You are here: Foswiki>Dmi Web>WinterSchool2020trackinggenderbiasamazon (14 Feb 2020, MarkDavis)Edit Attach
Tracking Gender Bias in Amazon Search Results
Ingrained biases & algorithmic complexities
Team Members
Hailey Beaman, Tommaso Campagna, Aikaterini Mniestri, Giovanni Rossetti, Xiao Wang, Romain DurandContents
Team MembersContents
Summary of Key Findings
1. Introduction
2. Initial Data Sets
3. Research Questions
4. Methodology
Methodology - Part I
Methodology - Part II
5. Findings
Findings - Part I
Findings - Part II
6. Discussion: Two different algorithms
7. Conclusion
8. References
Bibliography
Websites
Summary of Key Findings
In this project, we wanted to question the reproduction of genderedness in shopping spaces by Amazon. We found that while personalization (through the creation of a gendered browsing history) did not seem to significantly affect search results in terms of a gender bias, we did observe that certain queries produced consistently gendered results. For instance, queries like [shirt] and [underwear], regardless of the effects of personalization, returned more products marked as “for men” by Amazon than “for women.” Furthermore, we observed that gendered personalization seems to have a more pronounced effect on the “Recommended products” section of Amazon, in which suggests that Amazon might have several different algorithms that operate by different logics or that analyze user behavior in different ways.1. Introduction
Today, conversations about datafication and algorithmic advancement are no longer isolated to scientific discourses. As a result of digitalization of many everyday processes, algorithms are a part of our daily life and routine (Weinberger, 2019). The significance of data and algorithms is particularly visible in the climbing profit figures of the retail industry. Internet portals enable companies in either the conventional or the e-commerce sector to get access to large-scale datasets and to statistically model their users through a cogent tool: an automated, entangled, and algorithmic system (Cheney-Lippold, 2017) , examples of which include: ZARA’s “fast” fashion data analysis[1], the famous Wal-Mart’s beers and baby diapers bundle[2] and the Amazon’s personalized recommendation system[3]. Amazon, the online retailing giant, is embedded within such a sophisticated algorithm ecosystem. The consumers’ online footprints regularly left on their web pages become the traces for mapping individuals’ habits and targeting niche consumer sub-groups. This project takes these methods of targeted marketing and personalization as a starting point to investigate the extent to which Amazon infers certain markers of identity based on user behavior. Therefore, the research curiosity intrigues this project to dig into one particular indicator “gender-coding” via two precedence-ordered approaches. With the assistance of TREX tool, the project attempts to investigate the extent to which the “game tree” (Chai, et al., 2019) of Amazon’s algorithm(s) could detect or assign users’ genders based on personalized browsing data intake. Furthermore, it argues that the complexity of Amazon’s network algorithm might makes relationships of causality within search results difficult to ascertain.2. Initial Data Sets
The datasets employed in this research are obtained through two different methodologies. The first refers to the Amazon passive scraping using the Amazon Tracking Exposed tool and includes worksheets and images. Overall, we collected three worksheets, one for each research phase, and four different visualizations of images, linked to the initial and final phases of clean and “polluted” profiles. The second methodology is operationalized by manual coding the "recommended product" algorithm and is collected in a separate worksheet. The visualizations are two, respectively dedicated to the female and male categorization of the specific Amazon algorithm.3. Research Questions
To what extent are Amazon search results gender coded?- How does personalization and in-store browsing history affect the products shown in the recommendation section of the Amazon interface?
4. Methodology
Our methodology comprised of two different rounds of what we could consider A/B testing. The research was divided into two parts. The first part is dedicated to the investigation of gender-coded search results on Amazon, while the second part was undertaken as a follow-up. All testing phases were conducted using the Amazon Tracking Exposed browser extension.Methodology - Part I
Phase 1(see fig 1): The first phase of our research was dedicated to creating a kind of baseline of the search results for a specific query returned for both signed-in accounts, and anonymous users. To start, we created one Amazon account associated with a male name, and one associated with a female name. For this testing phase, we had one researcher querying Amazon as the male account-holding user, another as the female account-holding user, and one as a completely anonymous user. Each researcher downloaded both a clean Firefox and Brave browser to act as a research browser. The two signed-in accounts used Firefox with the Amazon Tracking Exposed extension installed, and the anonymous user used Brave with the extension installed. After navigating to amazon.com, we designated the following settings: region: Netherlands, currency: USD, language: English. Next, we queried the following six products: [shampoo], [bag], [shirt], [deodorant], [multivitamins], [underwear], allowing the tool to capture the results and exporting a CSV of the results after each query. Phase 2: The second phase of the research, which we can call the “pollution” phase, attempted to test the effects of personalization on search results for both signed-in users and anonymous users by creating a “gendered” browsing history. As this was a pollution phase and not a data-collection, we did not download the csv of search results. First, the research conditions of phase one were restored by clearing the cookies and history of the research browser. We used the following research personas: signed-in male user, signed-in female user, anonymous male user, anonymous female user. Each user navigated to amazon.com, and designated the same setting as in Phase 1. To pollute the search history, each user queried a list of the following ten items, one by one: [shampoo], [bag], [shirt], [deodorant], [multivitamins], [underwear], [lotion], [sunglasses], [shoes], [razor]. Once the initial search results were obtained, the user would filter the results by gender using Amazon’s sidebar, which made a designation for these products between those for men and those for women. We filtered the products through Amazon’s own filter as to ensure that the gender bias was originating in Amazon’s categorization of the products, and not those of the researchers. For each of the queries, one or two items of the gendered categories were added to the user’s cart. Phase 3: In phase 3, we investigated whether the creation of a gendered in-store browsing history affected the search results from the query items from phase 1. In order to preserve the browsing history of the research personas, we did not clean cookies or search history between phase 1 and phase 3. In this phase, we continued with the same research personas of phase 2: signed-in male user, signed-in female user, anonymous male user, anonymous female user. Each user navigated to amazon.com, and designated the same settings as in phases 1 and 2. The following items were queried (same as phase 1): [shampoo], [bag], [shirt], [deodorant], [multivitamins], [underwear], and a csv of the results was downloaded after each query using the Amazon Tracking Exposed extension on the Firefox and Brave Browsers.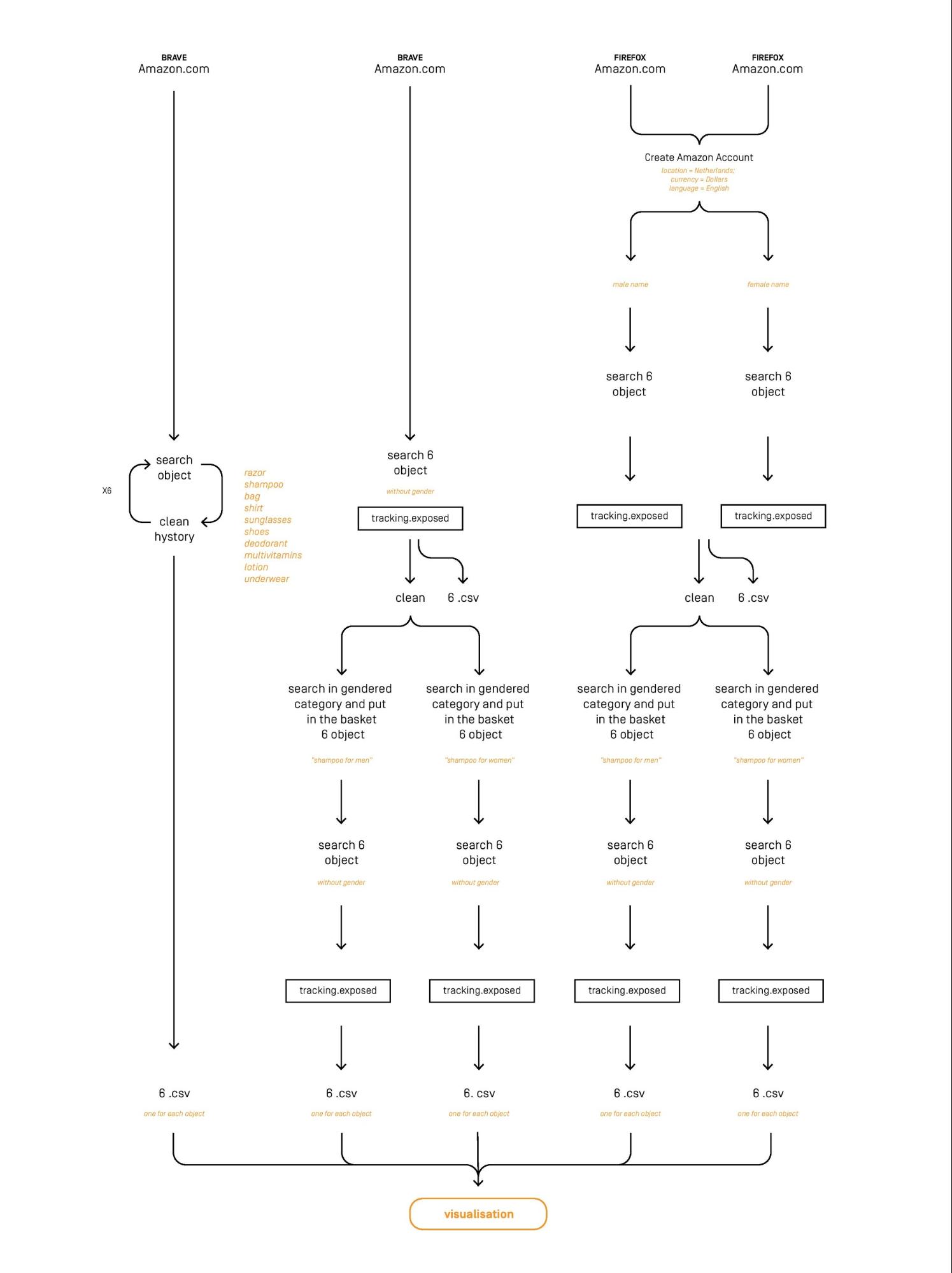 Figure 1: Methodology Part I workflow
Figure 1: Methodology Part I workflow
Methodology - Part II
After an analysis of the results from Part 1 of the research, we decided to turn to the “Recommended products” section of the Amazon interface to test if browsing history and personalization had a more gendered effect on this algorithm. Phase 1: For this phase, we used two research personas: one anonymous male account and one anonymous female account using the Firefox browser. After navigating to amazon.com, the region/language settings were configured identical to the previous phases. Next, the users repeated Phase 2 of Part I by querying the following ten items one at a time: [shampoo], [bag], [shirt], [deodorant], [multivitamins], [underwear], [lotion], [sunglasses], [shoes], [razor], and filtering the search results using Amazon’s sidebar by gender. The top result after filtering was added to the cart. After the item was added to the cart, the products listed in the section “Recommended based on your browsing history” were recorded via screenshot. Phase 2: In the next phase, the product recommendations after each query were analyzed qualitatively using a coding scheme and labeled according to whether they were considered a “male” product, “female” product, or gender-neutral. The products were analyzed for an explicit gender categorization based on the following criteria:- Gender explicitly mentioned in name of product
- A specific gender was specified in the product description
- A specific gender was designated by the “product details” section
- Gendered language deployed in product description, i.e. “a better shave for him.”
5. Findings
Findings - Part I
We expected that users’ browsing history within the Amazon store would have an effect on what kinds of products were recommended to them. For instance, if a user indicated an interest in products designated by the Amazon itself as a “woman’s product,” then search results for gender neutral items would produce subsequently more gendered results. Figure 2 and 3 show that the search results received after creating a “gendered” browsing history did not seem to take gender categories into account. However, we did see that certain products themselves as defined by a query (ie [shirt]) were indeed gendered. The first result can be seen looking at the pre-made gender categorization by Amazon. As it is illustrated in the first two columns of figure 2, the two categories retrieved different results divided on the basis of gender. After identifying the gendered categories pre-assigned by Amazon, we created two profiles assigning a male and female name. Doing so we expected to find some differences in the results for similar products, instead, the findings have shown little significant difference. Firstly, throughout the aforementioned methodology, we have investigated whether this distinction can be produced without choosing the designated categories. To do so we used a clean browser and two new accounts with a female or male name. The results are showcased in the second, the third and the fourth columns of the graph in figure 2. As it can be observed, within the initial phase we did not find significant results. Concerning this first part of our research, we compared the query results for genderized items (e.g. razor) between a clean profile with a female name, one with a male name and one not logged in (Phase 1). Unlike the expected findings, these results remain unchanged even in the final phase (Phase 3), after having added to the cart products that have been gender-coded by Amazon (Phase 2). Figure 2: Overview of the Image analysis of gendered product using clean accounts and browsers.
Figure 2: Overview of the Image analysis of gendered product using clean accounts and browsers.
 Figure 3: Overview of the Image analysis of gendered product using polluted accounts and browsers.
Regarding the order of the products shown, we demonstrated that the algorithm dedicated to “search results” consider neither the gender nor the history of the account. Instead, what is evident, in some cases, is that some queries produce consistently more gendered results (ie, towards males). For this second finding, it is necessary to focus on two specific products: underwear and shirts. Therefore, a profile with a female name and a clean browser got results mainly returned "for male" results. As it can be seen in figures 4 and 5 when comparing the results of both clean and polluted phases, the products list don't change in terms of gendered products. If in the case of underwear, we also find results targeted as feminine. While in the case of shirts, almost all of the results are biased in providing male results.
Figure 3: Overview of the Image analysis of gendered product using polluted accounts and browsers.
Regarding the order of the products shown, we demonstrated that the algorithm dedicated to “search results” consider neither the gender nor the history of the account. Instead, what is evident, in some cases, is that some queries produce consistently more gendered results (ie, towards males). For this second finding, it is necessary to focus on two specific products: underwear and shirts. Therefore, a profile with a female name and a clean browser got results mainly returned "for male" results. As it can be seen in figures 4 and 5 when comparing the results of both clean and polluted phases, the products list don't change in terms of gendered products. If in the case of underwear, we also find results targeted as feminine. While in the case of shirts, almost all of the results are biased in providing male results.
 Figure 4: Close up of the Image analysis of gendered product using clean accounts and browsers. Underwear and Shirt.
Figure 4: Close up of the Image analysis of gendered product using clean accounts and browsers. Underwear and Shirt.
 Figure 5: Close Up of the Image analysis of gendered product using polluted accounts and browsers. Underwear and Shirt.
Figure 5: Close Up of the Image analysis of gendered product using polluted accounts and browsers. Underwear and Shirt.
Findings - Part II
Figure 6 illustrates the percentage of gender-targeted items suggested to a user that, without being logged in with an Amazon account, proceeded to query gender-coded products and adding to the cart the first result coded by Amazon as a women’s product. As mentioned above, Amazon’s gender-coding was inferred by either specific mentions in the product’s names or description (i.e.: for women, female, or consistent employment of pronouns such as she/her/hers), or by the Amazon gender-categories attached to the product (i.e.: women's disposable shaving razors, women’s fashion, ...). The line graph shows how, despite having added to the cart a product targeted by Amazon to a female public, the “recommended for you based on [last item added to the cart]” algorithms initially suggests mostly products targeted to male consumers. Nonetheless, this trend is reversed after the second product has been added to the cart: it is worth noticing how, until this moment, the number of products deemed by Amazon as female-targeted and the number of products deemed as unisex are equivalent. Once the third product has been added to the cart, female-targeted items are consistently predominant among the suggested products. After the fourth product has been added to the cart, the tendency remains quite stable showing a predominant amount of female-coded products which remains constant around 60% - 80% and a paltry presence of both male-coded and unisex products which are each consistently inferior to the 20%. Interestingly, male-coded products appear slightly more frequently than unisex products. Figure 6: Percentage of female-coded, male-coded and unisex products suggested after adding to the cart any further female-coded product.
Similarly, figure 7 represents the percentage of gender-targeted items suggested to a user that, without being logged in with an Amazon account, queries gender-coded products and adds to the cart the first result coded by Amazon as a male’s product. The results differ substantially if compared to the previous figure: in this case, after adding a first item coded by Amazon as a male-targeted product, the suggestions are equally distributed between male-coded and female-coded products with no unisex product at all. After adding a second male-targeted product to the cart, male-coded products peak exponentially and female-coded products plunge to zero. Every further male-coded product added to the cart, provokes a gradual decline in the amount of male-targeted products and a steady growth in the number of unisex products; however, male-coded products constantly remain the bulk of the suggestions whereas female-coded products do not appear at all in any subsequent suggestion.
Figure 6: Percentage of female-coded, male-coded and unisex products suggested after adding to the cart any further female-coded product.
Similarly, figure 7 represents the percentage of gender-targeted items suggested to a user that, without being logged in with an Amazon account, queries gender-coded products and adds to the cart the first result coded by Amazon as a male’s product. The results differ substantially if compared to the previous figure: in this case, after adding a first item coded by Amazon as a male-targeted product, the suggestions are equally distributed between male-coded and female-coded products with no unisex product at all. After adding a second male-targeted product to the cart, male-coded products peak exponentially and female-coded products plunge to zero. Every further male-coded product added to the cart, provokes a gradual decline in the amount of male-targeted products and a steady growth in the number of unisex products; however, male-coded products constantly remain the bulk of the suggestions whereas female-coded products do not appear at all in any subsequent suggestion.
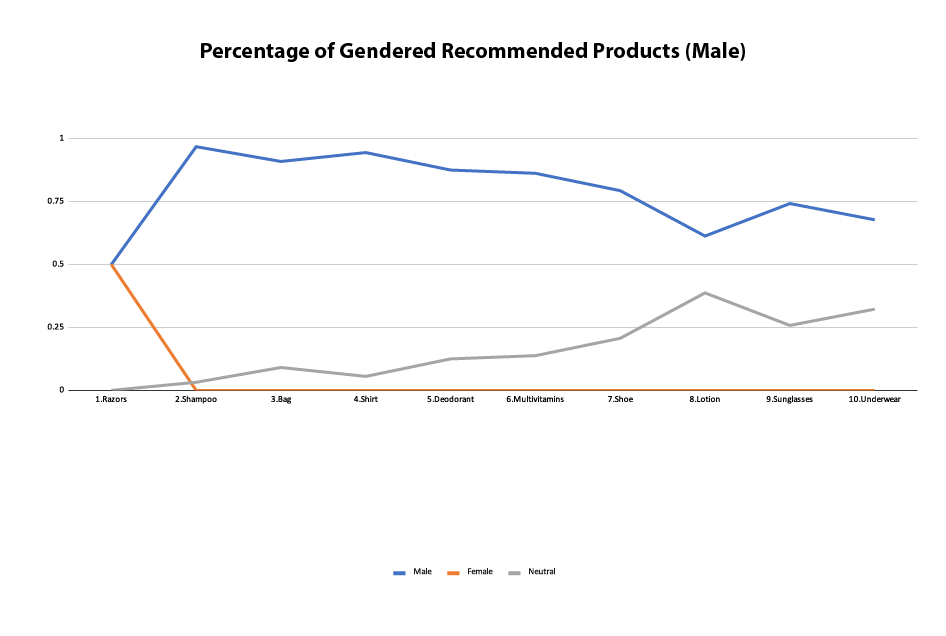 Figure 7: Percentage of female-coded, male-coded and unisex products suggested after adding to the cart any further male-coded product.
Figure 7: Percentage of female-coded, male-coded and unisex products suggested after adding to the cart any further male-coded product.
6. Discussion: Two different algorithms
The public perception of platforms as united wholes often obfuscates the complexity of the algorithmic systems that support their multitudinous functions. Sandvig argues that this generalization is symptomatic of colloquial language and that it serves as “shorthand for high-level assemblies of many sub-algorithms, all eventually implemented and running as computer programs.” (“Seeing the sort”) Yet, Burrell warns that conflations of these systems produces opacity, which not only users but also the programmers, who supposedly take on the role of ‘insiders.’ (3-4) The oversimplification of these systems mistakenly conveys the impression that ‘auditors’ could potentially resolve potential problems that arise from the software systems, or help to enhance credibility for the platforms. This idea of algorithmic complexity and opacity was reflected in our findings, in which an experiment testing one or two variables at a time did not manipulate “the algorithm” as we expected. What this also seems to suggest is that the threshold of personalization might be higher than expected. In other words, in order to more obviously personalize search results, Amazon might need a more robust user profile created from different kinds of data. If algorithms are “multi-component systems built by teams,” (Burrell 4) how can everyday users grasp the differences among them? FIrstly, one must grasp why specific knowledge about algorithms is so elusive. Whereas it is easy to pin ignorance on the lack of specialized programming and computational skills on the part of users, or even the “obscure locations in the recesses of trade history” (Seaver 413), the true culprit is that these essentially superficial problems mislead us into thinking that algorithms, or more specifically algorithmic reasonings, are truly even knowable at all (Seaver 413). Therefore, the algorithmic unknown becomes in itself a challenge for us to crack, a quest for the ultimate truth, a binary division between knowledge and ignorance (Seaver 414). As Tayna Bucher aptly points out, that “the metaphor of the black box constitutes such interference” and suggests that focussing our efforts on what can be known is a much more meaningful endeavor (47). In fact, we should pay special attention to the moments when these algorithmic systems become eventful (Bucher 48). By comparing the results from our two projects we came precisely to such a moment of eventfulness. We were able to detect two algorithmic systems at play; one of which proved to be difficult to corrupt and presented us with no variation in results throughout testing; and another, which was easily corruptible by so much as adding a few gendered items to our cart. The moment at which this striking difference between the results from the two methodologies was revealed to us is, arguably, a moment of eventfulness. For one, it is evidence that, whilst Amazon, as a platform, interfaces with the user as one, creating a unified experience, there are multiple algorithms constructing this image beyond the graphical user interface. Additionally, this result adds to the explanations of the constant variations for results across our projects in the greater scope of “Amazon Tracking Exposed.” As Bucher notes, the multiplicity of algorithms “pertains to their constantly changing nature” (48). This plurality in algorithmic systems may also factor into the bias we were able to detect for the gender coding of particular products. As we showcased above, while all the products we looked at were previously gender coded by Amazon, the items “underwear” and “shirt” provided more results aimed at men compared to women, even when the holder of a “female” account browsed while logged in. It appears that whereas gender coding does hold important influence within the Amazon ecosystem, the selection of items presented to a user are more complicated than initially anticipated. However this research has been limited in terms of providing an explanation for this. It may be the case that the language used to search for these items is preferred by men, or it may be the case that Amazon has a larger collection of male shirts compared to female. Further research could conduct more extensive testing and gather more data in that direction. Last but not least, while many consider gender as a salient marker of their personal identity, social media and commercial platforms alike should be aware that their “programming practices may inadvertently advocate for certain groups of people while alienating others.” (Binners) Therefore, we should be particularly vigilant regarding the issue of one gender, the male in our case, becoming the ‘default’ for certain products.7. Conclusion
This research process also questions the feasibility of using a similar technical tool to “expose” algorithmic systems on Amazon as those applied to Facebook and YouTube. Apart from arguing the variation and complexity of algorithm systems, both Facebook and YouTube inhabit in an environment of liaison with “share”, “free” and “gift” culture as the properties of diverse media platforms are assorted. Their main financial incomes most likely rely on the advertising revenues, whereas Amazon is profiting from the sponsors and charging the platform service fees from the users. Thus, the algorithms of personalization within e-commerce are likely genetically different from those of social media. The tracking tool might also consider a before/after payment variable, otherwise the noise around further analytic tools exposing Amazon computational systems would be hardly eliminated manually against the complexity of the algorithms. This is plausibly one of the reasons that TREX tool performs less effectively on Amazon than its data crawling on Facebook or YouTube; and, the research results are constrained by the methodologies this project applies, as well as by the relatively small scale of our A/B testing methodology.8. References
Bibliography
Bivens, Rena, and Oliver L. Haimson. “Baking Gender into Social Media Design: How Platforms Shape Categories for Users and Advertisers.” Social Media + Society, vol. 2, no. 4, 2016, 2056305116672486. Bucher, Taina. If... then: Algorithmic Power and Politics. Oxford University Press, 2018. Burrell, Jenna. “How the Machine ‘Thinks’: Understanding Opacity in Machine Learning Algorithms.” Big Data & Society, vol 3, no. 1, 2016, 2053951715622512. Chai, Zenghao, Zhiyuan Fang, and Jie Zhu. “Amazons Evaluation Optimization Strategy Based on PSO Algorithm.” 2019 Chinese Control and Decision Conference (CCDC). IEEE, 2019. Cheney-Lippold, John. We Are Data: Algorithms and the Making of Our Digital Selves. New York University Press, 2017. Sandvig, Christian. “Seeing the Sort: The Aesthetic and Industrial Defense of ‘the Algorithm’.” Media-N: Journal of the New Media Caucus, 2014. Seaver, Nick. “Knowing Algorithms.” Media in Transition 8 Conference. Massachusetts Institute of Technology, 2013. Weinberger, David. Everyday Chaos: Technology, Complexity, and How We’re Thriving in a New World of Possibility. Harvard Business Review Press, 2019.Websites
Uberoi, Ravneet. “Zara: Achieving the ‘Fast’ in Fast Fashion through Analytics”. Harvard Business School, 5 Apr. 2017. https://digital.hbs.edu/platform-digit/submission/zara-achieving-the-fast-in-fast-fashion-through-analytics/ Big Data Big World. https://bigdatabigworld.wordpress.com/2014/11/25/beer-and-nappies/ Amazon. https://aws.amazon.com/cn/blogs/machine-learning/creating-a-recommendation-engine-using-amazon-personalize/This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant agreement No 825974-ALEX, with Stefania Milan as Principal Investigator; https://algorithms.exposed).
Edit | Attach | Print version | History: r2 < r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r2 - 14 Feb 2020, MarkDavis
Ideas, requests, problems regarding Foswiki? Send feedback