You are here: Foswiki>Dmi Web>TracingTheTrackers (29 Jun 2012, HugoHuurdeman)Edit Attach
Traces of the Trackers
Tracking the Trackers: A historical analysis using the Internet ArchiveMembers
Anne Helmond, Hugo Huurdeman, Thaer Samar, Nili Steinfeld, Lonneke van der VeldenIntroduction
This research project looks at a specific archived object: tracker fingerprints. We follow up on a claim made by Richard Rogers about web archiving. According to him, the website is the main unit to be archived: “one archives the website over the references contained therein (hyperlinks), the systems that delivered them (engines), the ecology in which they may or may not thrive (the sphere) and the pages or accounts contained therein that keep the user actively grooming his or her online profile and status (the platform)” (Rogers, forthcoming 2012).In this research we look at the ecologies websites may be embedded in beyond traditional hyperlinks, engines, spheres and platforms. What are other natively digital archived objects that we can study, and can we map website ecologies around websites through ‘invisible’ back-end linking?
Research Questions
- To what extent can we map tracking ecologies using the Internet Archive?
- Which methods can be used to map tracking ecologies using the Internet Archive?
Limitations
- Not all types of trackers might be detected using the Internet Archive. For example, widgets are not possible because they are “embedded” into the page (third party content/snippet of code).
- What we can detect are trackers that are “hardwired” into the source code of a website.
- The Internet Archive itself adds code to the page during the archiving process. To what extent does this influence Internet Archive source code research?
- For this project, we make use of the Tracker Tracker tool, that uses a “fingerprint” database to detect the trackers that are present in websites. It is possible that websites used trackers in the past, that cannot be detected with the current fingerprint database.
Methodology
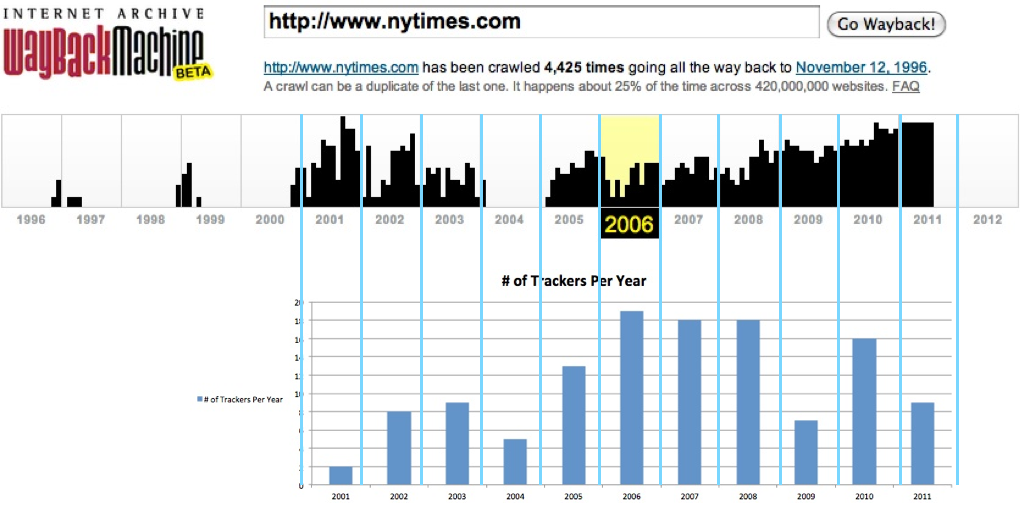
Our research is based on the New-York Times site and aims at describing the evolution of trackers usage in that site. The New-York Times site was chosen due to the site’s centrality as a news source and the large number of users visiting the site per day. Also, the New-York Times site in his current state makes use of a relatively large number of trackers, and it is interesting in that sense to track when different trackers were introduced at the site. Our methodology consisted of the following steps:- Using the Internet Archive’s Wayback Machine and the Link Ripper tool, we created a set of URLs per year for the site
- The study starts at 2001, the year the first tracker appears in the New-York Times site
- We narrowed the URL list to contain one URL per day of every month, if a snapshot exists for that day. In case of multiple snapshots in a day, the first snapshot was used
- We used the Tracker Tracker tool to extract all trackers for a set of URLs, divided by years
- After retrieving the data, results were analyzed to compare the number of trackers used by the site during each year, and the list of trackers names per year
Tools
For our research, we used the following tools and websites:- Internet Archive (New York Times): http://wayback.archive.org/web/*/http://nytimes.com
- DMI Link Ripper: https://tools.digitalmethods.net/beta/linkRipper/
- DMI Tracker Tracker: https://tools.digitalmethods.net/beta/trackerTracker/
Preliminary Findings
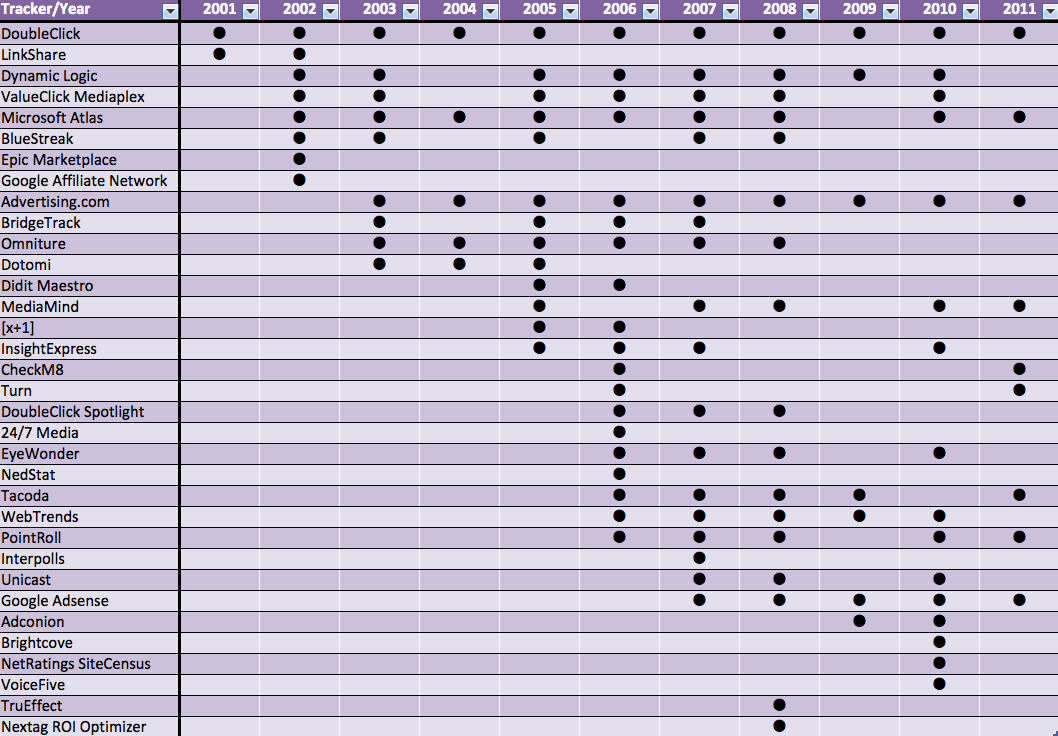
Bar chart:Tracker Matrix:
In the matrix, it can be seen that DoubleClick is omnipresent, and is (together with LinkShare) the first tracker that can be traced using our methodology. It is the only tracker that can be found in all checked years, starting in 2001. A major player in the advertising field, Google, stepped in much later with their "Adsense" platform.
Further research
This project has showed the feasibility of using a specific methodology, that makes use of the Internet Archive and the “Ghostery” tracker fingerprint database to discover traces of trackers from the past. It would be possible to do a more elaborate analysis of the use of trackers on websites from the past using similar methods, and do for instance cross-site comparisons.On a broader scale, it would be possible to look at which types of website ecologies can be mapped using web archives, and the Internet Archive in particular.
It could also be interesting to look at the companies that “own” the trackers, as the data seems to indicate that there is a small decline in the use of different trackers on the New York Times website after 2006.
Old trackers might not be recognized using the existing fingerprint database (that is cumulative, i.e. contains all updates since the Ghostery came into existence). In past times, it is possible that different tracking techniques were used, and other companies were doing the tracking. Therefore it could be valuable to do research into discovering old tracker fingerprints, and to add these to the existing Ghostery database.


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
dmisummer12_tracingtrackers.key.png | manage | 230 K | 29 Jun 2012 - 08:46 | AnneHelmond | |
| |
trackermatrix.png | manage | 92 K | 29 Jun 2012 - 08:45 | AnneHelmond |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r8 < r7 < r6 < r5 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r8 - 29 Jun 2012, HugoHuurdeman
Ideas, requests, problems regarding Foswiki? Send feedback