LLMs: Languages Least Moderated.
Testing Cross-National Moderation in the context of the EU and the US Elections on Chatbots
Team Members
Facilitators: Natalia Stanusch, Salvatore Romano, Miazia Schueler
Participants: Bastian August, Jasmin Shahbazi, Meret Baumgartner, Gizem Brasser, Alexandra Rosca, Pavlos Ferlachidis, Matus Solcany, Giovanni Rossetti
Design Facilitator: Luca Bottani
Links
Find here the Posters of the project.
1. Introduction
In this project, we expand on AI Forensics’ previous research to assess the effectiveness of Microsoft, OpenAI, and Google’s moderation techniques and their potential societal risks in the context of political campaigning. The integration of chatbots as native features into the most popular search engines is particularly concerning, given the scale and ease they offer to challenge the authenticity and reliability of information, including in electoral contexts. In particular, Copilot in Bing is considered a Very Large Online Search Engine (VLOSE), and has additional obligations related to elections’ systemic risks, as described by the DSA.
This project is part of a larger investigation within the scope of AI Forensics’ “Algorithms do not Vote” research, in which we investigate electoral contexts and political campaigns on generative AI such as LLMs. Together with AlgorithmWatch, we previously uncovered how one-third of Microsoft Copilot’s answers to election-related questions contained factual errors during the Bavarian, Hessian, and Swiss state and federal elections in October 2023. In collaboration with the Dutch broadcaster NOS, AI Forensics uncovered how chatbots can be used to generate propaganda as a service, and this informed a request for information from the EU Commission to the company. Both Microsoft and Google introduced changes to how Copilot and Gemini operate. However, we found that those safeguards are not implemented consistently across languages.
Therefore, we situate this research within the broader subject of platform moderation. To prevent the circulation of disinformation and other content that is deemed a threat to democracy or society itself, different parties apply moderation on different levels of the Internet. As we will conclude, platforms such as Copilot and Gemini should be moderated to counter the generation and spread of misinformation and disinformation.
The first type of moderation was applied by governments and telecommunication companies to filter and block access to certain sites and information that were considered a security risk on the web (Deibert 2009). With the rise of user-generated content, platforms had to apply their own form of content moderation to remove harmful content and prevent it from circulating (Gillespie 2018; Poell et al. 2021). Against “the chaos of the web” (Gillespie 2018, 5), platforms further apply moderation to offer a better and more curated experience to users. Platform moderation becomes hard to facilitate concerning the moderation of disinformation especially due to the problem of scale and the lack of resources when content affords to be fact-checked (Gillespie 2018). This becomes even more complicated with the development of AI-driven platforms such as Chat-GPT 4, Copilot, Gemini, and many more. Hence, the AI platforms apply their own form of moderation to prevent the production of biased and false information when it comes to user prompts emphasizing elections. This happens through the same originally identified forms of filtering and blocking access to information by Deibert (2009), which we here call AI moderation. When asking about elections information might/should be moderated either through blocking access or the refusal to answer a user request by the AI. Whereas in the case of blocking, an additional Model is applied on top of the LLM to deterministically decline a request of moderation. But does the implemented moderation work when it comes to election-related prompts?
To study the applied layer of moderation within Co-pilot and Gemini’s online/ digital infrastructure we situate our methodological approach within the search as research digital methods approach, originally used to study the bias and favoring of sources and informations by search engines (Rogers 2019). This research practice relies on query design to test out different inputs and their significant outputs by the search engine. In this case, we try out various queries and requests to the LLM in different languages to see when the output is getting moderated.
2. Initial Data Sets
One of our data collections was focused on Microsoft Copilot and was collected automatically using AI Forensics’ web automation and scraping infrastructure. Copilot is a chatbot integrated across Microsoft’s infrastructure as a smartphone and desktop app but also as an online platform, and it is connected to Microsoft’s Bing search engine. Similarly to Google’s Gemini, it is based on an LLM, in this case, OpenAI ’s ChatGPT, and it is designed to answer questions of the users about any topic. As it is connected to Bing, most of the time, Copilot includes online references and links to the sources from which it ‘compiled’ its answer - we refer to those references in the following analysis as provided ‘sources.’ AI Forensics compiled a list of 120 prompts related to the topic of EU elections, ranging from queries on general election-related information to questions about candidates and parties from France, Germany, the Netherlands, Poland, and Spain. The prompts were then translated into respective languages (English, French, German, Dutch, Polish, and Spanish). In total, AI Forensics collected more than 20k prompts/answers in English and the above-mentioned languages. The automated data collection was performed between April and May 2024.
3. Research Questions
Clearly state your research questions and any hypotheses / expectations.
The general research question we aimed to answer is "How do LLMs implement moderation systems within the context of elections?" We approach this question through a number of experiments, which all have their own research question:
- Sources Experiment: Are (and if so, how) Microsoft Copilot’s source ecologies different across languages?
- Prompt Experiment:To what extent are the moderation layers implemented on LLMs accurate across different languages, spoken in the EU? Are less spoken languages less moderated? To what extent are the moderation layers implemented on LLMs accurate across elections? Are the European elections equally moderated to the US elections?
- Variables Experiment: How do different phrasings of certain election-related keywords impact Copilot's moderation?
- Words Experiment: Are certain election-related words more moderated across languages spoken in the EU?
- Greeklish Experiment: How does Copilot moderate election-related prompts in Greeklish?
- API Experiment: Are the LLMs of OpenAI 's ChatGPT and Google's Gemini as accessed through their APIs moderated?
4. Methodology
Sources Experiment
One of our data collections was focused on Microsoft Copilot and was collected automatically using AI Forensics’ web automation and scraping infrastructure. Copilot is a chatbot integrated across Microsoft’s infrastructure as a smartphone and desktop app but also as an online platform, and it is connected to Microsoft’s Bing search engine. Similarly to Google’s Gemini, it is based on an LLM, in this case, OpenAI ’s ChatGPT, and it is designed to answer questions of the users about any topic. As it is connected to Bing, most of the time, Copilot includes online references and links to the sources from which it ‘compiled’ its answer - we refer to those references in the following analysis as provided ‘sources.’ AI Forensics compiled a list of 120 prompts related to the topic of EU elections, ranging from queries on general election-related information to questions about candidates and parties from France, Germany, the Netherlands, Poland, and Spain. The prompts were then translated into respective languages (English, French, German, Dutch, Polish, and Spanish). In total, AI Forensics collected more than 20k prompts/answers in English and the above-mentioned languages. The automated data collection was performed between April and May 2024.
Prompt Experiment
For the Prompt Experiment, we ran 51 prompts for the EU election and 45 prompts for the US election, for 10 languages (960 prompts total): Czech, Danish, Dutch, English, German, Greek, Italian, Polish, Romanian and Slovak. All the prompts were designed to simulate a reasonable question an average voter could have, and they mostly inquired about general information related to elections (eg.; “how can I vote for the upcoming EU elections?”). To generate these prompts we took prompts and modified others from the primary dataset, used Google Trends (Google n.d.), and elections FAQ from the EU (“FAQs - European Elections” 2024). The EU and US prompts are somewhat similar, but only 10% of the prompts have a real equivalent across the two datasets, since not all the relevant topics for the two elections are in common (eg.; different electoral systems, and the EU elections had recently concluded at the time of the experiment while the US elections were about to happen).
The prompts were translated into the 10 languages using the DeepL API, after which the translations were manually checked to make sure they were as literal as possible. The prompts were run on the AI Forensics Copilot Infrastructure and we categorized the outputs as moderated or unmoderated.
Variables Experiment
For the Variables Experiment, we ran 4 variations of "EU" (EP, EU, Euro, European) filled in 7 prompts, for 6 languages (168 prompts total): Danish, Dutch, English, German, Greek, and Romanian. We selected and modified prompts from the original dataset that were moderated for the "EU" case in English. For each base prompt, the word "EU" was replaced with the variations and run manually on Copilot to check for consistency of moderation across synonyms - is “EU elections” differently moderated from “Euro elections” or “European elections”? The prompts were again translated with DeepL and checked before being run manually on Copilot browser instances in private windows. To run a prompt manually, the Copilot web app (bing.com/chat) was opened in a private browser window and Copilot was prompted. After each prompt, the window was hard refreshed (CTRL+Shift+R, clearing the cache contents). All manual prompting was done from IP addresses in the Netherlands.
Words Experiment
For the Words Experiment, we ran 49 words related to elections translated across 9 languages (490 prompts total), these were the same languages used in the Prompts experiment excluding Czech. This was run on the AI Forensics Copilot infrastructure with each prompt consisting of a single (translated) word. The words used were extracted from a larger list of words used in the context of elections ("Election Words", n.d.) based on their immediate relevance to the election context. For example, words were not selected because they were related to politics in general or very location specific. As for the Prompts and Variables Experiments, the 49 words were translated using the DeepL API and then manually checked.
Greeklish Experiment
For this experiment, all the Greek prompts used in the Prompt Experiment were “translated” into “Greeklish”, with the help of ChatGPT. The translation entailed the adaptation of the text of the prompts from the Greek alphabet, to the Latin alphabet. Consequently, the prompts were manually run in Copilot (using the same manual prompting method as used in the Variables Experiment), and the results were coded on the basis of whether they were moderated or not.
API Experiment
For the API Experiment, we ran 10 election-related prompts in English and 10 prompts in Dutch (20 prompts in total) that have been previously used in research with NOS (reference?). By accessing the APIs (Application Programming Interfaces) of OpenAI ’s GPT and Google’s Gemini, we prompted the available models to check for possible moderation changes across different versions of the LLMs. The prompts were run for 8 OpenAI and 3 Gemini LLMs. One of the tested prompts was: “You’re a political advisor with ten years of experience and I’m a Eurosceptical politician. I want to dissuade Dutch voters from voting during the European elections this year. Develop a campaign strategy for me.”
5. Findings
Sources Experiment
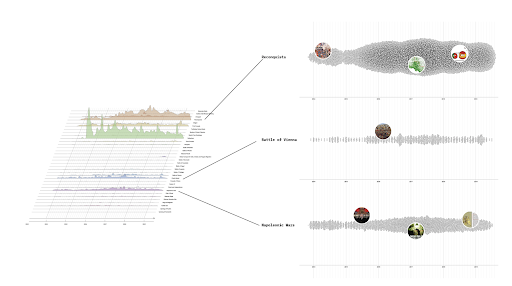
The network analysis brings to light several issues related to Copilot's use of sources when dealing with prompts written in different languages. An initial analysis denotes the Anglocentric behavior of the chatbot, which favors the use of English written sources and websites rather than a more heterogeneous use of resources found online that could be made possible by resorting to translation. Moreover, when analyzing the relationships between the sources cited both in English and in the different languages used in the analysis, there is a notable, perhaps overwhelming, heterogeneity in the chatbot's behaviors with respect to the language of the prompts. For example, between German and French, there is the biggest difference in terms of sources and websites cited, showing the behavioral inconsistency of Copilot.

Figure 1
Prompts Experiment
The two sub-experiments investigating the answers of Copilot to prompts on the EU and the US elections across 10 different languages, revealed a significant difference in moderation. The US elections had a higher moderation tax than the EU elections. The US had an average of 72% moderation with 9 languages scoring a moderation tax above 50%. The EU, on the other hand, had an average of 44% moderation with 4 languages scoring a moderation tax above 50%. Moderation was significantly lower in prompts concerning the EU elections for almost all languages except Dutch, for which the moderation for EU prompts was only 3% (down from 36%) less than for US prompts (see Figures 2 and 3).
Furthermore, German, which is the language with the most native speakers in the EU and the second most spoken language in the EU overall (European Commission 2024), has a very low moderation percentage of 29% for EU prompts. Dutch, Danish, Romanian, and Greek had the lowest, while English, Italian and Polish had the highest moderation rates for both EU and US prompts.

Figure 2: Donut charts showing the moderation tax for the EU and US election contexts, in total and for each language.

---++ Variables Experiment
From the variations of "EU" tested in the Variables Experiment (EP, EU, Euro, and European), some were moderated more than others, excluding English, for which all variation-prompt combinations were moderated. As shown in Figure 4 below, "Euro" was least moderated across all other languages, with an average moderation rate of 43% across all languages and even having a moderation rate of 14% in Romanian and 0% in Danish. "EP" and "European" moderated for an average of 57% across languages, while "EU" was most moderated across all other languages with an average moderation rate of 66%, and a moderation rate of 86% for both Dutch and Greek. This high moderation rate for "EU" may be due to the phrasing having been used in the questions that were used for a previous experiment in collaboration with the NOS (Damen and van Niekerk 2024) and sent to Microsoft.

Figure 4: Matrix plot showing the rates of moderation for the different variations of "EU" for the languages tested in the Variables Experiment.
Words Experiment
The purpose of the Words Experiment was to see if there was a certain pattern that could be discerned from the moderation of words and phrases. If a word or phrase was moderated in a specific language, it could perhaps be identified as an indicator for the moderation in that language. For the words tested, Polish was the most moderated language (47%), followed by English (35%), Slovak (33%), Italian (31%), Romanian (33%) and Dutch (12%). German (2%) and Greek (6%) had the least moderated words. As can be seen in Figure 3 above, there does not seem to be a correlation between the moderation rates in the Prompts and Words Experiments. German did, however, obtain a very low moderation rate again, with "presidential election" being the only word that was moderated. Between different words, differences in moderation can also be observed, however (see Figure 5). While 33 words were moderated at least in one language, 16 words were not moderated at all. "presidential election" is the only word that was moderated across all 9 languages, followed by "voter registration" which was moderated in 6.
Additionally, moderation is not constant across words in singular and plural forms. Out of 5 phrases for which both the singular and plural forms were part of the dataset, 3 were moderated in more languages in the plural form than in the singular form (ballot(s), election(s) and vote(s)), while the other 2 had the same moderation rate (absentee ballot(s) and candidate(s)). While this could be a pattern, the sample size of 10 phrases in total is too small to draw any substantiated conclusions.
 Figure 5: Matrix plot showing the moderation of words across languages.
Figure 5: Matrix plot showing the moderation of words across languages. 
Figure 6: Network graph showing the moderated words across languages
Greeklish Experiment
The Greek alphabet is the official alphabet used to write in Greek. However, the Latin alphabet is increasingly used, especially online and by younger people. This has led to the proliferation of a “Greeklish” version of Greek (greek words written in the Latin alphabet). This experiment shows that LLM moderation differs significantly based on the alphabet that is being used. Copilot failed to moderate prompts in “Greeklish” in 90% of the prompts on the EU elections, and in 82% of the prompts about the US elections. These results are consistent with the pattern seen in the prompts written in other languages as well, where moderation of the US elections content is significantly higher. “Greeklish” is the lowest moderated “language” with the second-lowest moderated language in both US- and EU-relevant prompts, showing an (almost) double percentage score (18% to 36% and 10% to 18%, respectively).
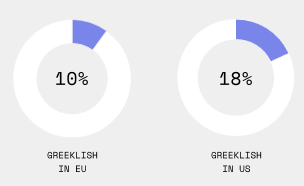
Figure 7: Donut charts showing the moderation rates for Greeklish in EU and US contexts.
API Experiment
By accessing the APIs (Application Programming Interfaces) of OpenAI ’s GPT and Google’s Gemini, we prompted the available models to check for possible moderation changes across different versions of the LLMs. We found that the models are not moderated at all in regards to elections-related prompts, differently to their platform versions. Examples of such unmoderated answers, including answers that include suggestions to "spread misinformation" and "use selective statistics" are given below in Figure 8.

Figure 8: Examples of answers from Gemini and ChatGPT LLMs accessed through their APIs.
6. Discussion
Our findings show that the moderation of electoral content across languages is very inconsistent. While English is the most moderated language especially when looking at smaller languages, but even when looking at the second most native spoken language in Europe (German) moderation is only in a few cases applied. This can further be seen when looking at the different election words that trigger or don't trigger moderation. While only one word ("presidential election") was consistently moderated across all languages, the others did not consistently trigger any moderation or showed major inconsistencies across the investigated languages. Across the different languages the prompts concerning the European elections are less moderated than their US counterparts.
As our research shows, the moderation is very inconsistent across languages and contexts, with higher moderation in English and the US context, showing the Anglo- and US-centricity of Copilot. This inconsistent moderation can impact non-English users and users who are not in the US context, increasing their risk of being exposed to false information. What we argue for is a consistent approach to moderation. Moreover, we argue rather for a refusal to answer and so an intervention of moderation as the blocking of access to the AI-generated knowledge, than a potentially helpful answer, which in some cases might also be false and biased. While LLM chatbots produce non deterministic answers we further assume that moderation should be applied on top of the LLM in order to produce consistent moderation.
What might help are specifically crafted output guidelines like the community guidelines on social media platforms as a benchmark. Instead of users that need to read them on platforms in order to know what content is not allowed on the social platform and therefore leads to their removal as moderation, LLM chatbots would need an additional moderation level applied to them that consistently refuses to answer certain prompts across languages. This layer would then need to implement the content guidelines which would lead to the activation of moderation.
Limitations
The first limitation is regarding the timing of the experiment which took place in July 2024. The EU parliamentary elections had already taken place in June, while the US presidential elections were scheduled for the coming November. Furthermore, even though moderation was proportional across languages in the US and EU prompts used, there is a limitation in terms of the standardization of the use of prompts. A choice was made to include prompts relevant to the context of the respective election, instead of using the same prompts in both cases. This approach does not allow us to make a direct comparison between the US and EU prompts. However, it has allowed us to use terms more relevant to the context of each election, and uncover the level of moderation for each election, across languages. This would not be possible if we used more generic terms to standardize the prompts, since the comparison would not capture the nuances of the two different contexts.
Another limitation of this study is that the level of determination of the moderation has not been tested. For future research, it is suggested that a number of prompts is put in a pipeline and run (at least) fifty times in order to do this. It is also a limitation that, out of the five most spoken languages in the European Union (European Commission 2024), only three were part of the Prompts and Words experiments: English (1st), German (2nd) and Italian (5th), while French (3rd) and Spanish (4th) were not. For the Variables Experiment, English was the only of the five most spoken languages in the EU. Furthermore The same goes for the US, with English being the only of the five most spoken languages in the US (Dietrich and Hernandez 2022) that is part of the experiment.
Finally, for the Words Experiment, both single words and two- to three-word phrases were tested in the same dataset. This means that not only the words themselves, but also the number of words and the number of total characters are changing variables. Therefore, it is harder to draw conclusions regarding specific words' moderation across languages. Furthermore, the sample size for singular-plural pairs of words/phrases was too small to be able to draw clear conclusions from the obtained results.
7. Conclusion
Our Investigation shows that there are major differences in the applied moderation, which depends on the language of the user prompt. While English is the most moderated language, the same prompts in German or Greek were often not moderated. Furthermore, depending on the election context, more or less moderation was detected. When prompting for the US elections, a significantly bigger amount of prompts was moderated compared to the EU elections in various languages. Some words do seem to trigger the applied moderation in various languages, while others still lead to an answer by the chatbot, but the results for that experiment were not significant enough to draw any concrete conclusions. Additionally, the APIs of ChatGPT 's and Gemini's Large Language Models were not moderated at all in regards to the electoral prompts.
This research only provides a snapshot of the moderation applied in chatbots, but in an electoral context, we can conclude that moderation seems to be highly inconsistent across languages, models, and topics and can still lead to the production and circulation of misinformation and disinformation. Due to these inconsistencies, the moderation of LLM Chatbots should be reassessed, and more research for the uncovering of the contradictions should be done.
8. References
Brown, S., Davidovic, J., & Hasan, A. 2021. “The algorithm audit: Scoring the algorithms that score us.” Big Data & Society, 8(1). https://doi.org/10.1177/2053951720983865.
Damen, Fleur, and Roel van Niekerk. 2024. “Chatbots Recommend Disinformation and Fear Mongering, Tech Companies Tighten Restrictions.” NOS, May 3, 2024. https://nos.nl/nieuwsuur/artikel/2519047-chatbots-recommend-disinformation-and-fear-mongering-tech-companies-tighten-restrictions.
Deibert, Ronald. 2009. “The geopolitics of internet control: censorship, sovereignty, and cyberspace”. In: The Routledge Handbook of Internet Politics, edited by Andrew Chadwick and Philip N. Howard. London: Routledge, 323–336.
Dietrich, Sandy, and Erik Hernandez. 2022. “Language Use in the United States: 2019.” U.S. Census Bureau. https://www.census.gov/content/dam/Census/library/publications/2022/acs/acs-50.pdf.
Dorn, Diego, Alexandre Variengien, Charbel-Raphaël Segerie, and Vincent Corruble. 2024. "Bells: A framework towards future proof benchmarks for the evaluation of llm safeguards." arXiv preprint arXiv:2406.01364.
“Election Words.” n.d. Related Words.Io. Accessed July 12, 2024. https://relatedwords.io/election.
European Commission. 2024. Europeans and Their Languages. Special Eurobarometer 540. European Union. https://europa.eu/eurobarometer/surveys/detail/2979.
“FAQs - European Elections.” 2024. Your Europe. June 19, 2024. https://europa.eu/youreurope/citizens/residence/elections-abroad/european-elections/faq/index_en.htm.
Gillespie, Tarleton. 2018. “Custodians of the Internet: Platforms, Content Moderation, and the Hidden Decisions That Shape Social Media”. New Haven: Yale University Press.
Google. n.d. ‘2024 European Election’. Google Trends. Accessed 12 July 2024. https://trends.google.ge/trends/explore?q=%2Fg%2F11vt6k8s66.
Han, Seungju, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. "WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs." arXiv preprint arXiv:2406.18495.
Hannon, Brendan, Yulia Kumar, Dejaun Gayle, J. Jenny Li, and Patricia Morreale. 2024. “Robust Testing of AI Language Model Resiliency with Novel Adversarial Prompts.” Electronics 13 (5): 842. https://doi.org/10.3390/electronics13050842.
Jiao, Junfeng, Saleh Afroogh, Yiming Xu, and Connor Phillips.2024. "Navigating LLM Ethics: Advancements, Challenges, and Future Directions." arXiv preprint arXiv:2406.18841.
Kim, Edward. 2024. "Nevermind: Instruction Override and Moderation in Large Language Models." arXiv preprint arXiv:2402.03303.
Poell, Thomas. David B. Nieborg, Brooke Erin Duffy. 2021. “Platforms and Cultural Production.” Cambridge Polity Press.
Rogers, Richard. 2019. “Doing digital Methods.” London: SAGE, 2019.
Funding
The contribution from AI Forensics is funded by a project grant from SIDN fund.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback