Haters Gonna Hate: dissecting hate speech on social media
Team Members in alphabetical order
Berenika BalcerMatthias Becker
Nika Borovskikh
Anniek de Koning
Marta Espuny
Veronica Fanzio
Harry Febrian
Vania Ferreira
Claudia Globisch
Tamar Hellinga
Adriana Munteanu
Leonardo Sanna
Noemi Schiavi
Hannah Smyth
Job Vossen Contents
1. Introduction
In April 2018, Mark Zuckerberg promised that Facebook AI system would be able to detect hate speech automatically within his platform. In fact, over the past years the problem has become increasingly urgent for the company, to such an extent that recently political groups and pages have started being deplatformed. One of the most frequent accusations to deplatformed individuals and groups is that they had used “hate speech” within Facebook. Although on the one hand the deplatforming process seems to be effective in detoxing digital environments, on the other hand the automatic detection of hate speech can jeopardize freedom of speech. Hence, we intend to investigate hate speech starting from its official definition by the European Commission, which considers it “as the public incitement to violence or hatred directed to groups or individuals on the basis of certain characteristics, including race, colour, religion, descent and national or ethnic origin”.
Nonetheless, this definition is too blurred to be acceptable from a linguistic point of view. Hate speech is in fact a linguistic phenomenon which is impossible to understand if we neglect cultural context, which means that in our own culture there are innocuous expressions that might be considered very offensive elsewhere. Moreover, we must consider that “a public incitement to violence or hatred”, might be expressed at various semantic degrees. For instance, homophobia might be expressed very openly, by saying aggressive words or something like ”Gay sex is disgusting”, although it is perfectly possible to express the same concept with different and less offensive words, maybe by saying “I’ve got a lot of gay friends, but they should not kiss each other in public because it’s inconvenient”. Last but not least, swear words can be used ironically, so that they lose any aggressive potential.
While the majority of academic studies have been focusing on detecting, measuring and highlighting hate speech on social media, we mean to outline a critical perspective on the concept of hate speech itself. Through semiotic and linguistic analysis, we will focus on hate speech in political communication, by examining both politicians/influencers’ social media accounts and online conversations among ordinary people.
The basic hypothesis behind this work is that hate speech has to be investigated inquiring semantic prosody (Sinclair 1991, Louw 1993) instead of simply creating a blacklist of words to block and/or measure hate online.3. Research Questions
In order to investigate how it is possibile to approach hate speech this project focused on the following questions
1) How valuable is the use of hatebase.org as a repository of multilingual hate speech?
Hatebase is an online crowdsourced database which includes almost 100 languages. It's basically a vocabulary of hateful words. Each word has a label that identifies the target of hate speech (Gender, Sexual Orientation, Religion, Ethnicity) and it has also a score that is used to determine if a word is "always" offensive or if it is ambiguous.
2) Is neutral a synonim of non-hateful?
Semantic prosody might affect also words that are considered to be neutral.
3) Which words can trigger explicit hate?
In a perspective in which hate speech could come in many flavours, one way to analyse it could be trying to spot words that trigger explicit hateful reactions.
4. Methodology and initial datasets
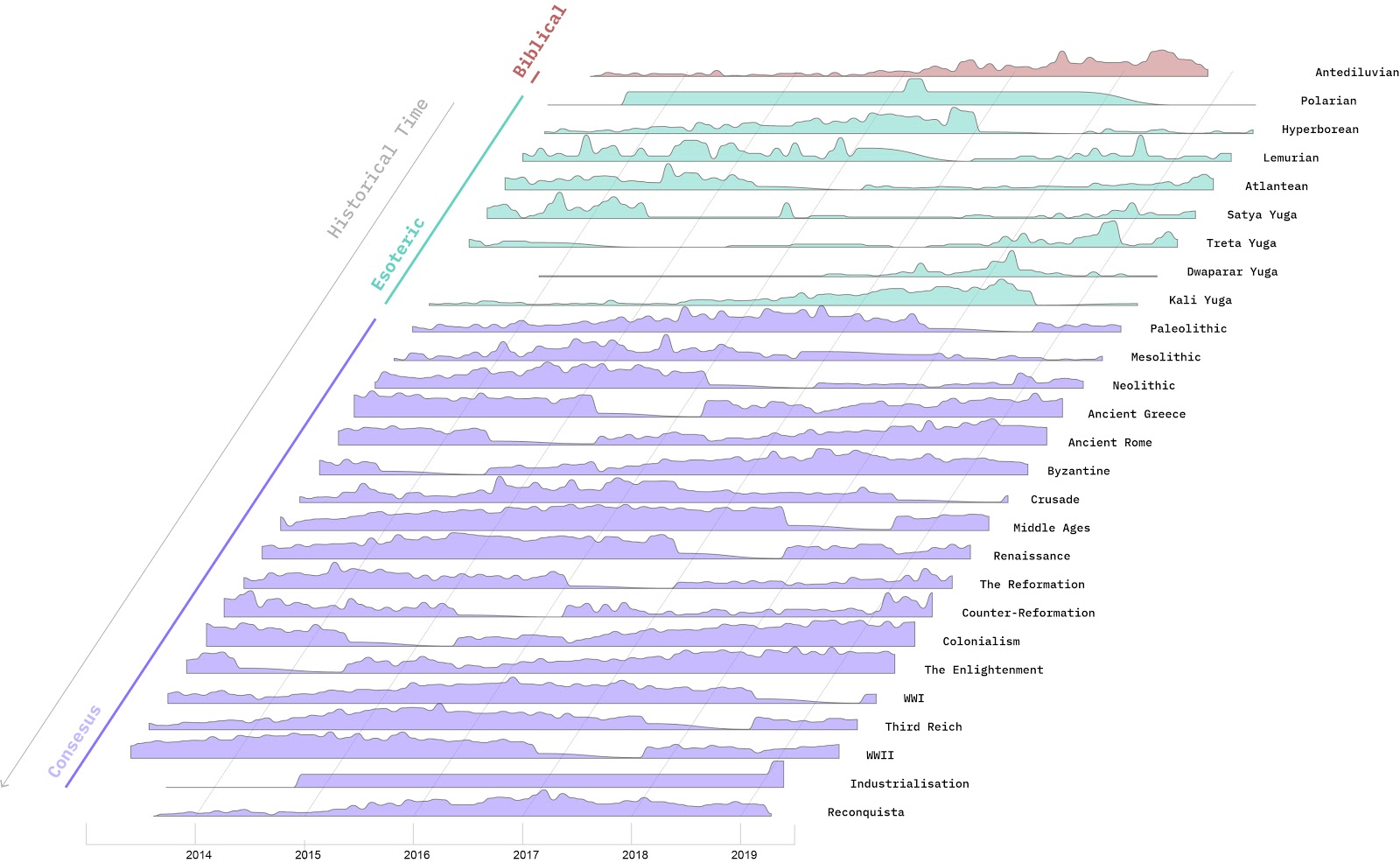
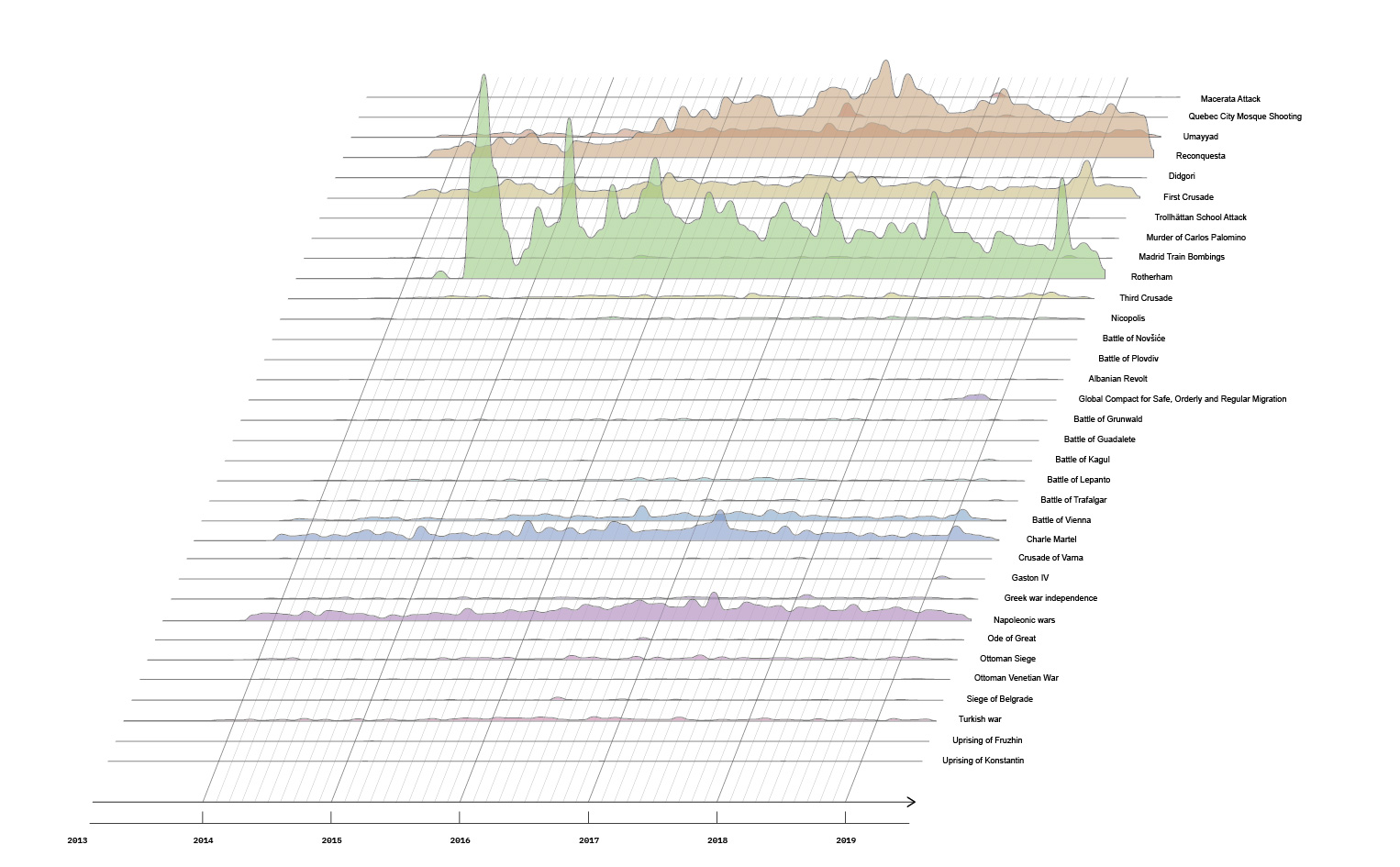
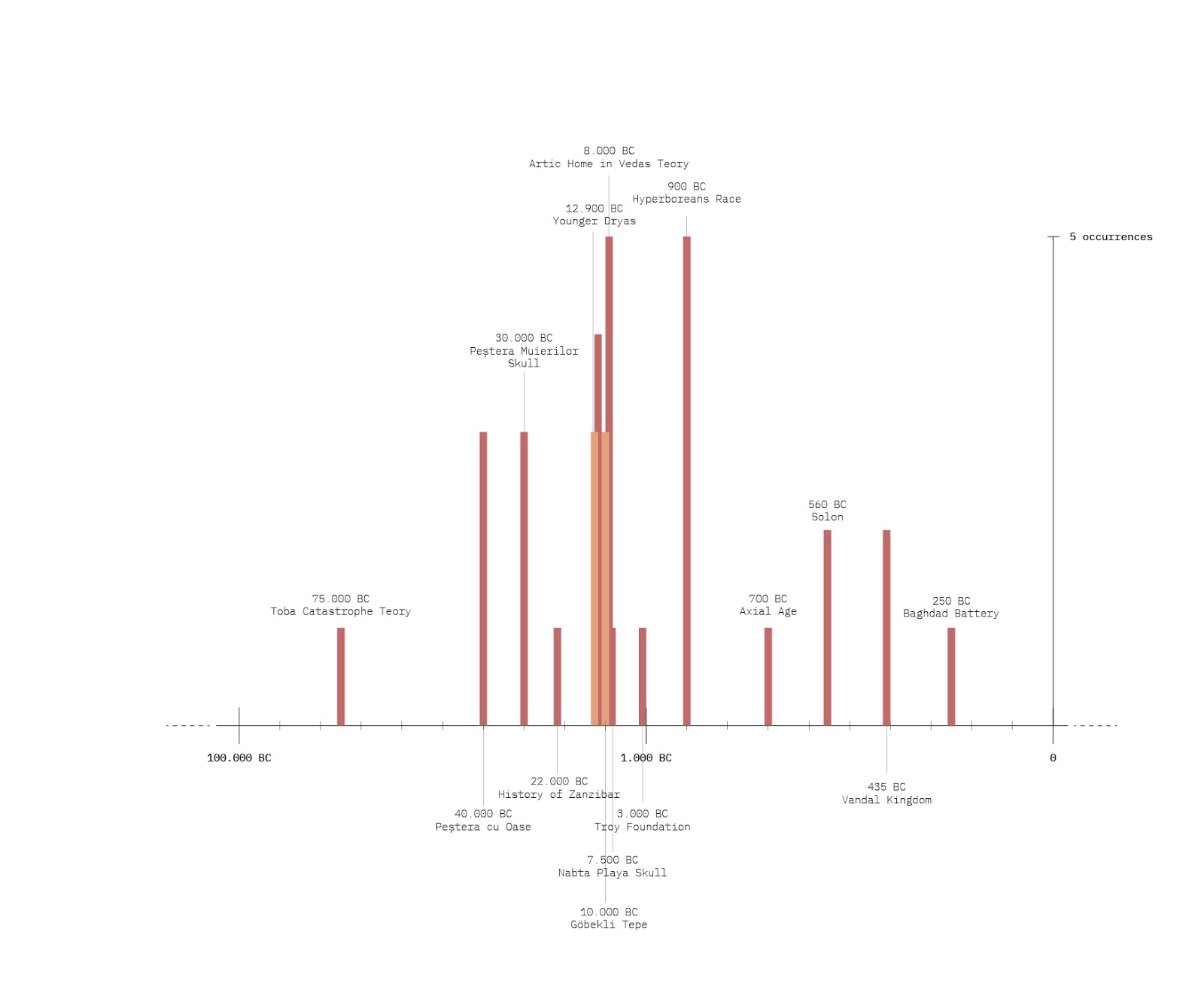
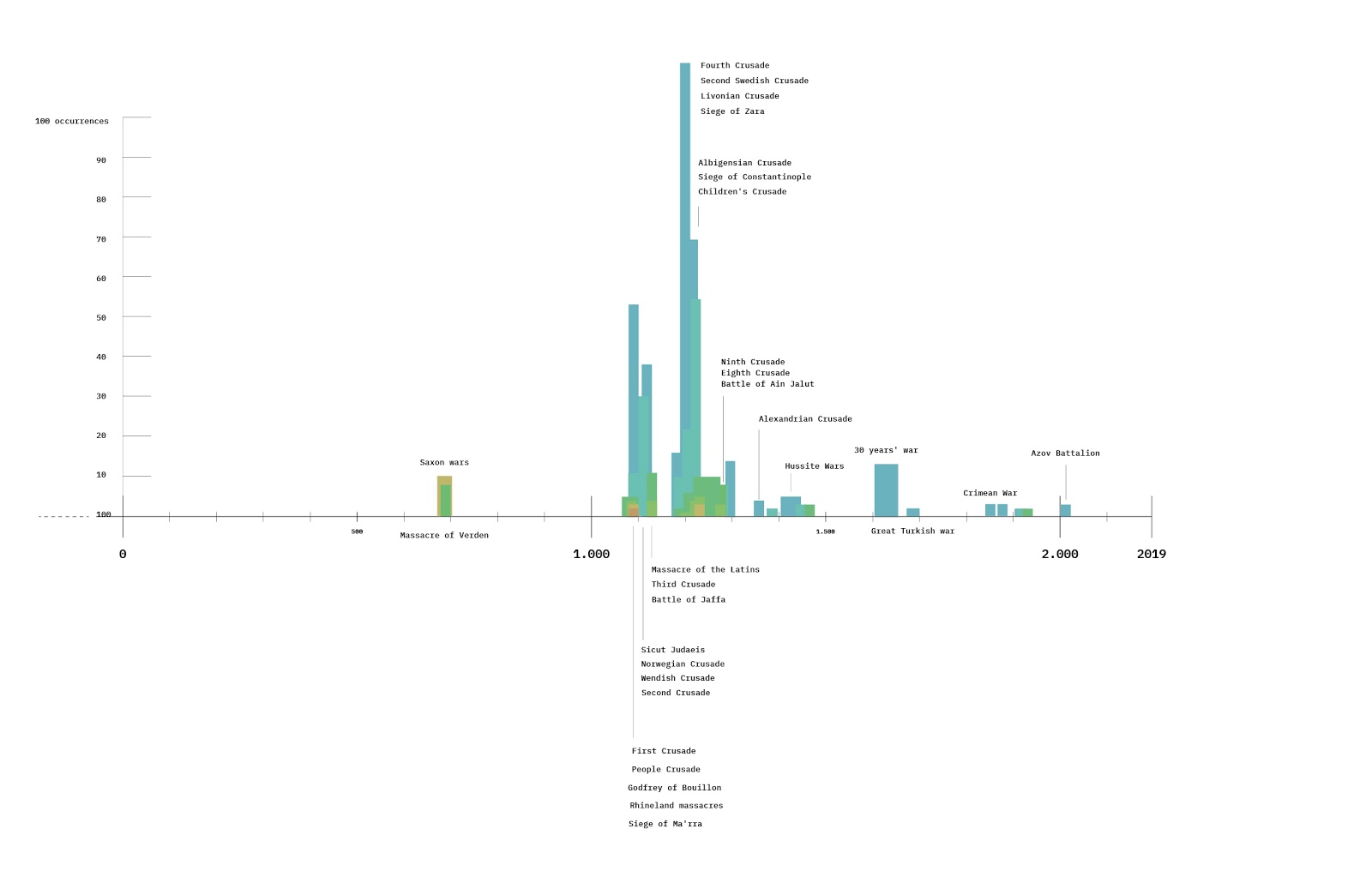
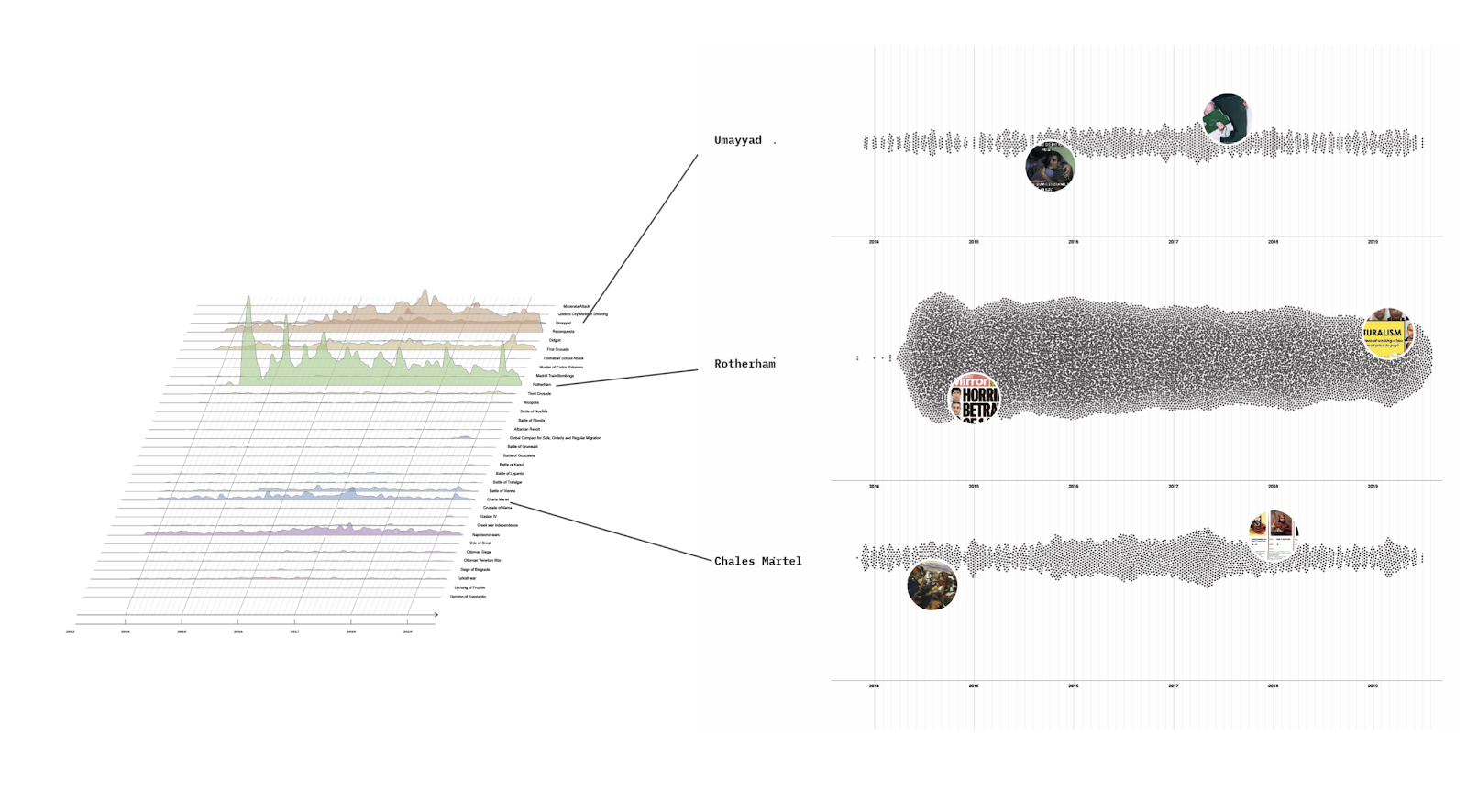
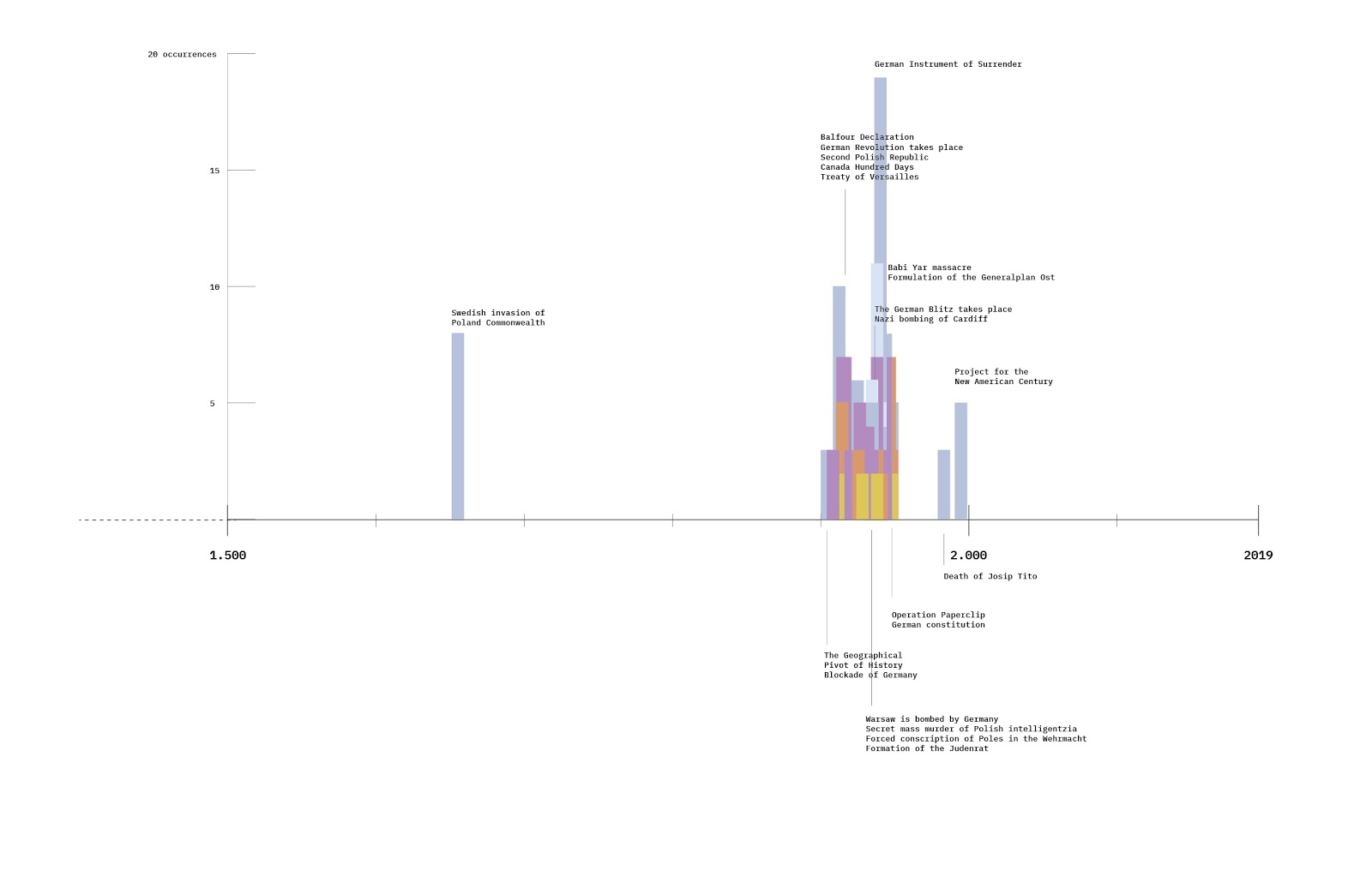
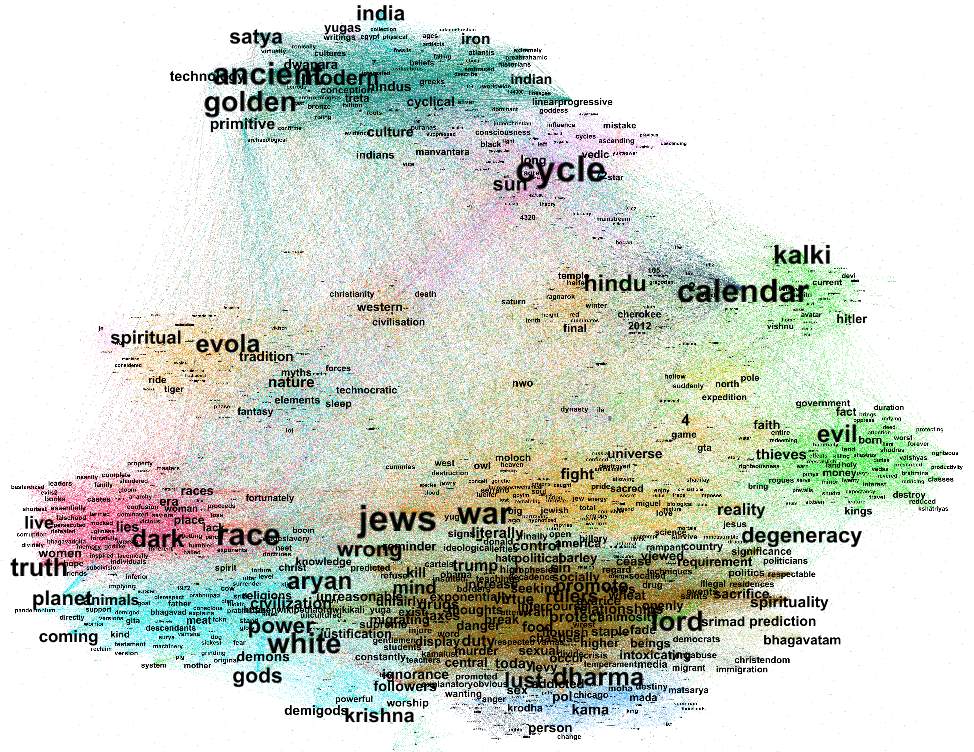
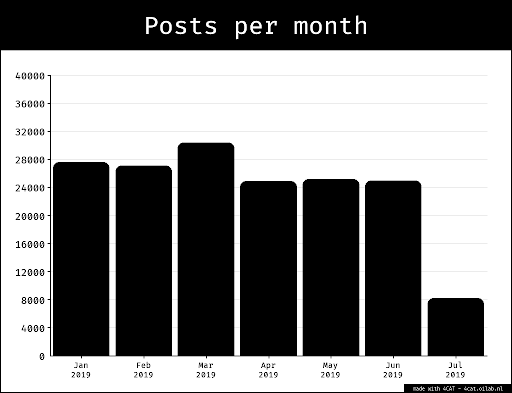
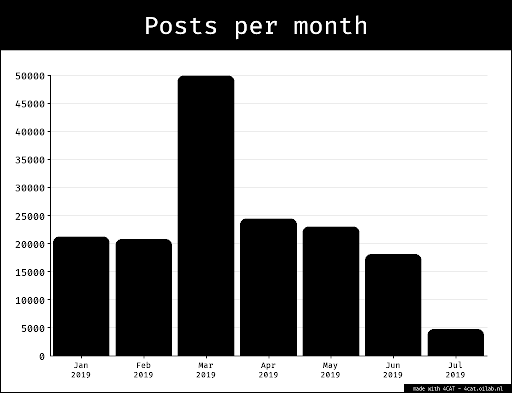
The starting point was the existing dataset on alt-right celebrities on Telegram. This dataset has been used as reference corpus, to have a repository of semantic prosody of possibly hate-speech-related words. The dataset was made of the 10 most active alt-right US channels; the data has been collected with 4CAT in October 2019, each channel has been scraped since its beginning.
The dataset was also explored with hatebase, to see how much (and which kind) of hate speech was present.

The reference corpus has then been processed with word embedding to investigate the semantic model of the alt-right community
4.1 Word Embedding
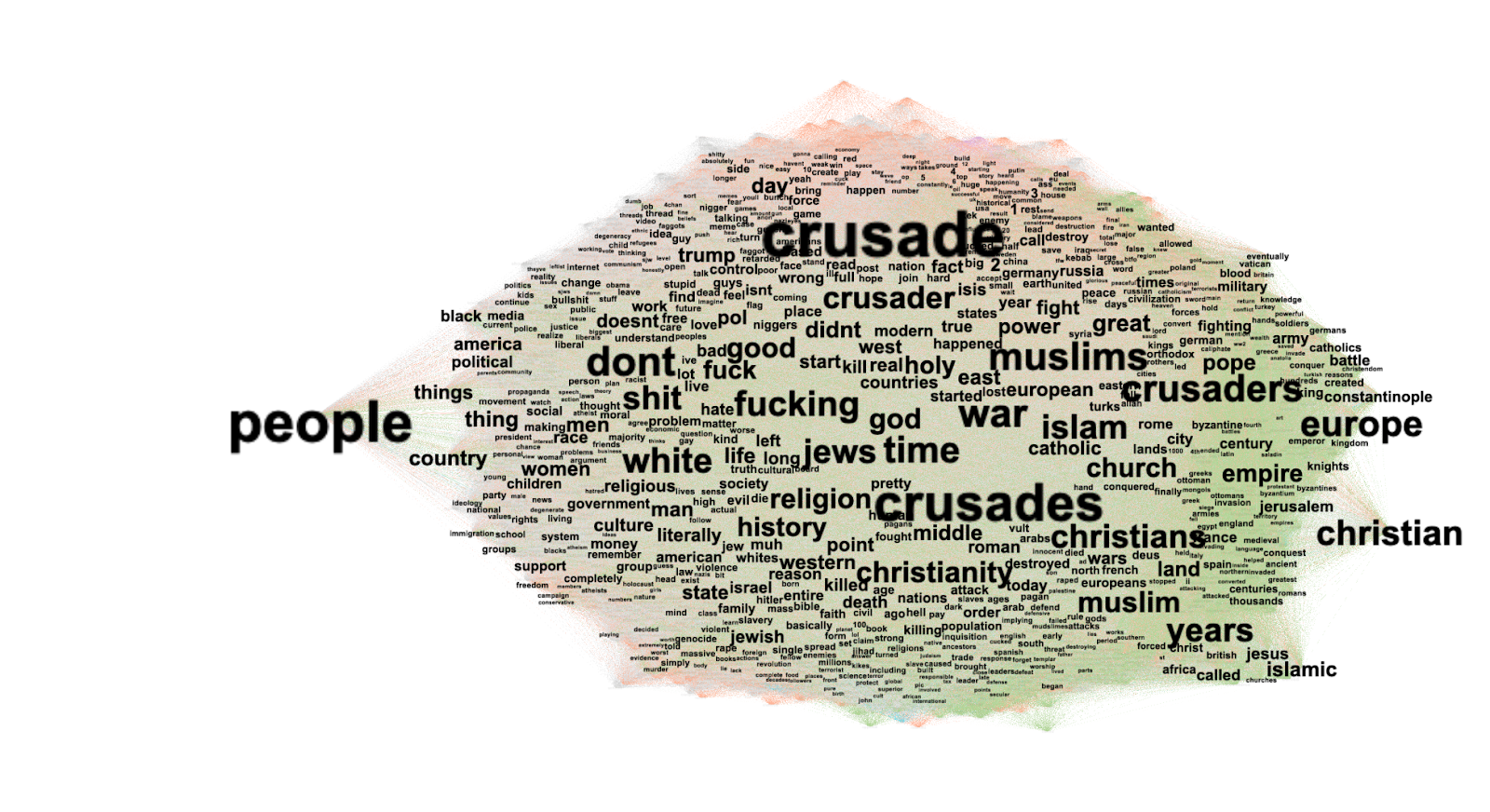
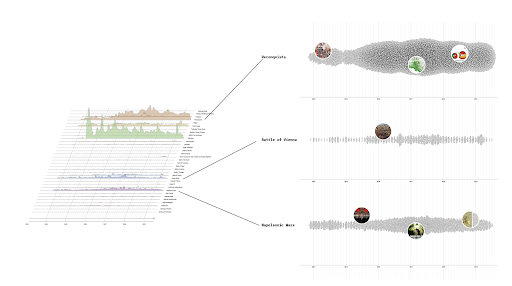
Word embedding is a set of machine learning techniques is used in Natural Language Processing to create a semantic model of the language that can be explored and visualized. The main idea is that every word is mapped to a vector and then represented is a geometrical n-dimensional space; words with similar meaning are represented close to each other while words that have less semantic relation are represented more distant in the space. The basic concept on which word embeddings are founded is what is called the distributional hypothesis (Harris 1954). This hypothesis basically affirms that similar words usually occur in the same contexts.
In this work we used the renowned word2vec (Mikolov et al. 2013) to create our embeddings. The embedding were then visualized within the projector of Tensorboard, to visualize their semantic frame (Fillmore 1976, Eco 1979).
Basically, word embedding creates a geometrical representation of a corpus that is based on the probability of co-occurrence among words, meaning that it can also capture semantic relations that are in absentia, i.e. between words that never co-occur in the corpus whilst having a similar meaning. Using word embedding allows us to capture latent semantic relations to explore deeply our corpus.
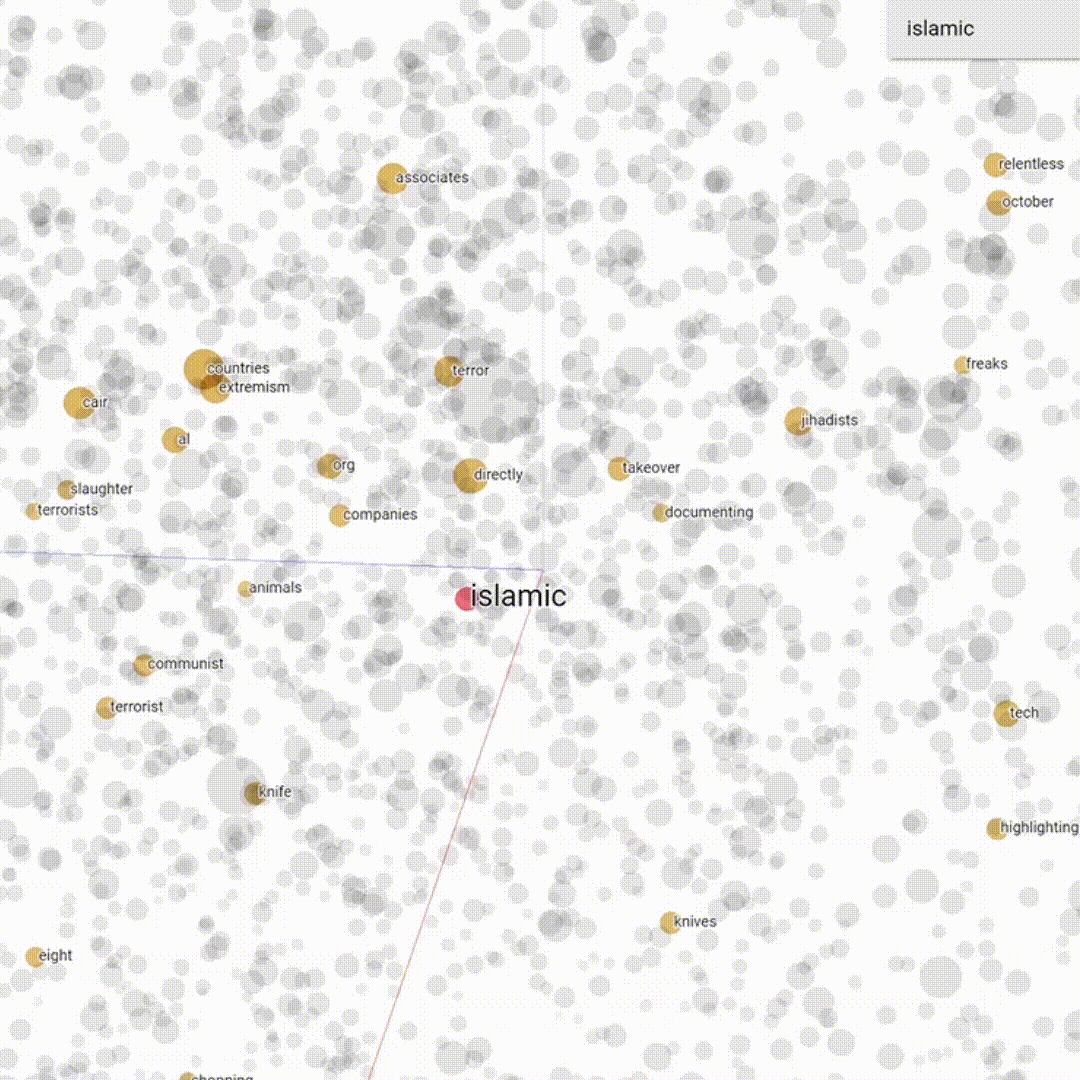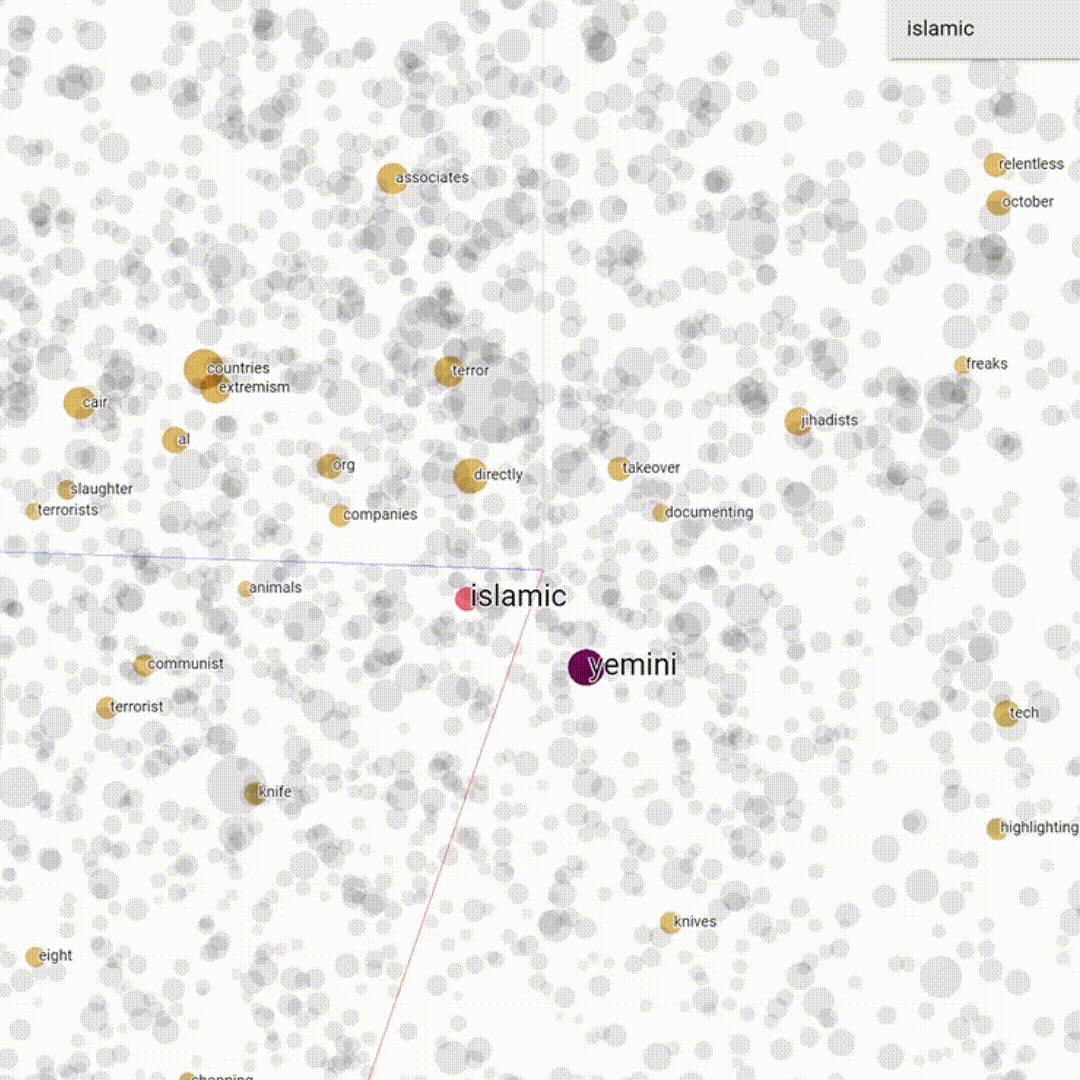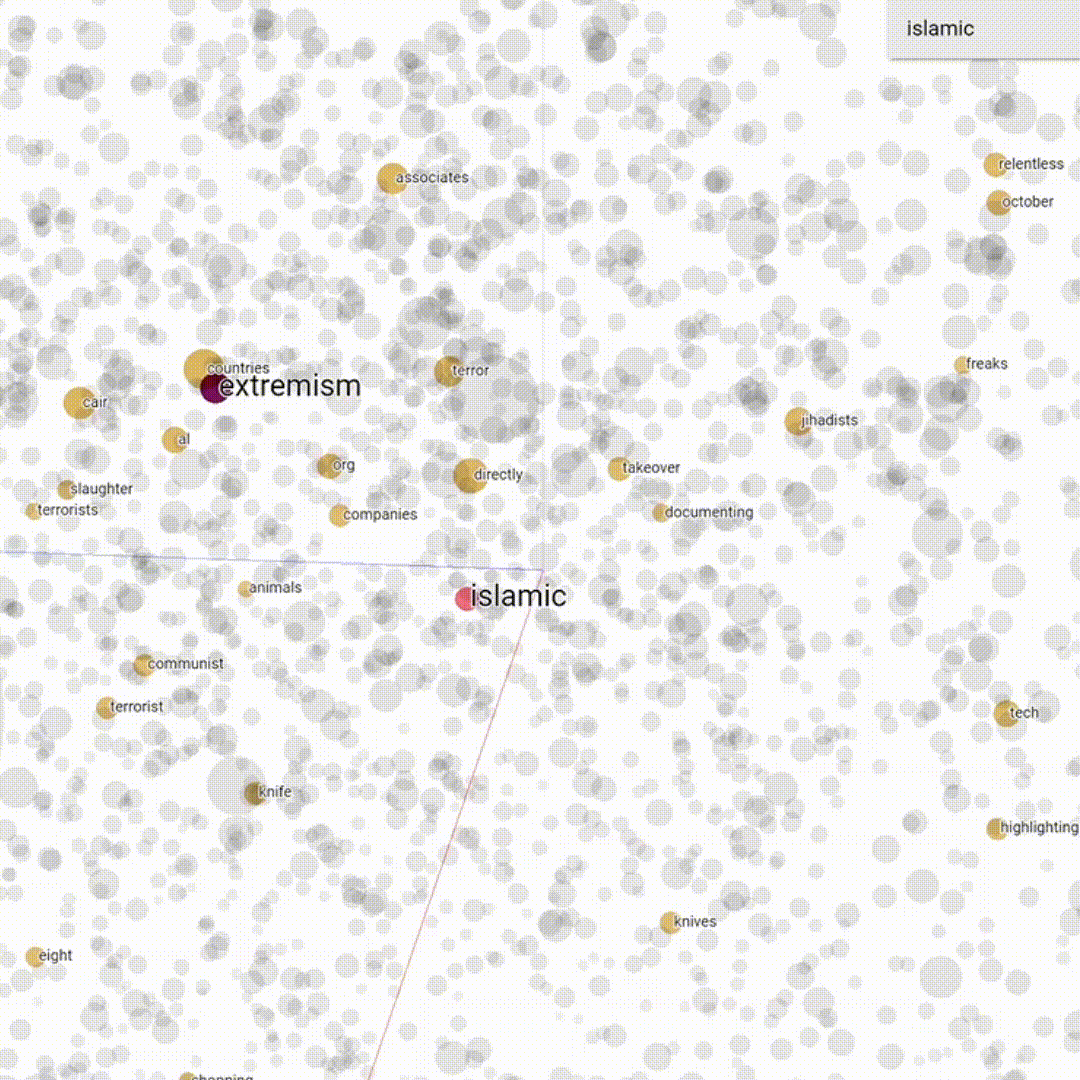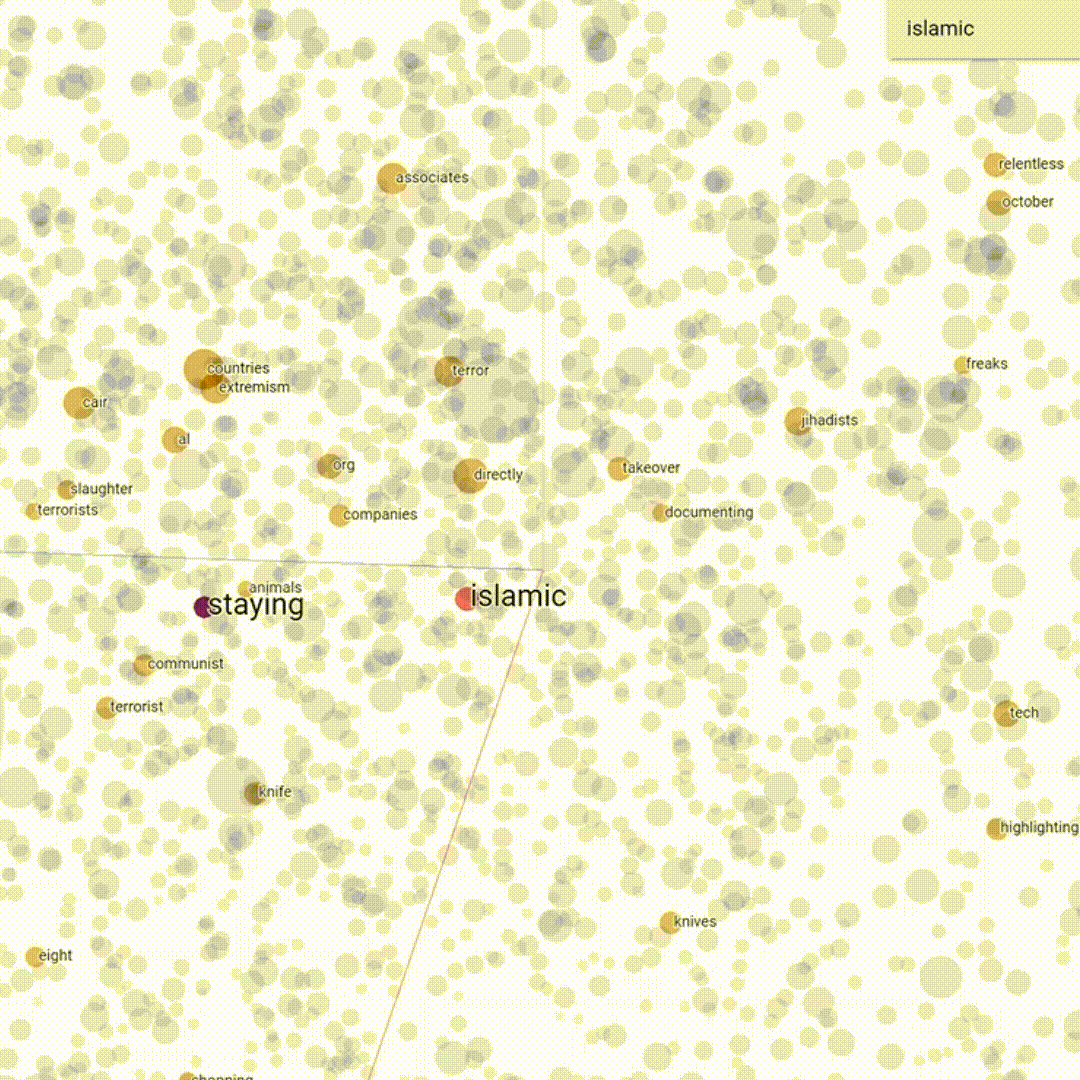
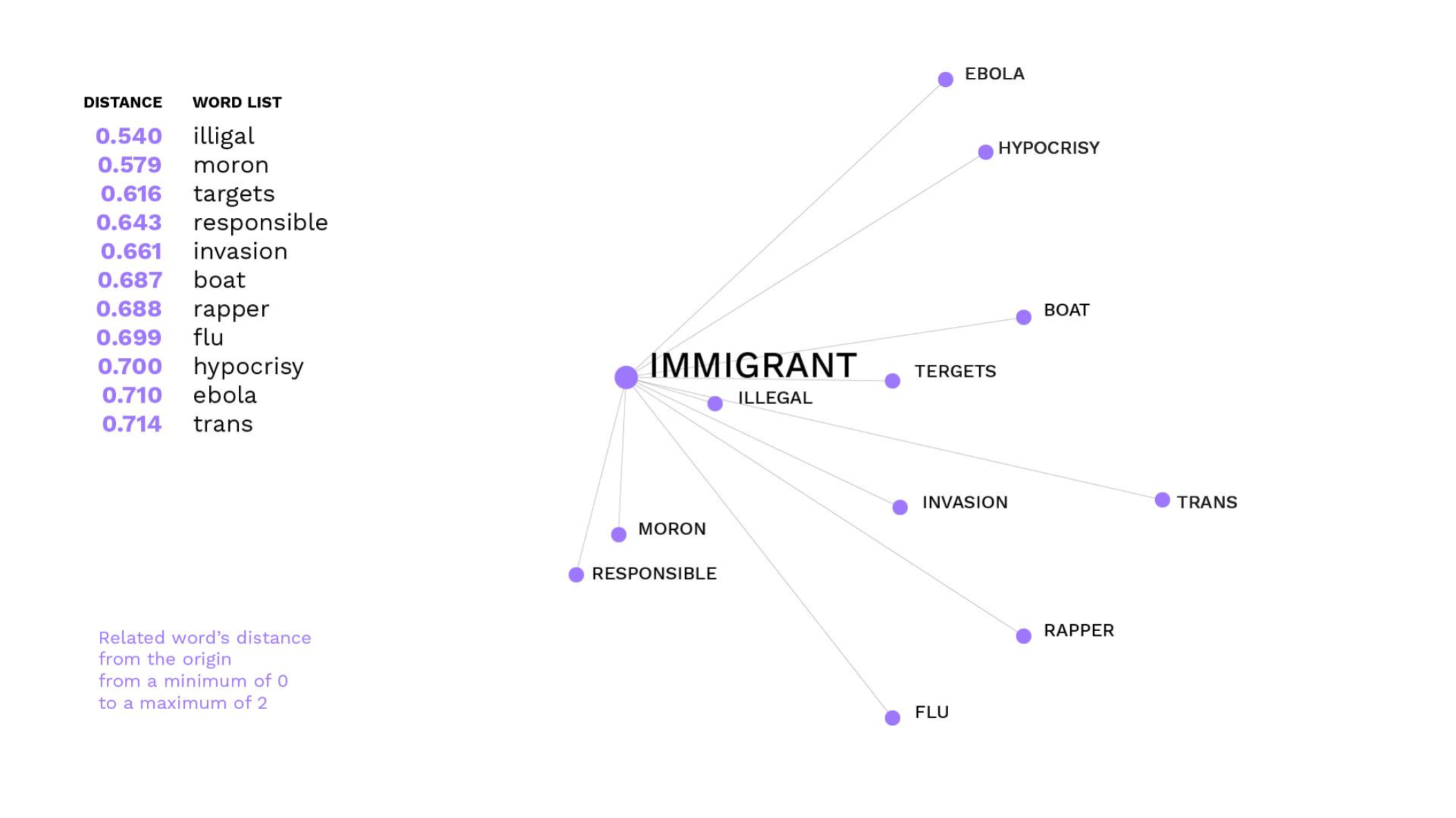
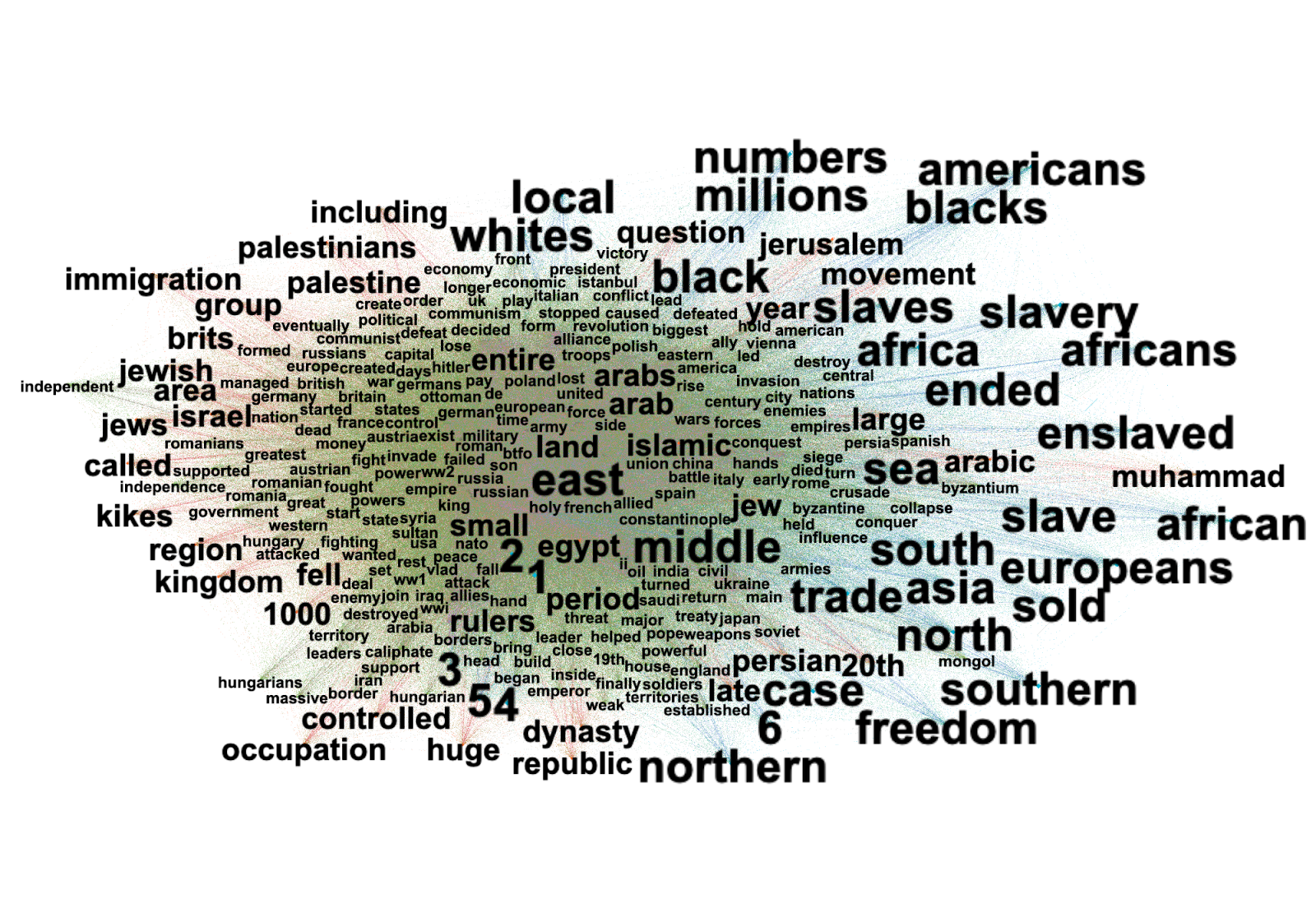
We then created a word list of most frequent words in our corpus using AntConc. This list was used to find what we called trigger words, hence neutral words having a negative semantic framing and therefore potentially used to vehiculate hate speech. We then divided our trigger words according to hatebase categories. For instance, the word "feminist", although being clearly non-hateful had a very negative semantic frame in our corpus. Hence, it is possible that the use of this word might suggest or trigger hateful behaviour.
Finally, we used the word list of the reference corpus has then been used to make a qualitative analysis on a sample of Trump tweets, taking into account all the tweets made by Trump since the beginning of 2020 and analysing the first 100 replies for each tweet. The goal was to spot hateful language within the replies to Trump's tweets.
.gif)
5. Findings
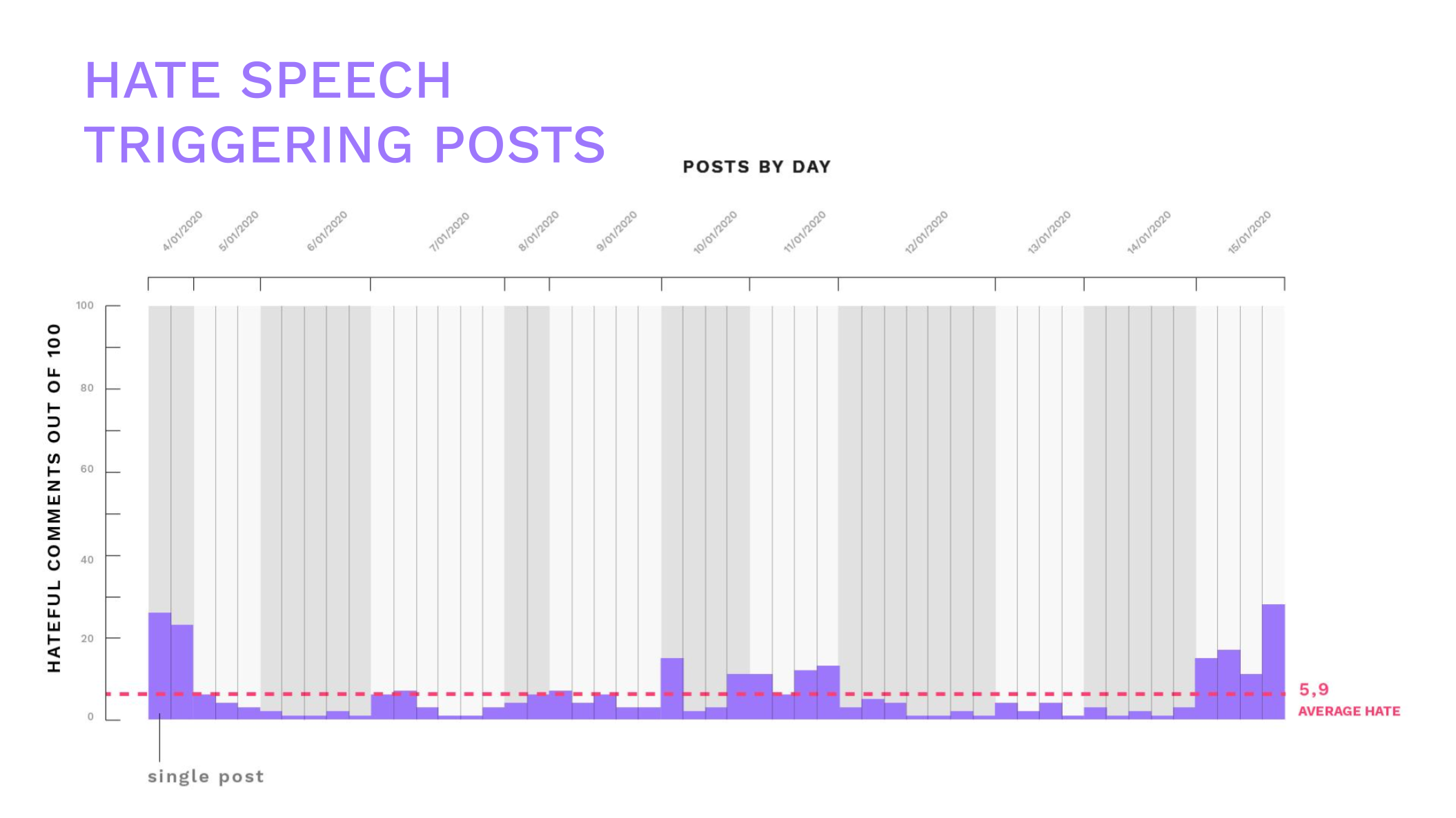
Despite we measured a drop of hate speech with hatebase.org, we found that hateful content was still being evoked within words' frames. This shows that hate speech is not the only way to vehiculate hateful content
.png)
This shows that hatebase, and generally measure-based approach to hate speech have some heavy limitations and instead hate speech should be mapped with semantic analysis.
Also, non-hateful words were proved of causing hate speech online. In our qualitative part, words related to immigrants or to political opponents (like Nancy Pelosi) triggered quite nasty reactions within the Twitter conversation. We made a typology of the four more relevant hateful behaviours that were triggered by non-hateful trigger words.
- Blocking
- Hate exposed
- Hateful fireback
- Hateful Random
6. Discussion
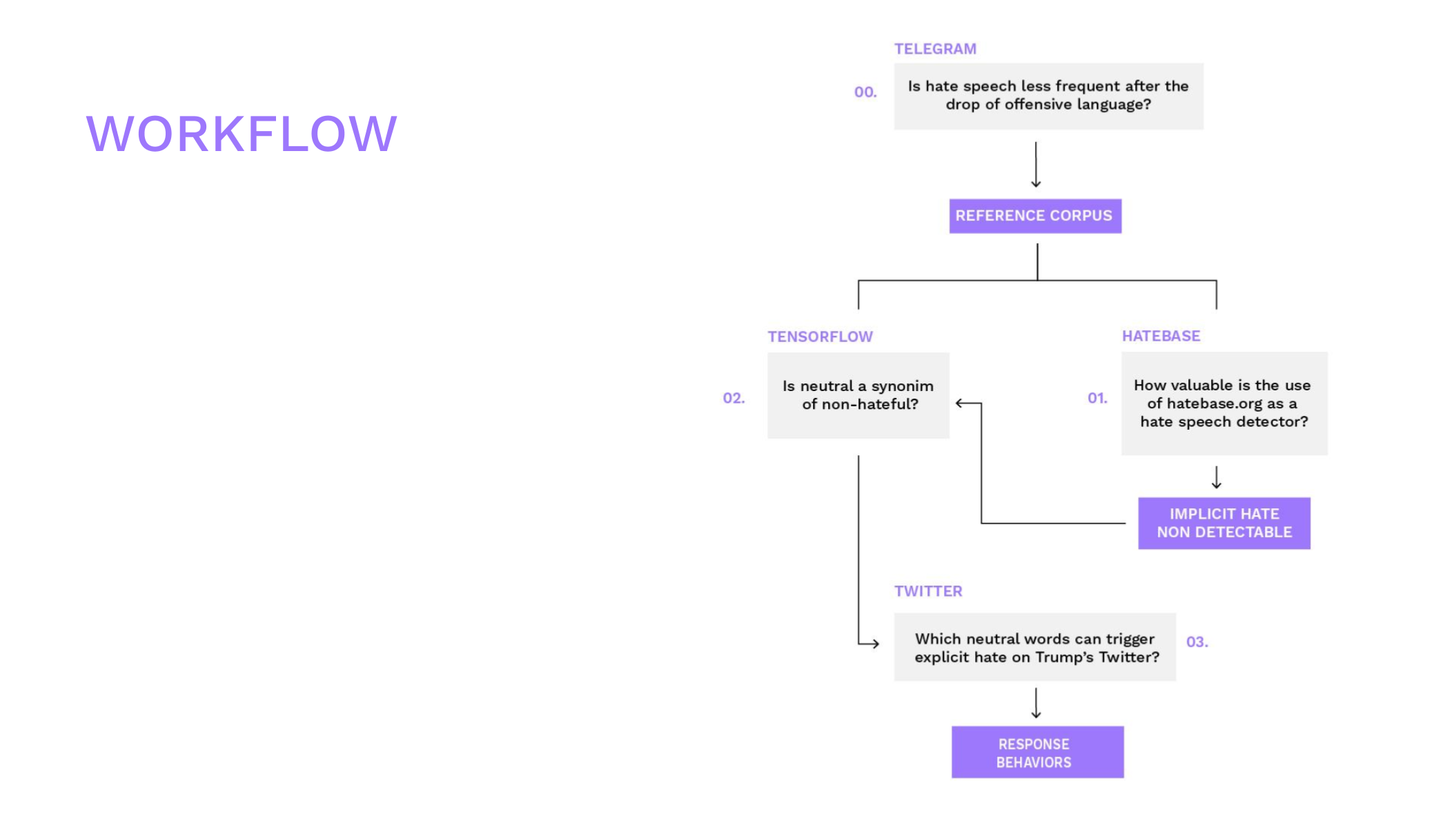
Having a reference corpus to spot possible trigger words seems a valuable approach for hate speech analysis. On the other hand, despite its limitations, hatebase could be used for a prelimiary exploration of the data. It is in fact quite useful to segment the topics of hate speech in the corpus, so that it is easier to understand which trigger words should be investigated. On the other hand, for a multilingual approach hatebase showed limitations due to its heterogeneity; however, for further research, one clear advantage of using hatebase is that, being crowdsourced, it might be enriched with the language we need. However, the pure measuring of hate speech doesn't say a lot about it and it might also be inaccurate, especially for ambiguous terms. We argue that the use of word embedding might enhance a lot the evolution and the nature of hate speech in a given community. Nevertheless, the use of "trigger words" needs further investigation. In fact, within the sample of tweets investigated only a small part of them contained triggered behaviours. It also seems that the triggering of hateful speech is not linked to the number of tweets posted by Trump..png)
7. Conclusions
We found that moving from a "measuring" hate speech to a "mapping" hate speech method is definitely useful from a semio-linguistic perspective, as it allows to explore in deep the semantic model of our corpus. One of the main output of this work is hence the definition of a workflow. The first thing to do is a repository of the community we are inquiring, platforms and case studies are very variable and dependent on the specific case study. We could use influencers, celebrities, social media pages, subreddits, basically everything that might be relevant in building a reference corpus that is representative of linguistic uses of a specific community. Once we have a reference corpus we explore it with hatebase and we process it with word embedding to visualize the semantic frames. Finally, we go back within our community to investigate online conversation with qualitative analysis. This method might also help to understand phenomena such as deplatforming and also to overcome the technological limits of the post-API era. For what concerns deplatforming, mapping hate speech creates repositories of content that is very likely to be removed and thus lost in social media moderation. On the other hand, the reference corpus allows easily cross-platform research, as we showed in this work. A reference corpus made by alt-right Telegram channels might be used to investigate any alt-right related celebrity and/or page, bypassing API limits on mainstream social media..png) Regarding the qualitative analysis we performed on Twitter, more work is required to understand how much the triggering of hate speech might be considered as directly linked to the use of trigger words.
Regarding the qualitative analysis we performed on Twitter, more work is required to understand how much the triggering of hate speech might be considered as directly linked to the use of trigger words.
8. References
Eco, U. (1979) The Role of the Reader, Bloomington : Indiana UP. Fillmore, C. J. (1976) Frame semantics and the nature of language. Annals of the New York Academy of Sciences, 280(1), 20-32. Harris, Z. S. (1954) Distributional structure. WORD, 10:2-3, 146-162 DOI http://dx.doi.org/10.1080/00437956.1954.11659520 Langton, Rae. "Blocking as counter-speech." New work on speech acts (2018): 144-164. Louw, B. (1993). Irony in the text or insincerity in the writer? — the diagnostic potential of semantic prosodies. In M. Baker, G. Francis & E. Tognini-Bonelli (Eds.), Text and Technology: in honour of John Sinclair (pp. 157–176). Amsterdam: Benjamins. Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013a). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119). Sinclair J. M. (1991). Corpus, Concordance, Collocation. Oxford: Oxford University Press.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback