Image Circulation of Russian State-Controlled and Independent Media on Google.com and Yandex.ru
Team Members
Facilitators: Burkhardt, Sarah; Noris, Alice; Olivieri, Alberto Federico; Rogers, Richard; Starita, Giovanni Daniele Team Members: Alireza Hashemzadegan, Davide Perucchini, Eivind Røssaak, Iga Kleszczyńska, Lorena Cano Orón, Luca Draisci, Megan Leal Causton, Miranda GarcíaContents
Summary of key findings
-
The sites of circulation of the analysed images returned by Yandex.com were predominantly connected to the photographs published by State Controlled outlets. The opposite was true for the results given by Google Images.
-
Both sets of images shared as main websites of circulation social networking platforms (VK.ru, OK.ru, Twitter.com, Youtube.com, Reddit.com) and news outlets with an international audience (Sputnik News, Ria Novosti, India Times).
-
Ukrainian sites (.ua) are more present in relation to images published by Independent outlets.
-
Looking at the pictures with higher engagement: Independent outlets depict a more chaotic conflict (e.g.: displacement of civilians), S.C. outlets depict a more static and seemingly organised version of the conflict (e.g.: Putin speaking in public).
1. Introduction
The aim of this project is to gather insights on the similarities and differences between images from the Russian/Ukrainian conflict extracted from Russian State-Controlled (SC) and Independent (I) media outlets (precisely from their VK social media accounts for SC and Instagram social media accounts for I media). This research is a follow-up project on the previous work conducted by Noris et al. (2022) on Image Circulation of Russian State-Controlled and Independent Media on Google.com and Yandex.ru. Moreover, the project looks at the patterns of circulation of these same images on the Russian and Western digital spheres. To analyse and synthetically represent these two digital environments, we used reverse image search functions using our sample on the search engines Yandex.ru and Google.com. This report provides a deeper understanding into the type of imagery deployed in the selected media sources as well as their circulation ecologies on the Internet.
2. Research Questions
The main question underpinning the project is:
-
Which images circulate only (or predominantly) on websites indexed by one search engine but not by the other?
-
Do state-controlled images have a particular network of sources where they are published distinctive to that of Independent Media?
-
Are Google and/or Yandex yielding different images (or sources) of the conflict? If so, to what extent?
3. Methodology and initial datasets
3.1 Data collection
3.1.1 Source image outlet selection
We began our data collection by selecting three Russian State-Controlled media outlets - Argumenty i Fakty, Komsomol’skaya Pravda, Ria Novosti - and three Independent media outlets - BBC Russia, Meduza Pro, Radio Svaboda. We based our selection on the Calvert Journal report (2014) which makes reference to the Russian media landscape. Given that since the start of the conflict the Russian media landscape has been radically transformed (Mac et al., 2022) , we integrated their Media Compass with considerations based on the latest journalistic reports on the topic (Troianovski & Safronova, 2022).
3.1.2 Source image retrieval
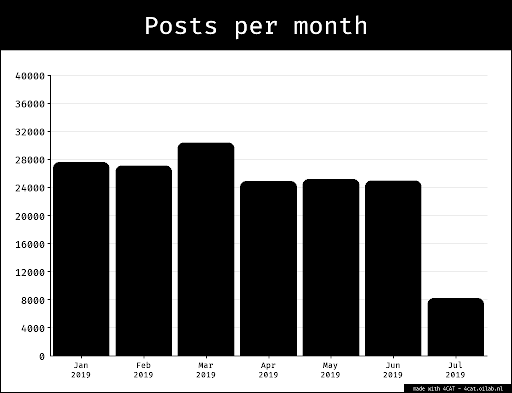
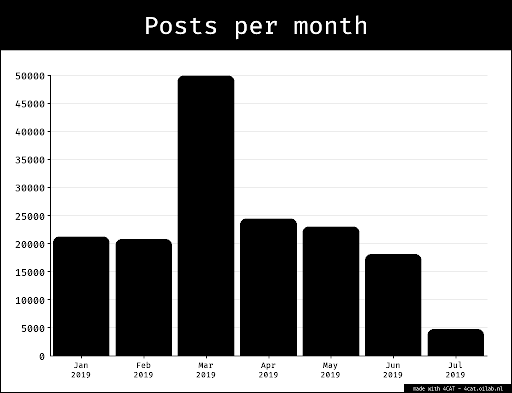
For a period of 40 days, starting from February 24, the first day of the Russian invasion of Ukraine, we scraped the metadata of each post published by the six news outlets, using their VK pages for SC outlets and Instagram accounts for the Independent ones (as they have been banned from VK). For Instagram we used the open-source script Instaloader (instaloader.github.io) to gather the metadata. For VK we used VK Scraper (Olivieri, 2022). Based on this extensive dataset, we selected (up to) three most liked war-related posts for every day, and downloaded them with the VK Scraper (Olivieri, 2022) and Instadown (Starita, 2022). In total, we retrieved 680 images: 366 for Russian state-controlled media outlets on VK, 314 for Russian independent media outlets on Instagram. To maintain an accurate representation of the timeframe we analysed, no additional pictures were selected for those days where we could not find 3 conflict related pictures for each outlet. Taking into account the smallest sample size for the two populations (SC and I) for our data we have a 92% confidence interval with a margin of error of ± 5%.3.1.3 Reverse image search results retrieval
The resulting dataset was then used to perform a reverse image search on Yandex and Google Images, using the Python-based tool Reverse Image Searcher (Burkhardt, 2022) . For Yandex, the search was performed using a VPN localised in Moscow, Russia, and for Google Images, in Amsterdam, The Netherlands. For Google, we additionally opted for English host language settings (hl=en) and Dutch geolocation (gl=nl). The tool is based on the Selenium Chromedriver, which automatised the reverse image search for each of our 680 source images. It simulated the file upload of each image to the search engine, as well as the gathering of all ‘pages that include matching images’ for Google and all ‘sites containing information about the image’ for Yandex. The amount of search results can differ widely, ranging from 0 results up to many hundreds. For each source image, this resulted in two csv files (one for Google, one for Yandex) that stored the search results with the according and slightly differing metadata for Google:
-
rank
-
possible related search query as suggested by Google
-
url
-
domain
-
country code extracted from the domain
-
title meaning the header of the search result
-
description containing all of the information visible for the item
-
text containing only the text that is part of the description
-
thumbnail resolution
-
date being a date of a search result’s publishing estimated by Google
-
thumbnail url,
as well as for Yandex:
-
rank
-
url
-
domain
-
country code extracted from the domain
-
title meaning the header of the search result
-
description containing all of the information visible for the item
-
thumbnail resolution
-
thumbnail url original being the link to the original (high quality) image file
-
thumbnail url.
When the reverse image search databases from Google and Yandex were merged, we deleted the columns containing irrelevant info (e.g. base64 encoding of images) to reduce processing time. Moreover, five columns were added, dividing the information previously contained in a single cell or in the filename of the original excel files. This division allowed us to filter the dataset more accurately. The columns added were: language of the search, search engine, platform the returned image was retrieved from (VK or Instagram), media outlet where we extracted the original image from and the original filename of the image.
3.1.4 Reverse image search thumbnails retrieval
Additionally, we downloaded all of the low resolution thumbnails for each of the 680 source images from the provided URLs from the two csv outputs for Google and Yandex. This way, we were able to gather data about the websites where the source images (and slightly edited versions of them) circulate on the web, as well as about the images that the reverse image search engine mapped to the original image. This allowed us to reconstruct the platform ecologies of the main search engines Yandex and Google used respectively in Russian and in Western contexts. Moreover, it allowed us to take a closer look at the actual content of the images as well as at its ‘derivatives’ that the reverse image search engines suggested to be identical or similar to source images. In the following parts, we are going to elaborate in more detail on the subsequent analysis of the data.3.2 Analysis
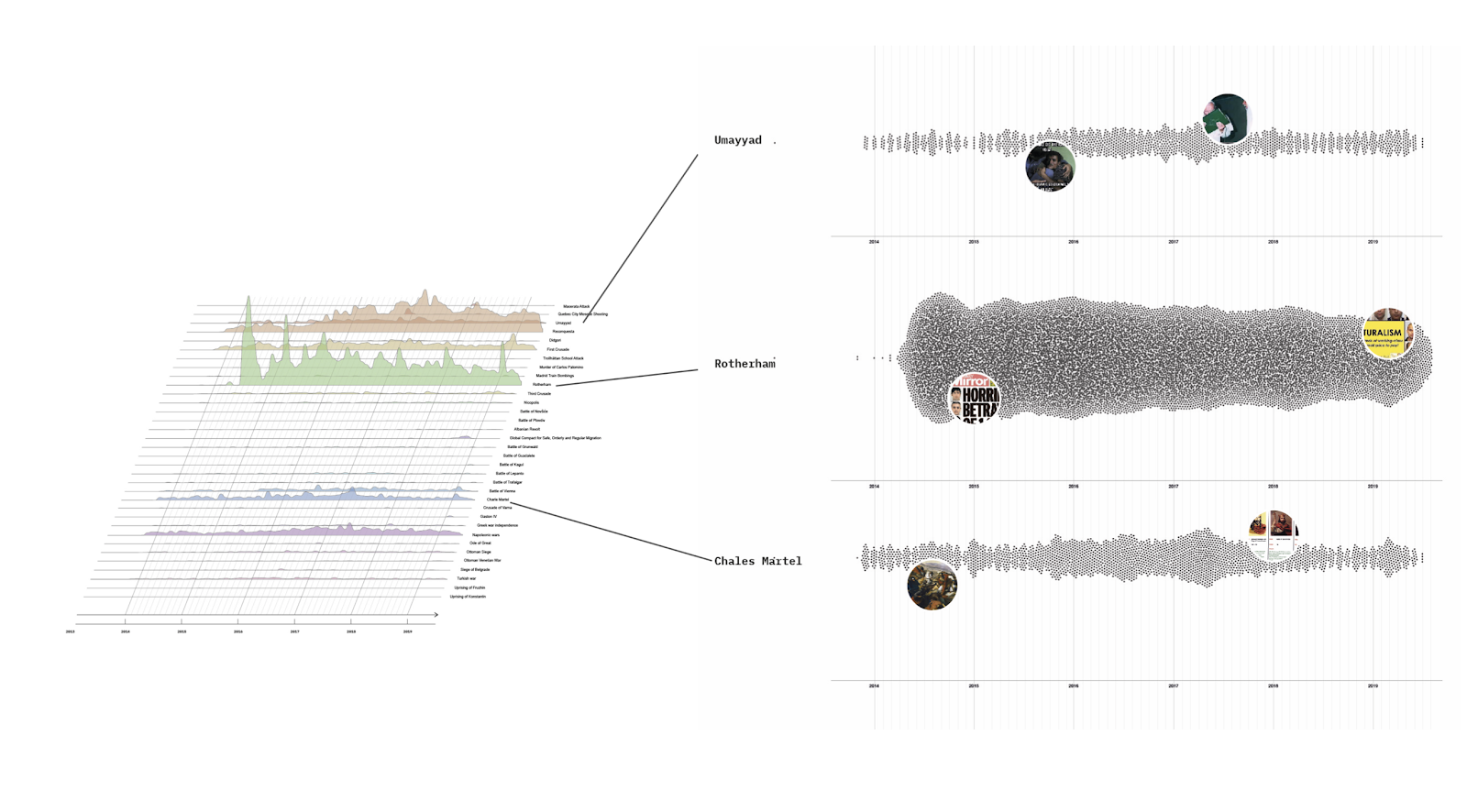
From the downloaded reverse image search thumbnails (3.1.4), the next step was to map them and understand how the images circulate on Yandex and Google in an aesthetic sense. Both Google and Yandex reverse image search depict low-resolution thumbnails for every search result that is associated with the source image. Since the reverse image search deploys computer vision techniques to identify an image in search results on the base of visual features, the thumbnails give a rough idea of how the computer vision algorithm matches images and hence delivers information to users on the base of an image.Since our aim was not primarily to ‘reverse engineer’ or audit Google’s and Yandex’ search results, but to compare the circulation and visual discourses of Russian state-controlled and independent media outlets, we chose to plot an image grid that displays all thumbnails after ranking for each source image, for state-independent outlets and state-controlled outlets, arranged by the date the source image was posted on a media outlet. This way, we ‘metapicture’ (Rogers, 2021) the circulation of source images by keeping the visual content intact whilst rearranged after relevant aspects, such as the ranking position, the date, the media outlet, or search engine. Thereby, it becomes possible to compare the visual deviations and vernaculars that emerge across different media outlets images. But also other readings are possible with such an approach.
For the technical implementation, we relied on the Python matplotlib package to ‘metapicture’ the thumbnails. And, given that we selected the top three images per day per media outlet, which created an image resolution that was too big to plot with the package, we narrowed down the image selection and chose one source image per day. We then plotted each selected source image horizontally, first ordered by the category state-controlled/state-independent, then ordered by specific media outlet, then ordered by date. On the vertical axis, we then plotted the thumbnails by search result rank, whereas the thumbnail close to the bottom is the first in the ranking, and the thumbnail at the top the last one.
4. Findings
We found several differences between the circulation of State Controlled (SC) and Independent media outlets, as well as in the content of these two types of images. The images that were present on Google images search results were predominantly connected to Independent outlets, whereas images from SC outlets were also found to circulate on websites indexed by Yandex.ru. Images from SC outlets predominantly circulated on .ru domains, whilst images from Independent outlets circulated predominantly on .com domains.
We found several striking differences between the visual discourses of Russian state-controlled and independent media with regards to both the sets of images and the sources used to disseminate the images.
4.1 The presence of social networking and news websites
State-controlled images circulate predominantly on websites indexed by Yandex, independent media images circulate predominantly on websites indexed by Google. Both image sets share indexed websites that are predominantly social networking platforms (VK, OK, Twitter, Youtube, Reddit) and journalist outlets (Sputnik News, Ria Novosti, India Times).4.2 Websphere fragmentation - Comparing .RU and .COM
State-controlled media images circulate predominantly on .ru domains, whilst independent media images circulate predominantly on .com domains. However, state-controlled media images have a larger share of .com sources (42%) in comparison to .ru (58%) than independent media images (.com 76%, .ru 24%). Ukrainian sites (.ua) are more dominant for independent media (state-controlled 1.939 vs independent 6.949).4.3 Presence of visual trends
As represented below (Fig. 1), an analysis of the independent media images with the most engagement yields clear visual trends - chaotic, dynamic images that show the lived experience of war in Ukraine (e.g., exodus displacement), or protests against the invasion in Russia. Conversely, the most-liked images from state-controlled media outlets (shown in Fig. 2) show a different picture - static, posed images that convey state power, military might and popular support. These repeat with Russian flags, Putin at political rallies and events and Russian allies (e.g., the Chechen leader Ramzan Kadyrov). An analysis of the computer-generated image labels that differed among the two source sets confirmed these patterns.
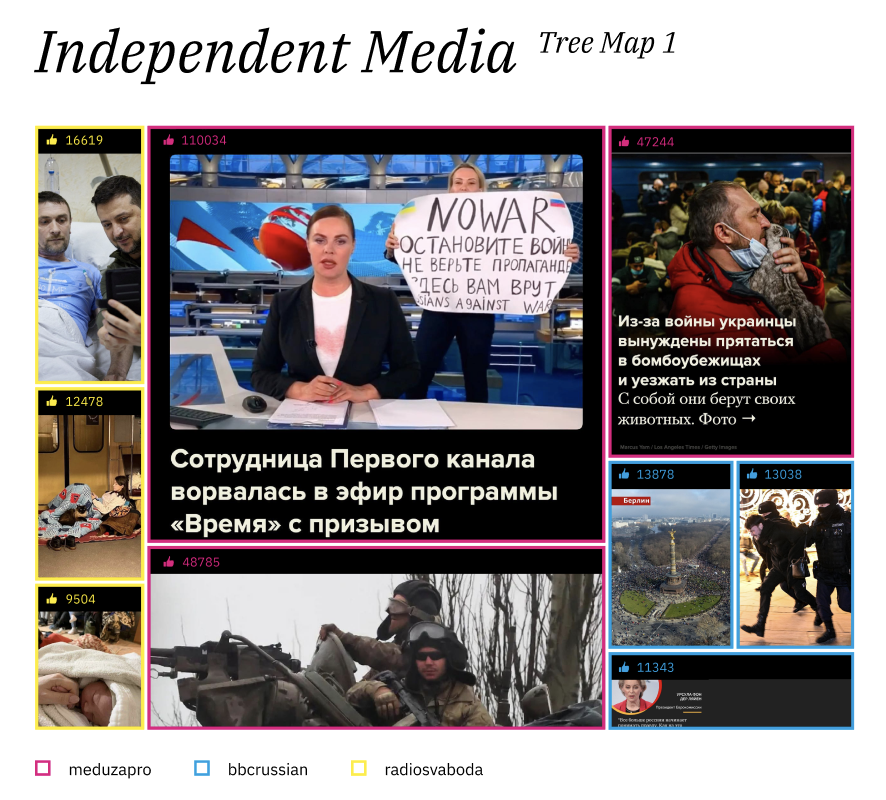
 Fig. 2
Fig. 2
4.4 Image representation performed by state-controlled and independent media
As one can notice from the two treemaps presented above (Fig. 1 & Fig. 2) which depict the most liked images divided per state-controlled and independent media, the two groups of media represent different media ecologies. The images referring to Independent Media (Fig. 1) present the conflict showing the battle on the field, protests and people’s living conditions (e.g. refugees, children and wounded) whereas Fig. 2, which represents the state-controlled media, depicts the conflict mainly showing the power of Russia and images of leaders (e.g. Putin and the Chechen leader Kadyrov).
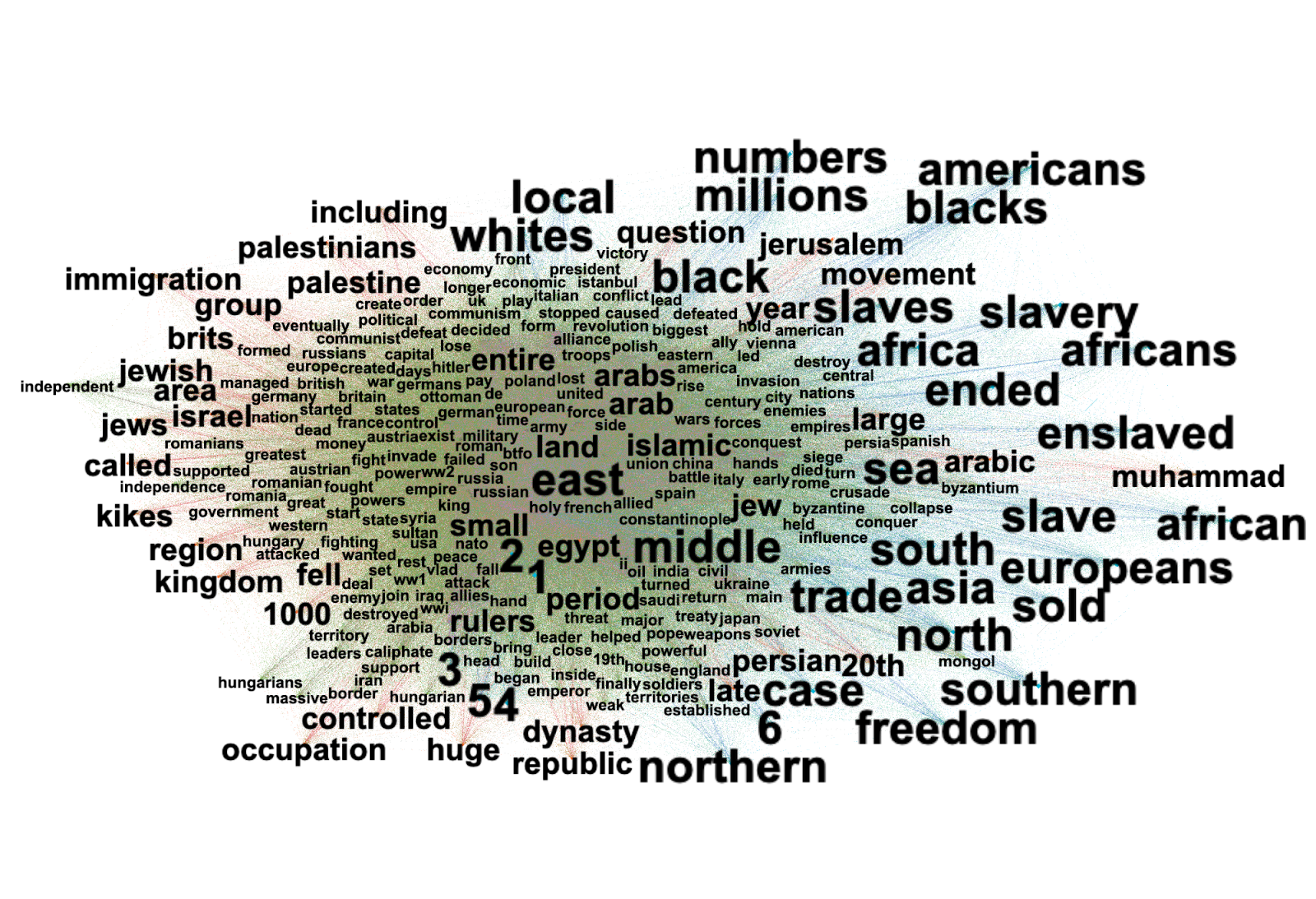
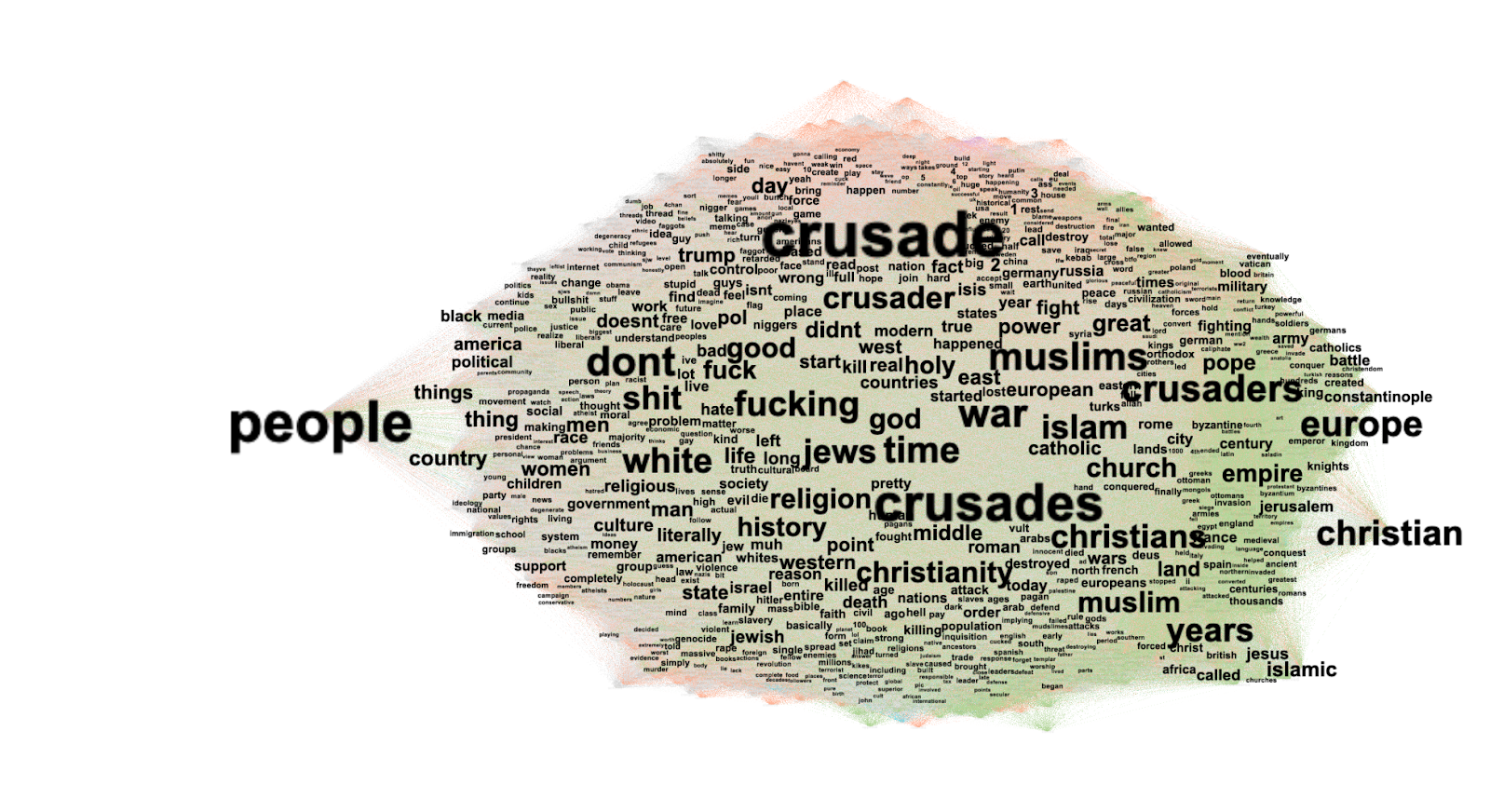
The Treemap representation has also been confirmed by the results of the two word clouds retrieved from Google Vision API (Fig. 3 & Fig. 4). State-controlled and independent media, in fact, seem to propose once again a different representation of the Russian/Ukrainian conflict. Fig. 3, which represents independent media, utilises a lexicon which depicts the living conditions during the conflict (e.g. women, city, street, architecture, travel, etc.) and feelings (e.g. danger) whereas Fig. 4 referred to state-controlled media utilises a wording mainly referred to military power and to war lexicon (e.g. military, weapons, gun, vehicle, soldiers uniform, etc.)
4.5 Google Vision API web entities
The word clouds (Fig. 3 & Fig. 4) represent the unique web entity keywords used by the Google Vision API to identify the content, respectively for independent and state-controlled Media. That is, only words that were not shared by both sets of images are represented. While for the set of images related to Independent media the words describing them are related to the danger of war and the civilians involved; the words representing state-controlled media content are mainly linked to a military lexicon.

Fig. 3

Fig. 4
4.6 Image Circulation Based on Website Domains
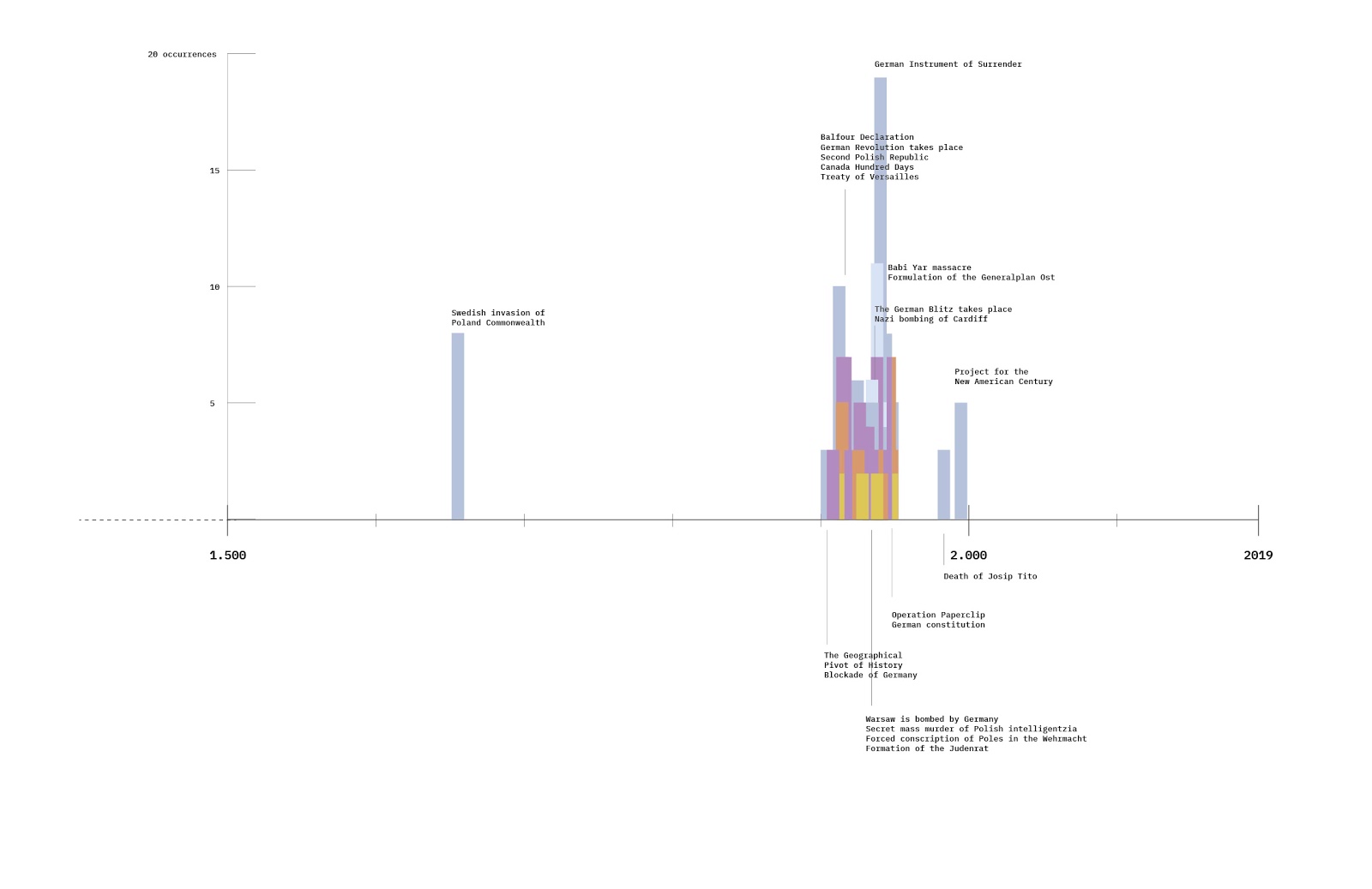
All 66,249 images gathered can be categorised into 244 groups based on the domains of the websites. Generally speaking, website domains include both country-code top-level domains (such as .ru and .ua, respectively for Russia and Ukraine) and top-level domains (such as .com and .net, which may be used internationally). Our findings indicate that the images have circulated through .com domains (with 35.51%) more than any other domain. Then, .ru domains contain nearly 13.40% of all results. And in third place, it is .ua domains with 4.52%.
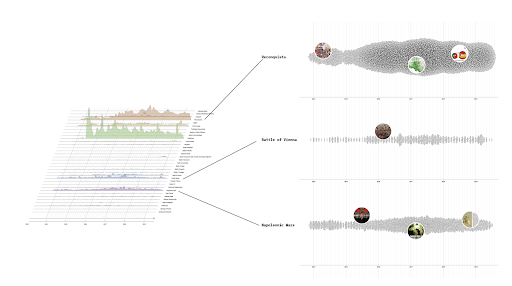
The network graph (Fig. 5) presents how independent media and state-controlled media images circulate on the Internet through Google and Yandex. The graph shows how independent media images circulate more on Google.com, while for state-controlled media images circulate more on Yandex.ru, confirming our initial hypothesis.
As for domains found by both Google and Yandex to be highlighted are ria.ru, vk.com, livejournal.com, smi2.ru, youtube.com, sputniknews.ru.
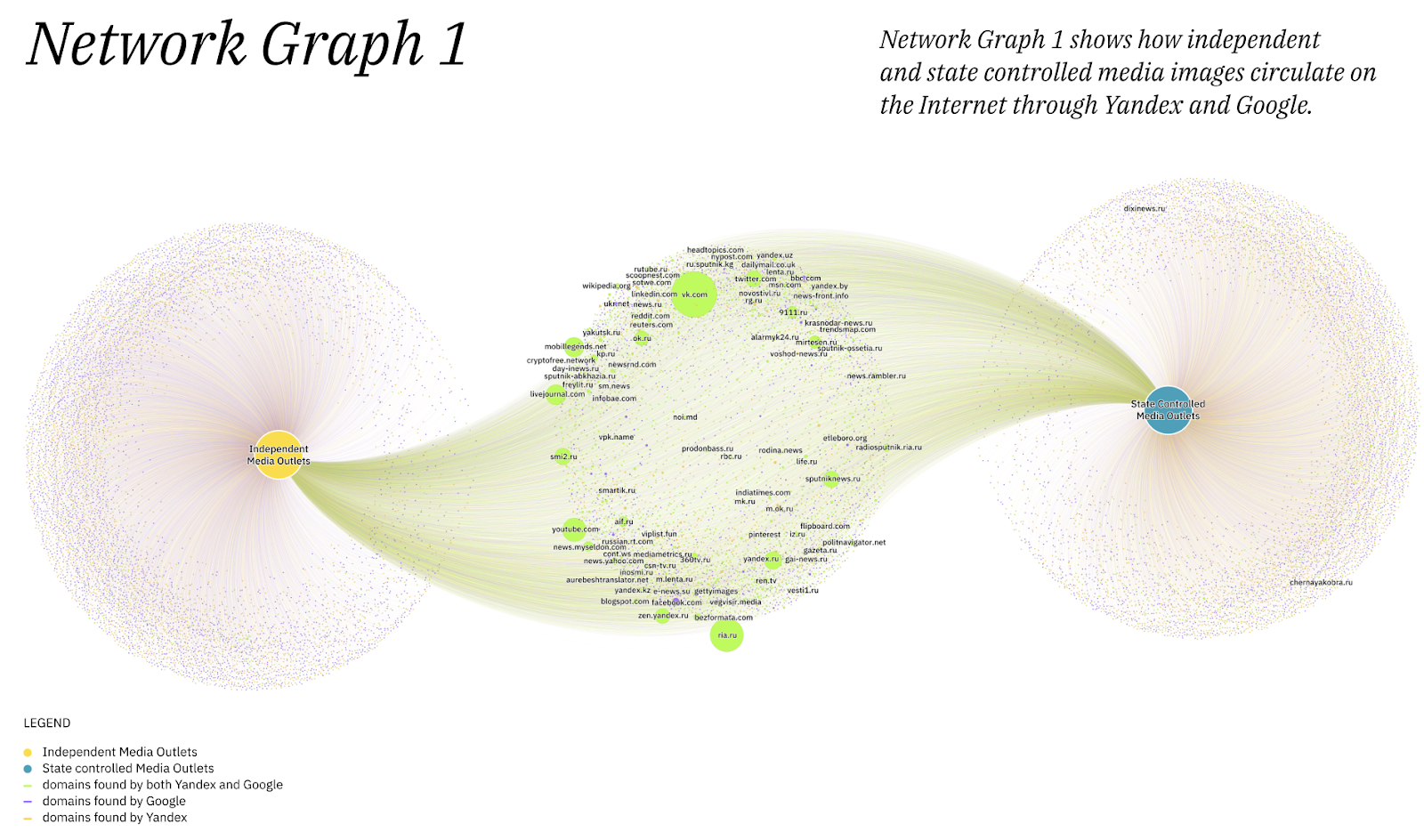
Fig. 5
In the second network graph (Fig. 6), we represented the domains returned by Google and Yandex as websites where the sampled images were present. The two platforms mostly returned different results on the websites of circulation of the images. Nonetheless, the domains shared by the two platforms are those occurring more frequently in the reverse image searches. Nonetheless, the websites present on both Google Images and Yandex Images are the most popular ones (social media and news outlets) and have been consistently present in the reverse image searches.

Fig. 6
The sankeys (Fig. 7 & Fig. 8) present how images obtained from Instagram accounts for independent media and VK accounts for state-controlled media circulate online. In particular, Fig. 7 shows how the domain where images circulate most is .com, followed by others domains and .ru. If we look specifically at which channels the images circulate most on, we find platforms such as Youtube (.com), Twitter (.com), vk.ru, ria.ru, Yandex.ru, etc.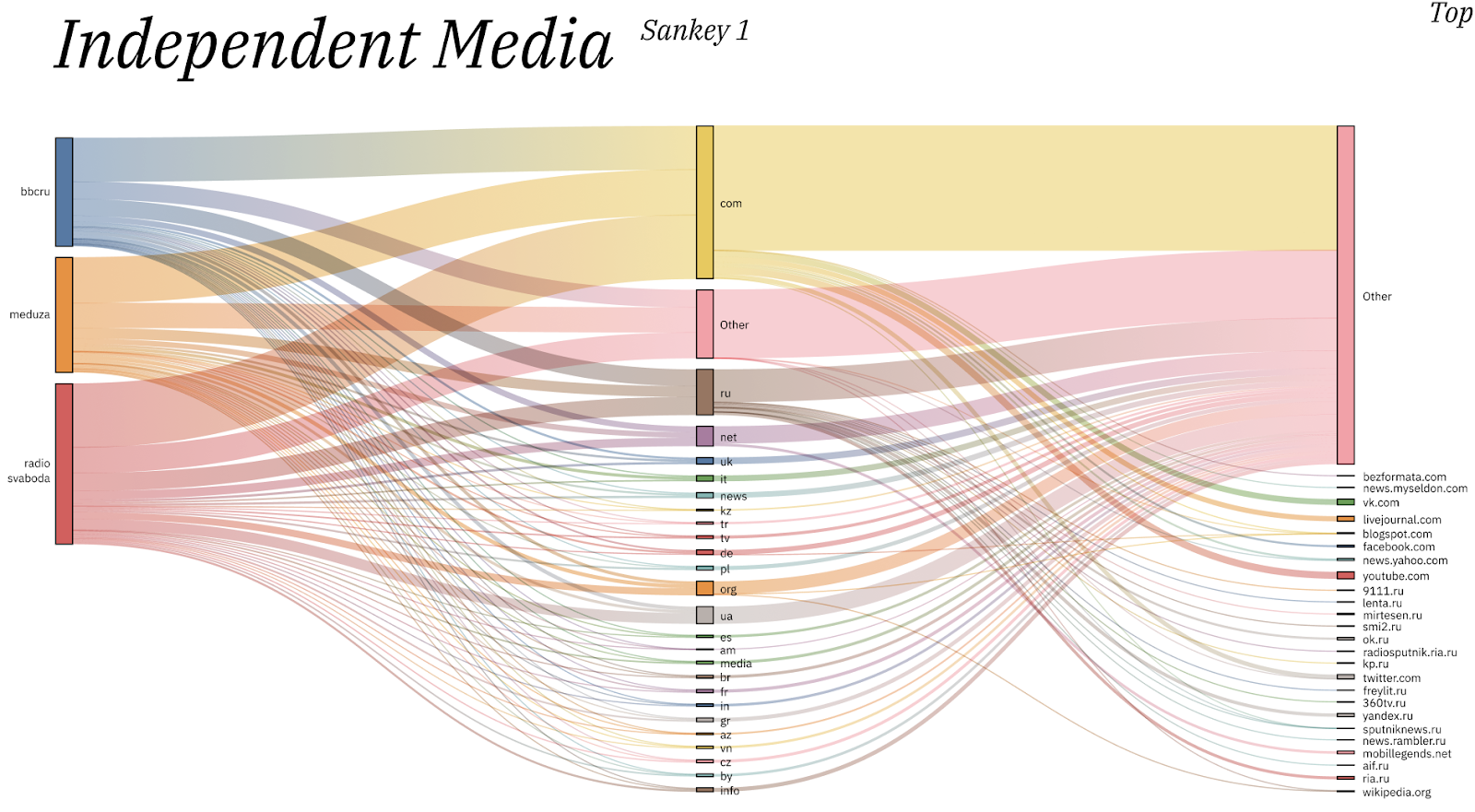
Fig. 7
The other sankey (Fig. 8) presents the situation of state-controlled media. In this case the most recurrent domain is .ru, followed by .com. As for channels, in this case, images seem to circulate predominantly on .ru domains and specifically the most frequent websites are: vk.com, ria.ru, radiosputnik.ru, Yandex.ru and smi2.ru.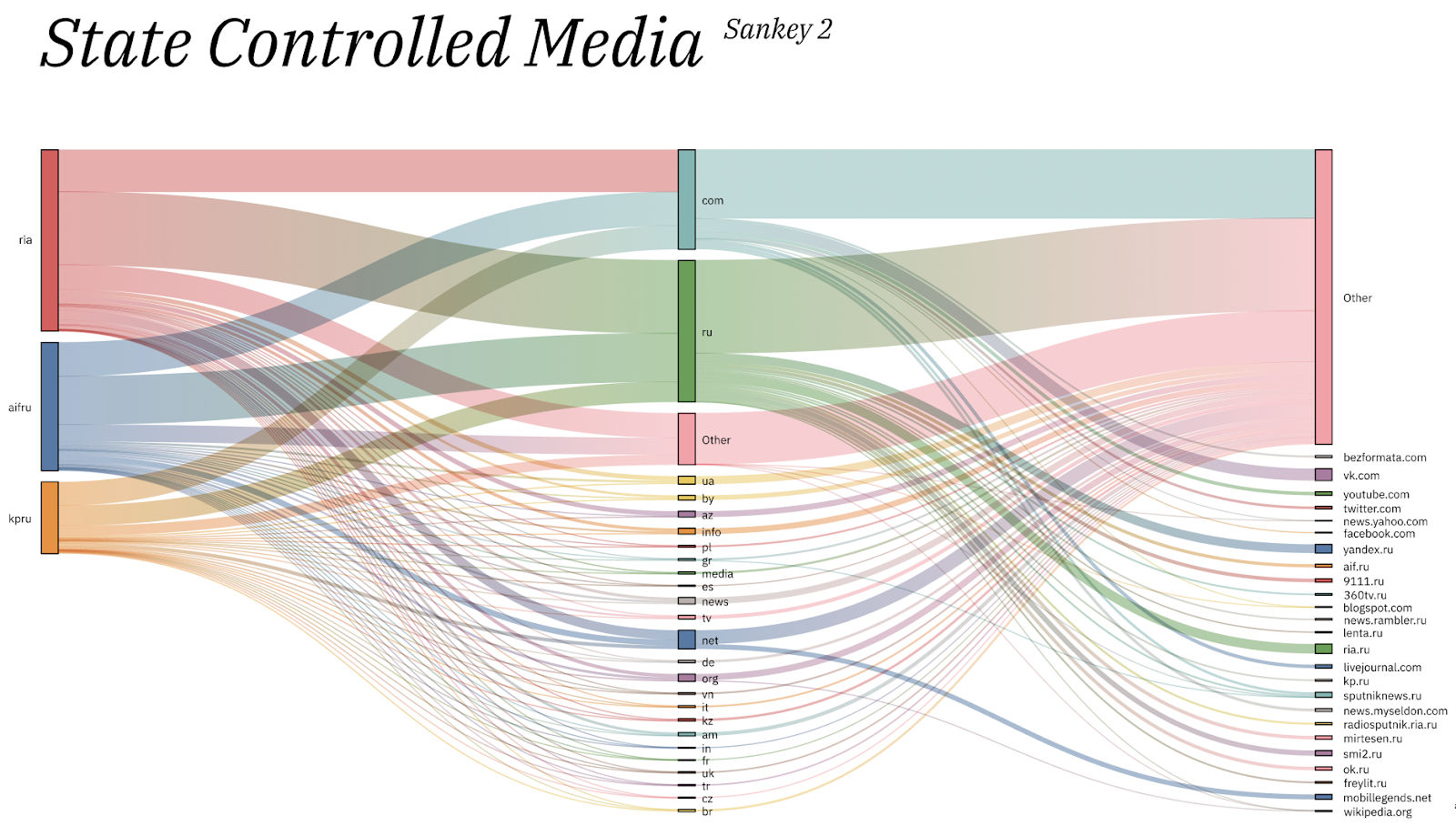
Fig. 8
5. Discussion & Limitations
As we developed the project and implemented digital tools to discover and represent insights on the sampled images, we found a number of elements that could provide further insights:
-
The number of media outlets could be expanded further;
-
The total number of sampled images could be increased, and additional criteria to the one used in this research (likes) could be used to gather insights on more specific visual discourses (e.g.: focusing on images of open conflict or of civilians fleeing the war zone);
-
Future studies could add results from Google.com reverse image searches performed with a VPN located in Russia, and a VPN located in the Netherlands could be used to look at circulation patterns according to Yandex.com reverse image search. This may help researchers identify biases in the search engines that may not be represented in this report;
-
Future studies could perform an in-depth qualitative analysis, using OSINT techniques to study the visually coded messages in the sampled images in a more detailed manner.
6. Conclusions
In general, it seems that independent and state-controlled media provide a different representation of the Russian/Ukrainian conflict. Independent media represent the invasion of Ukraine by showing actual images from the conflict areas, focusing on its impact on civilians’ lives and on the aftermath of bombings of urban areas. Differently, state-controlled media represent the war by showing images connected with the conflict only conceptually, or showing moments from the conflict areas that are not necessarily related to the more violent aspects of war. This translates in images of Putin giving speeches and attending public rallies in support of the invasion, photographs of soldiers taken in moments of relative tranquillity (e.g.: during troop movements far from the front).
Looking at the digital platforms our research relied on, Yandex and Google seem to have different media ecologies although some media outlets are commonly shared. Overall, Yandex.ru gave us way less websites of circulation of the sampled images compared to Google Images. However, Yandex.ru returns in many cases completely different results. In other words, it seems that Yandex and Google Images index two largely separated webspheres, probably due to the Kremlin's efforts to control the circulation of information within the country (Duffy, 2015), that were accelerated after the invasion of Ukraine (Satariano, 2022).Furthermore, this project outlines the key methodological steps that open up for the use of reverse image search as a method of studying social phenomena in a broader perspective. As much as this project did not go in-depth in any of its parts, it paves the way for a plethora of potential future research endeavours.
7. References
Burkhardt, Sarah (2022). Reverse Image Searcher. Available at: http://github.com/sarahtartaruga/reverse-image-searcher
Calvert Journal (2014). Retrieved from: https://www.calvertjournal.com/features/show/2228/russian-media-guide-to-the-troubled-world-of-independent-journalis
Duffy, N. (2015). Internet freedom in Vladimir Putin’s Russia: The noose tightens (p. 12) [Research Report]. American Enterprise Institute. Available at: https://www.jstor.org/stable/resrep03199
Graf, Alexander (2022). Instaloader. Available at: https://github.com/instaloader/instaloader
Mac, R., Isaac, M., & Frenkel, S. (2022). How War in Ukraine Roiled Facebook and Instagram. N.Y. Times. Retrieved from https://www.nytimes.com/2022/03/30/technology/ukraine-russia-facebook-instagram.html
Noris, A., Olivieri, A. F., Starita, G. D., Rogers, R. (2022). Image Circulation of Russian State-Controlled and Independent Media on Google.com and Yandex.ru. Digital Methods Initiative. Retrieved from https://wiki.digitalmethods.net/Dmi/GoogleYandexImageCirculation
Olivieri, Alberto Federico (2022). VK Scraper. Available at: http://github.com/afolivieri/vk_scraper
Rogers, R. (2021). Visual media analysis for Instagram and other online platforms. Big Data & Society, 8(1), 20539517211022370.
Satariano, A. (2022, February 26). Russia Intensifies Censorship Campaign, Pressuring Tech Giants. The New York Times. Retrieved from: https://www.nytimes.com/2022/02/26/technology/russia-censorship-tech.html
Starita, Giovanni Daniele (2022). Instadown. Available at: https://github.com/giovsta/InstaDown
Troianovski, A., & Safronova, V. (2022). Last Vestiges of Russia’s Free Press Fall Under Kremlin Pressure. N.Y. Times. Retrieved from https://www.nytimes.com/2022/03/03/world/europe/russia-ukraine-propaganda-censorship.html
8. Appendix
Under these links you can find the posted visualisations in high resolution:
Fig. 1: Tree Map 1 - Independent Media
Fig. 2: Tree Map 2 - State Controlled Media
Fig. 5: Network Graph 1
Fig. 6: Network Graph 2
Fig. 7: Sankey 1 - Independent Media
Fig. 8: Sankey 2 - State Controlled Media


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback