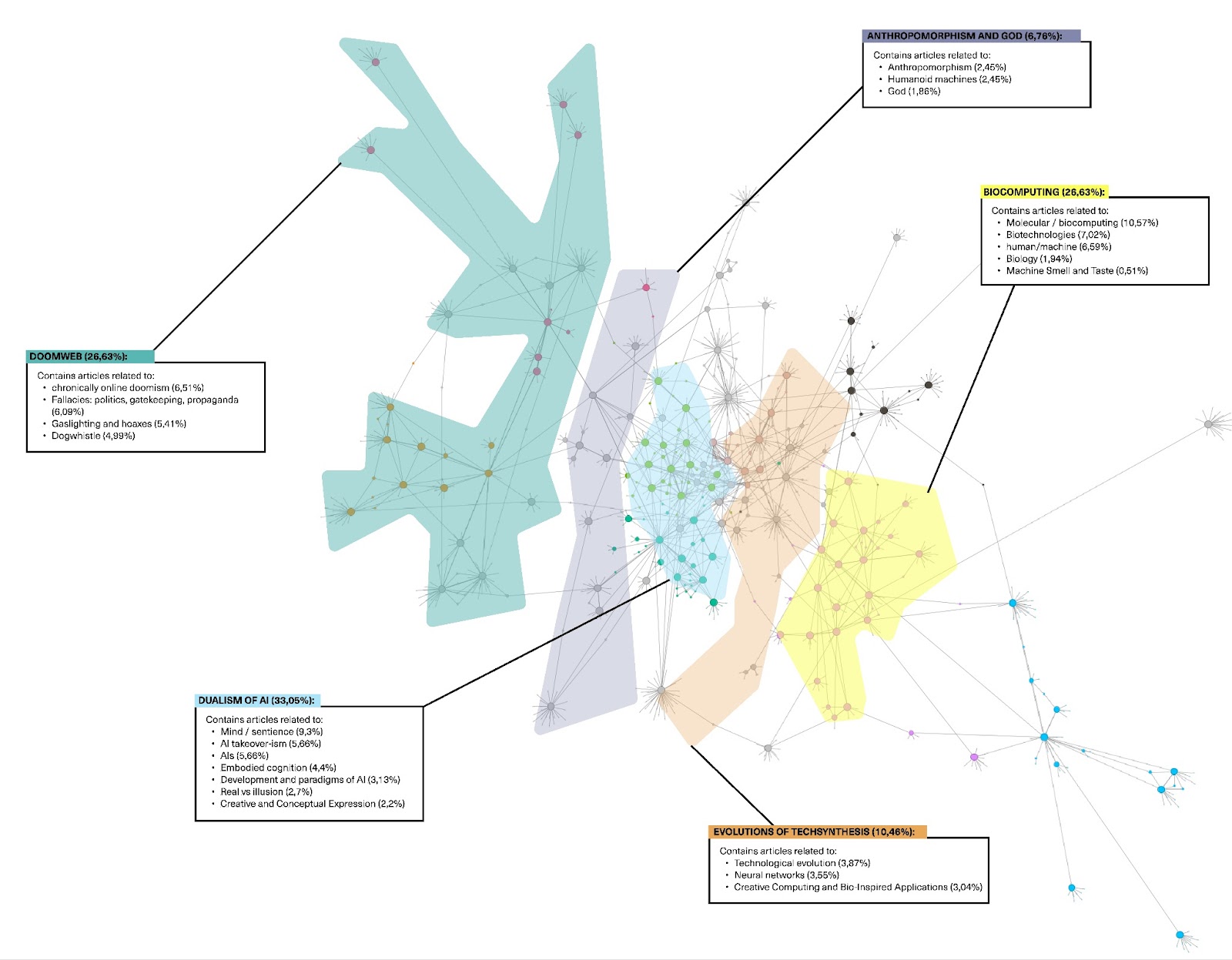
Quite unlike the corporate and techno-optimistic imaginaries, the imaginary of doom (or doomism) reveals hopelessness and anxiety regarding humanity’s future. Doomism prevailed in Wikipedia’s AI article in its past versions, but gradually, and especially after the release of ChatGPT, such an imaginary has been edited out and limited to categories such as ‘AI taking jobs.’ Nonetheless, the imaginary of doom remains present in the space of linked articles from ‘see also’ section of Wikipedia’s AI article. Another imaginary related to that of AI doomism is that of AI Agency, where AI is anthropomorphized. Some controversies around AI such as biases, authority in decision making, and social implications are being mentioned here, yet AI technologies are given more agency than humans who appear as mere objects of technological consequences. Therefore, we note the visible blank space of human agency imaginary, which reveals the issues that are absent from the imaginaries on Wikipedia: AI pipeline including labor practices, sustainability and environmental impacts, and privacy.
Retweeting AI: Imaginaries through Retweet Networks, LLMs, and Text-to-Image Models
Sam Altman, a key figure in the AI industry and one of the founders of a leading AI company OpenAI, was dismissed by the OpenAI board on November 17, 2023. Swiftly after his dismissal, he was hired by Microsoft (one of OpenAI ’s major donors) on November 19. Subsequently, on November 21, he was rehired by OpenAI. This incident sparked extensive discussions across social media platforms and mainstream media outlets, including numerous speculations by the public regarding the reasons behind OpenAI 's actions, concerns about the ethics of AI technologies, and expressions of support and criticism of Sam Altman.
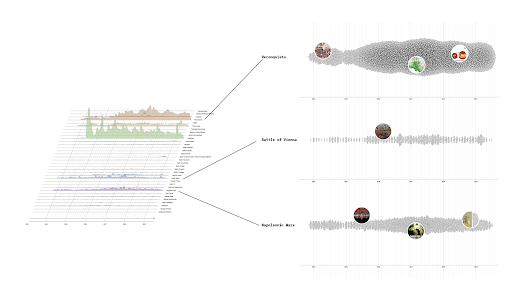
Using the firing of the Sam Altman controversy as an entry point, we visualized the clusters of alignment among users, paying special attention to the most vocal and dominant voices in the space. Using retweets as the attribute to guide us through the mapping of the dominant actors and their alignment in X/Twitter, we created a network visualization in Gephi. Given the existing limitations in the API caused by the migration to X, it was necessary to rethink a survey methodology that would account for the most influential and authoritative voices related to this platform and its new transformation Out of eight clusters of alignment, we focused on the most prominent ones, limiting our close-reading to the total of seven main clusters. The close-reading revealed significant differences in imaginaries that are enacted in that space, mostly across the clusters that do not align closely, but also inside some of the clusters. We note that the largest, closely-aligned retweet cluster is closely connected to four other clusters. Two other prominent clusters are not connected among each other.
The closely aligned clusters at the center are characterized by a dominant, homogenic imaginary that sees AI as flows of power, capital, and politics. This imaginary, largely critical of the current developments in both making and handling of AI, is in favor of stronger regulation. In aligned, but slightly further away from the center, clusters, a mix of corporate and techno-optimistic imaginaries resonates with the imaginary of Sam Altman as a leader. These imaginaries clash in above mentioned clusters with an imaginary of power, capital, and politics. Another binary within those clusters is that of a time-emphasis – the imaginary of Sam Altman as a leader focuses on Altman’s implications on AI development in the future, whereas the power, capital, and politics (counter-)imaginary focuses on AI’s implications today.
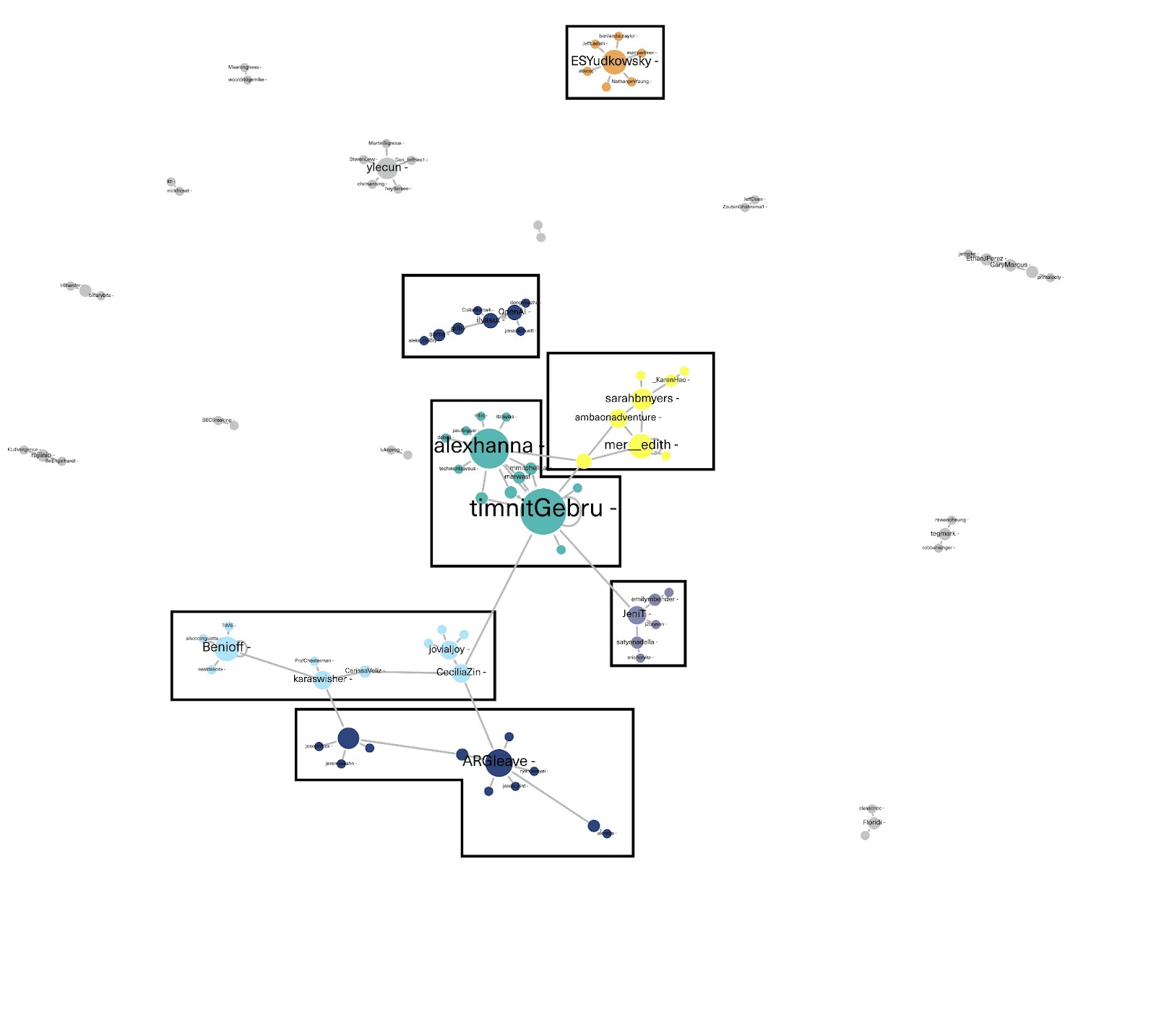
Clusters which are furthest away from the center are in stark contrast to the imaginary of AI as flows of power, capital, and politics. Instead, computational and techno-optimistic imaginaries prevail. While the imaginaries here seem to be aligned, they do not appear so in the networked graph. Indeed, while one cluster seems to enact techno-optimistic imaginary, where Altman-as-leader is either praised or used as an excuse to debate future implications of AI, the other cluster enacts the imaginary of AI doomism, where AI risk is exemplified as an existential threat to humanity. In the AI doomism cluster, Altman’s leadership is questioned and even criticized.
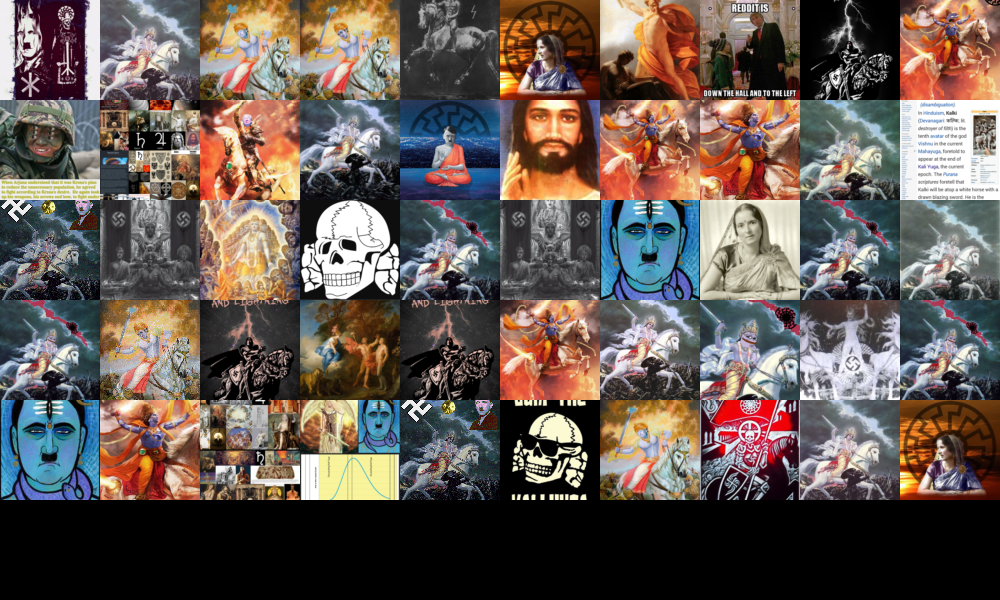
Following the manual coding of the clusters based on close-reading of tweets, we extracted most-engaged tweets into a short corpora that was used as a basis for ChatGPT prompts. We then combined the body of the most-engaged with tweets from each cluster and we included them in three prompts that we run through ChatGPT (see below for the exact prompt texts). Once ChatGPT produced the outcomes, we yet again performed a close-reading, this time of the ‘generated tweets,’ and picked one that suited best to our understanding of each cluster theme. Next, we used these ‘generated tweets’ as prompts in text-to-image generative AI models to produce images that we then ascribed to clusters in the same way.| ChatGPT Prompt 1 | ChatGPT Prompt 2 | ChatGPT Prompt 3 |
| You are an analyst trying to map the narrative and imagery of OpenAI and Sam Altman on Twitter. I will provide you with several tweets that talk about OpenAI and Sam Altman. I need you to make a summary in the form of tweets, capturing the keywords and hashtags most used by users. Do not quote the words 'tweet' or 'twitter' in your reply. Do not include URLs or @ or even RT. Please send only one tweet. | You are an analyst trying to map the narrative and imagery of OpenAI and Sam Altman on Twitter. I will provide you with several tweets that talk about OpenAI and Sam Altman. I need you to make a summary in the form of a tweet, which includes the substance of the discourse of all the tweets and uses the hashtags most used by users. Do not quote the words 'tweet' or 'twitter' in your reply. Do not include URLs or @ or even RT. Please send only one tweet. | You are an analyst trying to map the narrative and imagery of OpenAI and Sam Altman on Twitter. I will provide you with several tweets that talk about OpenAI and Sam Altman. I need you to write a tweet about the topic that summarizes the tweets I have provided you with, containing the keywords and hashtags most used by users. Do not mention the words 'tweet' or 'twitter' in your reply. Do not include URLs or @ or even RT. Please only write one tweet. |
The reasoning behind turning to generative AI as a part of our methodological approach was twofold. First, we wanted to make use of generative AI models to expand our coding and abstracting process, as well as to further our exploration into a visual field. By doing so, we wanted to replicate X/Twitter vernacular in summarizing imaginaries enacted by X/Twitter clusters into a format of a tweet, a short text with an embedded image. Second, we wanted to conceptually engage with the entanglement of data and AI models and their relation to AI imaginaries. Given that a significant portion of data used to train generative AI such as ChatGPT and DALL-E2 was scraped from the internet – making them “a blurry jpeg of a web,” as one metaphor had it (Chiang 2023) – the outputs of these models are to a degree an entrypoint into AI imaginaries. Thus, the results included here can also be reread – on the basis of Ferruccio Rossi-Landi's sociosemiotic position (Rossi-Landi1985,1995) – as a kind of semiotic reflection on the very phenomenon of AI fuelled by AI itself.
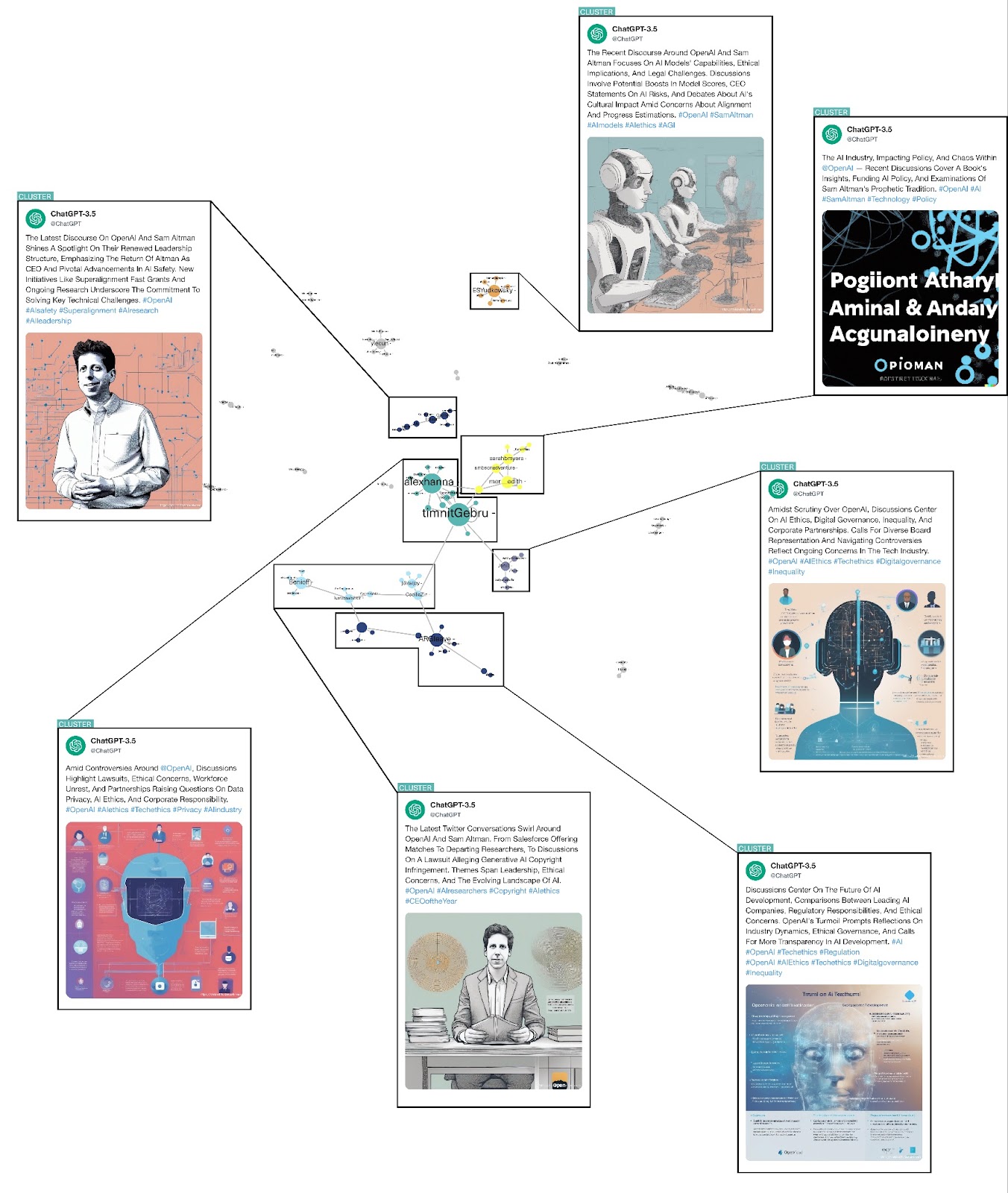
Many-to-One: Sam Altman as an Aspirational LinkedIn Space

Among all social media platforms, LinkedIn, being a platform with a strong focus on the professional workplace and specialized content (Van Dijck, 2013), offered yet another entry point into the clash of AI imaginaries following the controversy around Sam Altman’s firing and rehiring from OpenAI in November 2023. The data sample of LinkedIn posts materializes a close-minded community from tech and marketing industries. These actors view Altman as a desired figure of leadership. Altman is thus an expression of an imaginary of a down-to-earth genius whose leadership is met with praise in the community. Some of the stories that make-up this imaginary include the themes of Altman’s leadership style, the impacts of Microsoft's rehiring of Altman, Altman's impact on the future of the AI education industry, and the potential influence of Altman's actions on the future of cryptocurrency.
Within a leadership imaginary, Altman is imagined as an icon in the AI industry and a spokesperson for the fintech industry. The close-reading of most engaged-with posts revealed some reluctance to praise Altman and instead express concerns about OpenAI 's decision to rehire Altman, raising questions whether OpenAI prioritizes commercial interests over AI safety and ethics. This also reflects a LinkedIn vernacular, a business and employment-focused platform, where the Altman controversy is used to perform both the imaginary of business success and an imaginary of corporate Big Tech interests.
In order to better reflect the (lack of) diversity of the actors who were speaking in and to the space of Sam Altman on LinkedIn, we abstracted two imagewalls which consisted of actors’ avatars who @mentioned Sam Altman. These imagewalls were then used to visualize the diversity of actors in this space (‘the faces of AI’). To further map out the dominant voices in the space, we put together a list of the actors with most engaged-with posts, containing their name and professional titles stated by them in the LinkedIn bio (speakers of ai’). Just like in the X/Twitter case, we turned to AI models to both abstract (and extract) data, while also to use these technologies as a further study and critique of the dominant AI imaginary and its entanglement with the dominant actors who sustain it.
We recognize the intrinsic biases and margins of error embedded in machine learning algorithms, especially ones that are deployed to ‘predict’ gender and ethnicity. These technologies are often marketed as ‘AI,’ we also recognize that the dominant actors in the LinkedIn data are proponents of these technologies and their deployments through the imaginary of AI techno-optimism and corporate neutrality. Therefore, we decided to use these tools to at once abstract and visualize the lack of diversity within the dominant AI imaginary space around Sam Altman on LinkedIn by of bises, but also by repurposing the tools that this dominant AI imaginary praises by using it on the privileged minority who either is or aspires to be part of AI imaginary that Sam Altman materializes.
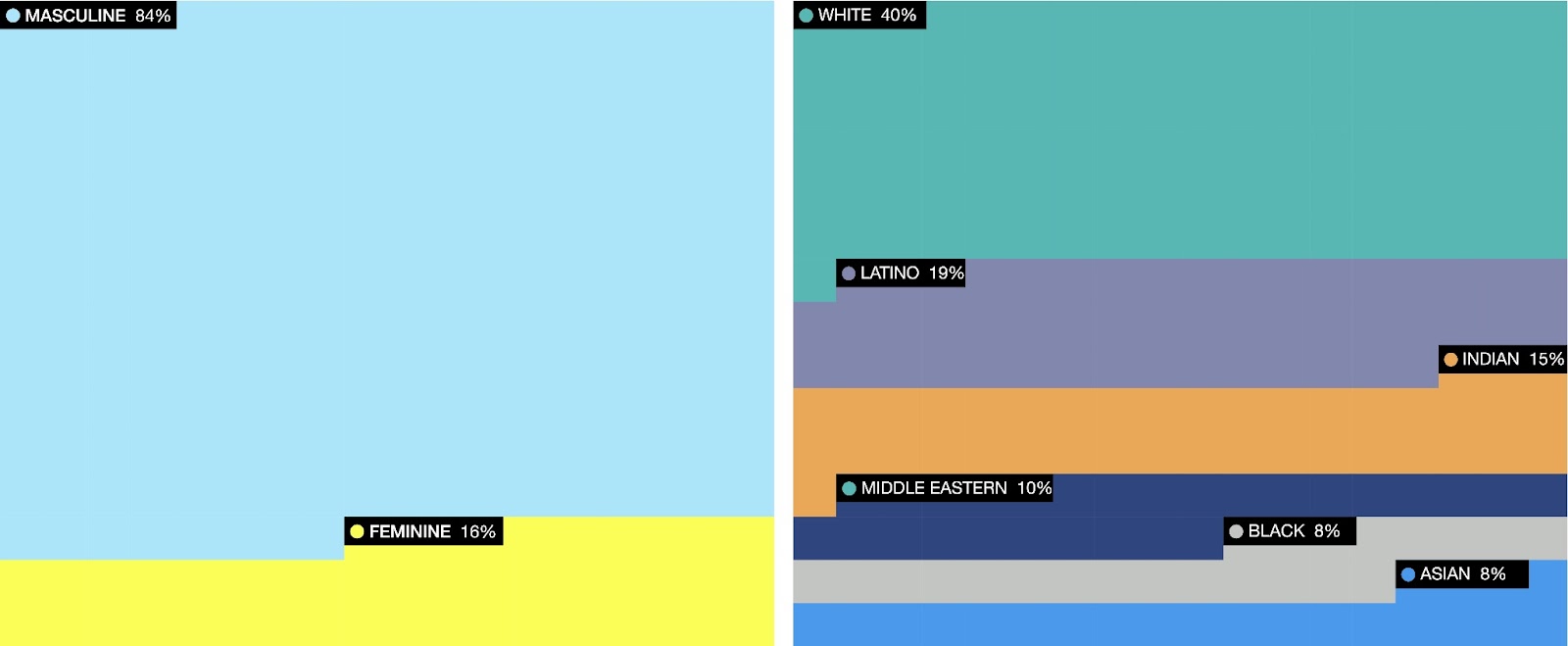
We also note that, on LinkedIn, imaginaries and counter-imaginaries both clash and coexist in discussions of AI, communicating their ideal vision of the AI future through powerful actors. An imaginary of collective optimism for AI development is found both in the quantitatively analyzed samples and close readings of posts. There also appears to be a counter-imaginary to the AI imaginary of techno-optimism, which includes an apparent concern with a potential danger of artificial intelligence and human security, following the firing and rehiring of Altman. However, this imaginary is not enacted by a different group of actors. Rather, the notion of AI risk and AGI is an element of a larger AI imaginary that goes hand-in-hand with industry’s narratives, only seemingly appearing as a counter-imaginary.
6. Discussion
Our findings also suggest that both dominant AI imaginaries and its counter-imaginaries, particularly across websites, deploy similar visual and linguistic registers. Additionally, the images generated by AI text-to-image models were closely aligned to the dominant visual registers present in AI imaginaries as explored through website case study. As corporate and industry-driven actors emerge from the results as the most influential actors - with some presence of governmental actors - currently constructing imaginaries about AI, it is relevant to ask where the social actors are and how society has been invited and instigated to reflect and participate in processes about AI. Although governments and NGOs may represent social interests, the set of terms indicates a distancing of society from regulatory and decision-making processes about the future of AI, even though it is civil society data that has been used for algorithm training and machine learning, enabling the technical leaps of AI. This speaks to the concentration of certain actors and sources given more visibility in knowledge gatekeeping systems embedded in search engines like Google, but also within the relevancy and recommendation algorithms structuring popularity and engagement metrics on platforms such as LinkedIn or X/Twitter.
The comparison of the Wikipedia article, both in terms of overall changes and the versions before the release of ChatGPT and the current version is yet another example of a growing influence of the corporate and techno-optimistic imaginaries. It is a shift from extensive documentation of covering multiple perspectives and imaginaries (in relation to what was available at the moment) to an article written with a seemingly single point of view, only peripherally mentioning critiques that enact counter-imaginaries of AI. The coupling of corporate imaginary and computational imaginary with language of neutrality can obfuscate critical issues and controversies around AI. However, when taking into account the nature of the platform itself, Wikipedia’s objective is to be neutral, so perhaps AI neutrality is, to a degree, a byproduct of the platform’s incentives.
The positive portrayal of Sam Altman also reflects the techno-solutionist and corporate imaginary, with a strong presence of techno-optimistic imaginary where AI technology and its future development are endorsed by dominant actors from the tech and marketing industries, as it shows within the LinkedIn community and across some clusters in X/Twitter. According to Mager and Katzenbach (2021), this idealized imagination of the future of technology is performative, often driven and propagated by business actors' suppositions about technology, and is used by practitioners to promote their products and services. The tech and digital marketing industry professionals on LinkedIn contribute to the ongoing techno-hype in the AI industry through their highly praising comments on Sam Altman's leadership and influence, aligning with their commercial benefits.
Across platforms and across AI imaginaries, we note a considerable lack of engagement with issues such as environmental impacts of AI industry and labor entanglements. Instead, we note several AI imaginaries which tend to occur together (corporate/neutrality imaginary, techno-solutionism and techno-optimism imaginary, computational imaginary, Sam Altman’s leadership imaginary), yet enact distinctive issues, narratives, and vocabularies depending on platform vernaculars and platform-specific communities. We note a presence of counter-imaginaries on X/Twitter as well as across our websites sample, which tend to address issues that resurface in dominant imaginaries as well as expand the list of AI issues and critiques.
The difficulty inherent in this research was limited access to data. This, however, forced us to work looking for a new way of expressing interactions on the platforms. Therein, we believe, lies the importance of this work: attempt to understand the new ways in which “assemblages of materiality, meaning, and morality that constitute robust forms of social life.” as Jasanoff and Kim phrase it, (2013; 2015), assemble and enact sociotechnical imaginaries, and thus, how can we, as researchers, critically trace and reassemble these assemblages of materiality and meaning. Future research should further engage with obstacles and opportunities that digital methods provide for studying sociotechnical imaginaries. We are certain there are spaces for further development of the methods and concepts we employed across the case studies in this project, as well as the application of our approaches to different platforms.
7. Conclusion
The rise of AI brings hopes and fears about the future that this technological ‘revolution’ may bring. From Big Tech launching one innovation after another, to the public eagerly or unwittingly using new technologies, to AI critics and media reporting on risks, to governments realizing the need to develop new regulatory policies, imaginaries of AI are performed and reshaped.
Our study further shows the repeating dominance of Global North, and particularly the AI industry, in attempting to dominate the discourse by presenting themselves as the ones who act out AI imaginaries that they propagate. Imagining themselves as agents of history and progress, the actors behind dominant AI imaginaries render organizations and voices from the Global South as nonexistent, or at least as passive, which could not be further from truth. Lisa Parks argues that imaginaries allow users to “think about what infrastructures are, where they are located, who controls them, and what they do” (Parks, 2015, p. 355). In this sense, we can see that the infrastructures that support AI are primarily located within corporate interests in the Global North. The way the internet and information is organized reminds us of the difficulties or impossibilities of forming counter-imaginaries that offer a real alternative to the corporate and techno-solutionist vision of AI .
It is impossible to overestimate the influence of the AI industry on human and non-human lives, and therefore it is vital for us– scholars and the public at large– to be aware of how the AI industry operates technologically, strategically, and ideologically. This project is less interested in the public perception of AI per se than in extrapolating and mapping out imaginaries and counter-imaginaries of the AI industry. Imaginaries are not only a set of references, like lenses that help us see, but also powerful actants that affect everything from individual mundane choices to economic and policy decisions. The study on AI imaginaries holds significant relevance, providing an in-depth understanding of artificial intelligence beyond technical and economic realms to encompass broader societal impacts. Imaginaries open up pathways to redefine existing narratives and create new mental and semiotic infrastructures which can constitute a first step to deterritorialized assemblages of oppression.
8. References
Benedetti, A. (2023). Conversing with our machines. Experimental tips on prompting for research with Large Language Model. DMI Summer School 2023.
Bode, K. and Goodlad, L. M. E. (2023). “Data Worlds: An Introduction.” In Critical AI (2023) 1(1-2) https://doi.org/10.1215/2834703X-10734026.
Borra, E. (Jan 8, 2024). “The Medium is the Method. Using Large Language Models (LLMs) in digital research.” [keynote lecture]. DMI Winter School 2024. Amsterdam.
Borra, E. et al. (2021). A Platform for Visually Exploring the Development of Wikipedia Articles. Proceedings of the International AAAI Conference on Web and Social Media. 9. 711-712. 10.1609/icwsm.v9i1.14581.
Borra, Erik et al. (2015). “Societal Controversies in Wikipedia Articles.” In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems - CHI ’15, pp. 193–96.
Borra, E., et al (2014). “Contropedia - the analysis and visualization of controversies in Wikipedia articles.” In Proceedings of The International Symposium on Open Collaboration (OpenSy m '14). Association for Computing Machinery, New York, NY, USA, 1. https://doi.org/10.1145/2641580.2641622.
Chiang, T. (Feb 9, 2023). “Chatgpt Is A Blurry JPEG Of The Web.” The New Yorker. https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web.
Colombo G (2018) The design of composite images: Displaying digital visual content for social research. PhD thesis, Politecnico di Milano.
DHLab. (n.d.) PixPlot Overview. https://dhlab.yale.edu/projects/pixplot/.
Jasanoff, S. (2015) "Future Imperfect: Science, Technology, and the Imaginations of Modernity." In Dreamscapes of Modernity: Sociotechnical Imaginaries and the Fabrication of Power. Edited by Sheila Jasanoff, and Sang-Hyun Kim (eds). University of Chicago Press, 2015. https://doi.org/10.7208/chicago/9780226276663.003.0001.
Jasanoff, S. and Kim, S. (2013). “Sociotechnical Imaginaries and National Energy Policies.” Science as Culture. 22, pp. 189-196. 10.1080/09505431.2013.786990.
Kak, A. and West, S. M. (April 11, 2023). “AI Now 2023 Landscape: Confronting Tech Power”, AI Now Institute, https://ainowinstitute.org/2023-landscape.
Kazansky, B., & Milan, S. (2021). “Bodies not templates”: Contesting dominant algorithmic imaginaries. New Media & Society, 23(2), 363–381. https://doi.org/10.1177/1461444820929316.
Kecojevic, A., Meleo-Erwin, Z. C., Basch, C. H., & Hammouda, M. (2020). „A Thematic Analysis of Pre-Exposure Prophylaxis (PREP) YouTube videos.” Journal of Homosexuality, 68(11), 1877–1898. https://doi.org/10.1080/00918369.2020.1712142.
Mager, A., & Katzenbach, C. (2021). „Future imaginaries in the making and governing of digital technology: Multiple, contested, commodified.” New Media & Society, 23(2), 223–236. https://doi.org/10.1177/1461444820929321.
Morse, J. M. (2015). “Analytic strategies and sample size.” Qualitative Health Research, 25(10), 1317–1318. https://doi.org/10.1177/1049732315602867.
Niederer, S. & Colombo, G. (2019). “Visual Methodologies for Networked Images: Designing Visualizations for Collaborative Research, Cross-platform Analysis, and Public Participation. Diseña, (14), pp. 40-67. Doi: 10.7764/disena.14.40-67.
Parks, L. (2015). “‘Stuff you can kick’: toward a theory of media infrastructure.” In: Svensson, P., Goldberg. D. T. (eds) Between Humanities and the Digital. MIT Press, pp. 355–373.
Peeters, S., and Hagen, S. (2022). “The 4CAT Capture and Analysis Toolkit: A Modular Tool for Transparent and Traceable Social Media Research.” Computational Communication Research 4(2): 571–89.
Rogers, R. (2018). “Otherwise Engaged: Social Media from Vanity Metrics to Critical Analytics.” International Journal of Communication 12, pp. 450–472.
Rogers, R. (2024). Doing digital methods. SAGE Publications.
Rogers, R. (2019). Doing Digital Methods. SAGE Publications.
Rogers, R., Sánchez-Querubín, N., and Kil, A. (2015). Issue Mapping for an Ageing Europe. Amsterdam University Press.
Rogers, R. (2018). “Periodizing Web Archiving: Biographical, Event-Based, National and Autobiographical Traditions,” in Niels Brügger and Ian Milligan (eds.), SAGE Handbook of Web History, London: Sage, pp. 42-56.
Romele, A. (2022). “Images of Artificial Intelligence: a Blind Spot in AI Ethics.” Philos. Technol. 35, 4. https://doi.org/10.1007/s13347-022-00498-3
Rossi-Landi F. (1985). Metodica filosofica e scienza dei segni. I nuovi saggi sul linguaggio e l’ideologia. Bompiani
Rossi-Landi F. (1995). “Work, time, and some uses of language”. In Jeff Bernard (Ed.), Zeichen/Manipulation.
Schäfer, M. T., & van Es, K. (2017). The Datafied Society: Studying Culture through Data. Amsterdam University Press.
Swain, J., (2018). “A hybrid approach to thematic analysis in qualitative research: Using a practical example.” In Sage Research Methods Cases Part 2. SAGE Publications. https://doi.org/10.4135/9781526435477.
Van Dijck, J. (2013). ”‘You have one identity’: performing the self on Facebook and LinkedIn.” Media, Culture & Society, 35(2), 199–215. https://doi.org/10.1177/0163443712468605.
Venturini, T. and Munk, A. K. (2022). Controversy Mapping: A Field Guide. Polity Press.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback