Automated connectivity: Moving beyond bots
Team Members
Esther Weltevrede, Anne Helmond, Carolin Gerlitz, Laurie Waller, Matteo Menapace, Alex Piacentini, Tiago Salgado, Chiara Riente, Ana Pop Stefanija, and Simy Kaur GahooniaIntroduction
In this project we wish to inquire into the role of automated software, tools and scripts in the production, circulation and emphasizing of issues. Tools for automation of content production play central and distinct roles in social media platforms such as Twitter and websites such as Wikipedia. On Wikipedia for example, bots facilitate creating connections between articles, importing content from external databases, and fighting spam. Bots and tool-assisted human editors collaborate in the production and maintenance of Wikipedia content (Niederer and Van Dijck 2010; Geiger 2013). On Twitter, users can draw on a variety of third party services that allow for automation of different degree, from scheduling posts facilitated by Buffer or Hootsuite, automated cross-syndication from other platforms, to scripts for automatic retweets of content containing a particular hashtag (Gerlitz and Rieder 2016), to name only a few. These forms of automation are not only used by spammers, who monitor and hijack #hashtags for their own gain, but also by marketeers and NGOs who wish to highlight and distribute their products or issues, and by everyday users who mix manual and software supported tweeting. These automated practices as enabled by software tools are often discussed in binary terms, where users can either be a bot or a human. However, as the above examples demonstrate, there are different types of automation software and various degrees of automated activity. Therefore we wish to develop a more nuanced vocabulary for understanding and discussing automation practices by moving beyond the bot versus human distinction. Furthermore, we are interested in developing novel methods for accounting for automation practices, and in particular ‘automated connectivity,’ understood as the engineering of connections (Van Dijck 2013: 12) to enable researchers to account for automation in their datasets. We approach these objectives by mapping out automation dynamics in different issue based data sets in order to ask how automation may inform and shape issue dynamics.Research Questions
- How can we detect automated practices within an issue space?
- How do automation practices differ per platform (source) and per issue?
- How do automation tools create different issue dynamics?
- What does the composition of automatisation tell us about the issue space?
Methodology
As a starting point we wish to inquire into the role and dynamics of automation within a number of issues on Twitter. We wish to investigate how different automated software inform Twitter data sets to examine whether there tendencies in data sets that are driven by (automated) sources. We approach this question via Twitter because the platform itself does not force you to declare user types like Facebook (Page, Profile, Community) and leaves user practices fairly open. Since issues already have particular dynamics, we have chosen four distinct issues: political/current [brexit], lifestyle [detox], technology/sustainability [smartcities], techno-social [drones]. All tweets have been collected and analyzed via The Digital Methods Initiative Twitter Capture and Analysis Toolset ( DMI-TCAT). Number of tweets in the Twitter data sets: [brexit] 3.238.112 [detox] 525.601 [smartcities] 62.281 [drones] 6.501.056Timeframe: 1 Jan 2016 - 29 June 2016 (except for [brexit] 24-29 Jun 2016) in order to study sources not time and to better account for discontinued automation sources. We are approaching issues via their sources (and not via users). Sources are where tweets are sent from, e.g. official channels Twitter Web, Twitter for Iphone, but also third party clients which have often been developed for use case scenarios not offered by Twitter itself like Hootsuite for marketing, or which have been developed by a user for a single purpose/user like @Ivotestay. Sources receive their names when they are registered via the API. Previous research (Gerlitz & Rieder 2016) showed sources are a good indicator for automated activity. From our data sets we selected 2 issue specific sources and 2 shared sources across the issues for further profiling and analysis. We chose the specific ones to analyse the issue specificity of sources and the shared ones to analyse whether they have different profiles per issue Sources to profile across all issues
- Dlvr.it
- IFTTT
- Brexit: RoundTeam + iVoteStay & iVoteLeave
- Drones: Twuffer, Drone Haowai
- Smart Cities: sprinklr, voicestorm
- Detox: meet edgar, awe.sm
Comparative source profiling of source per issue
-
Source ID card: Collect the following info for your 2 unique sources:
-
Logo (if there is one)
-
Type
-
Bio (short description from the About page)
-
Website URL
-
Is the source still active on Twitter?
-
-
Activity patterns: Per Issue collect the following info in a spreadsheet, one Source per row:
-
Using TCAT Tweet stats overall: Percentage of tweets with links, retweet, hashtag, reply….
-
Top 10 hashtags
Top 10 hashtags for the issue overall + amount
For each source, get top 10 hashtags + amount -
Top 10 URLs
Top 10 URLs for the issue overall + amount
For each source, get top 10 URLs + amount -
User profiling: Filter by source in TCAT and collect:
Top 10 most active users (‘Tweets in data set’: Sort from high to low)
How much are the top 10 most active mentioned (check if they’re self mentions)
Use: TCAT: User Stats individual
Findings

Figure 1: The source specificity of issues. Shared sources displayed in the center, specific sources displayed in the periphery. Edge weight is no of tweets.
Figure 1 shows that issues have quite some specific automation tools, some are connected to the issue (e.g. Ivotestay in [brexis], dronehaowai in [drones]), but most often not. Sources can say something about the issue space in terms of diversity and type (e.g. tons of ‘win’ automation tools in detox). The shared sources are more manual or semi-automated sources and multipurpose. Figure 2: The selected 2 issue specific sources and 2 shared sources across the issues for further profiling and analysis.
The first step in further profiling the sources is by creating ID cards with information provided by the sources themselves. This also provides us with a first descriptor of the type of automation we’re dealing with: e.g. content syndication, automator, scheduler, etc.
Figure 2: The selected 2 issue specific sources and 2 shared sources across the issues for further profiling and analysis.
The first step in further profiling the sources is by creating ID cards with information provided by the sources themselves. This also provides us with a first descriptor of the type of automation we’re dealing with: e.g. content syndication, automator, scheduler, etc.
 Figure 3: ID cards for the shared sources
Figure 3: ID cards for the shared sources



 Figure 3: ID cards for the unique sources
Figure 3: ID cards for the unique sources
In the following steps we are further qualifying these types of automation by looking at their behavior and issue commitment. We approached profiling the behavior of sources by looking at medium-specific activities present in tweets sent from these sources and visualized the activities as heatmaps.
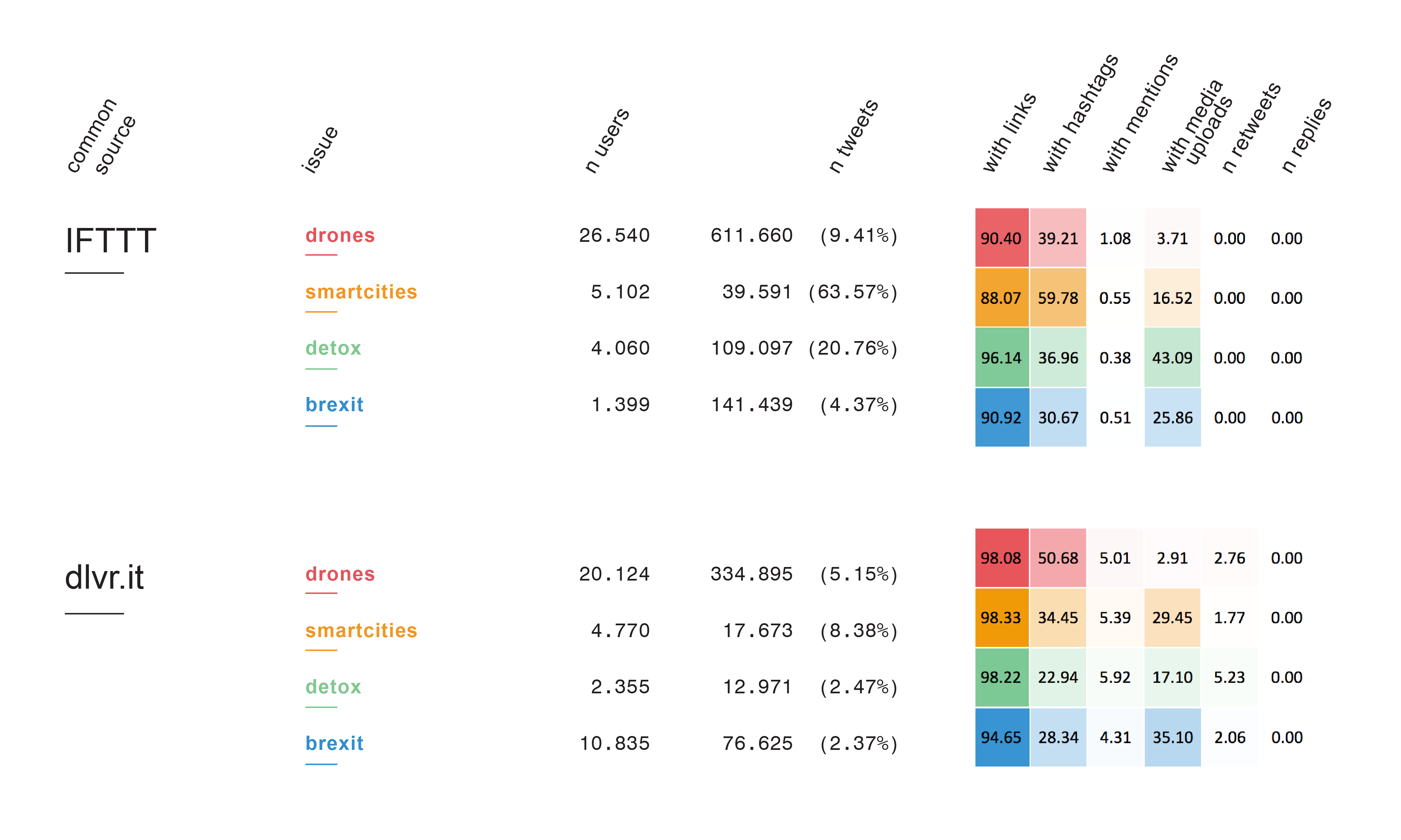 Figure 4: Heatmap of shared sources
The first overview (Figure 4) shows how the shared sources IFTTT and Dlvr.it have similar or diverging activity patterns across the spaces. The results show similarities in terms of links and hashtags and we’ve seen indications of hashtag hijacking.
Figure 4: Heatmap of shared sources
The first overview (Figure 4) shows how the shared sources IFTTT and Dlvr.it have similar or diverging activity patterns across the spaces. The results show similarities in terms of links and hashtags and we’ve seen indications of hashtag hijacking.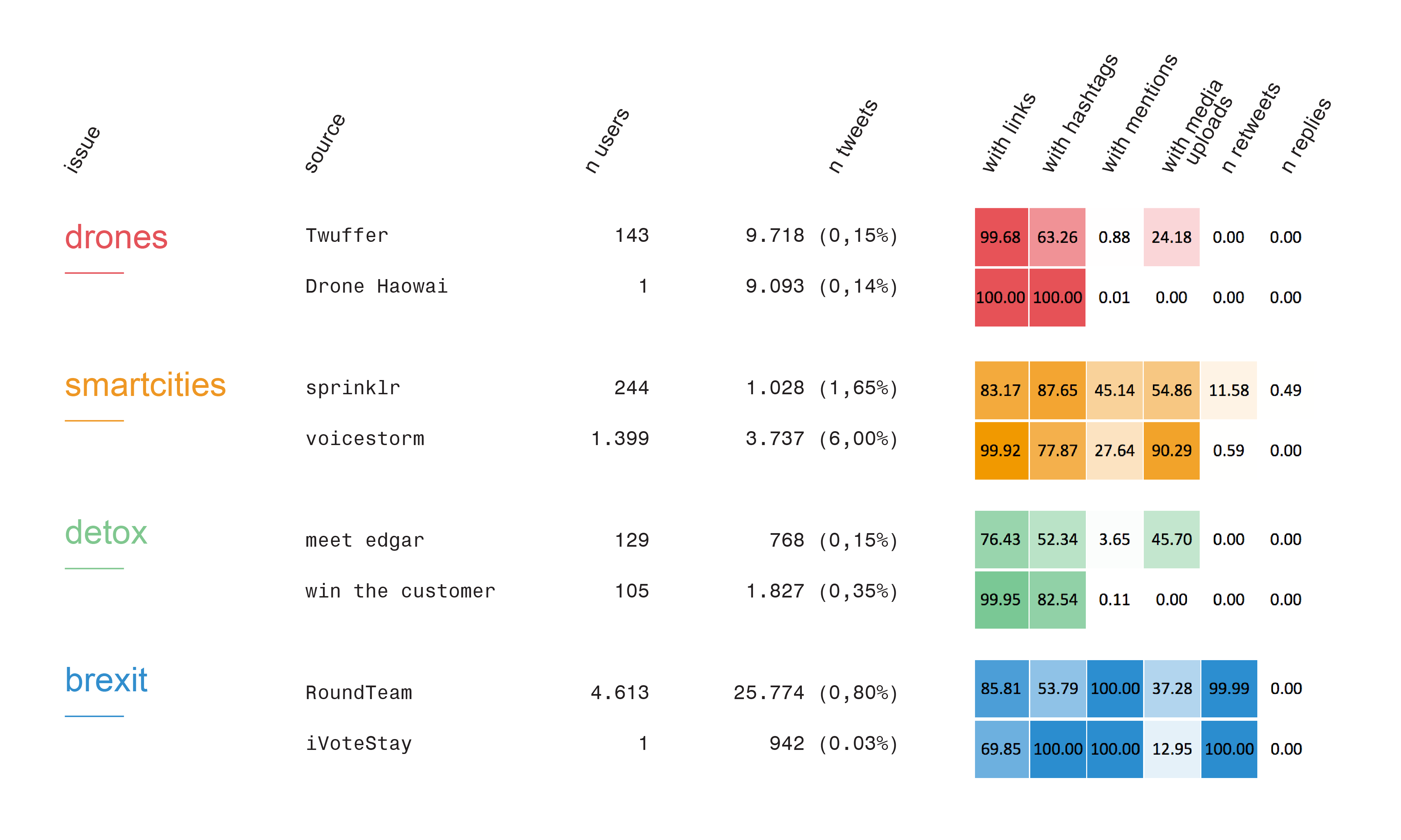 Figure 5: Heatmap of specific sources
Figure 5 shows the activity patterns of the issue specific sources. The results show that the automation practices suggest that tools are rudimentary, or used rudimentarily. For example automation scripts/services are being used to: systematically retweet everything that contains a certain hashtag, broadcast content with predictable syntaxes (eg: “check out” + URL + hashtag) , hashspamming trending topics. There seems to be little in the way of engagement, as in engaging in meaningful / sustained conversations with other Twitter users. Augmented content creation and distribution: most accounts using the analysed sources seem to be not 100% automated, but they use a varying degree of automation to occupy the issue space. Given their rudimentary practices it’s more about “marking the territory” than engaging in conversations and about broadcasting products or messages.
In the final step we looked at the extent to which sources are committed to issues. We did this by analysing the hashtag distribution per source and comparing that against the overall top 10 most prominent hashtags per issue space
Figure 5: Heatmap of specific sources
Figure 5 shows the activity patterns of the issue specific sources. The results show that the automation practices suggest that tools are rudimentary, or used rudimentarily. For example automation scripts/services are being used to: systematically retweet everything that contains a certain hashtag, broadcast content with predictable syntaxes (eg: “check out” + URL + hashtag) , hashspamming trending topics. There seems to be little in the way of engagement, as in engaging in meaningful / sustained conversations with other Twitter users. Augmented content creation and distribution: most accounts using the analysed sources seem to be not 100% automated, but they use a varying degree of automation to occupy the issue space. Given their rudimentary practices it’s more about “marking the territory” than engaging in conversations and about broadcasting products or messages.
In the final step we looked at the extent to which sources are committed to issues. We did this by analysing the hashtag distribution per source and comparing that against the overall top 10 most prominent hashtags per issue space
 Figure 6: Top 10 hashtags per source for the issue [smartcities]
The results show for the shared sources that IFTTT: a lot of key hashtags are driven by IFTTT. IFTTT is e.g. driving the Indian smart city agenda if we look at the size of the hashtag Faridabad (city in India; India has a smart city agenda). For the specific sources it shows that Voicestorm is driving marketing hashtags: TeamEricsson, Socialinnovtion, NeverBetter.
Figure 6: Top 10 hashtags per source for the issue [smartcities]
The results show for the shared sources that IFTTT: a lot of key hashtags are driven by IFTTT. IFTTT is e.g. driving the Indian smart city agenda if we look at the size of the hashtag Faridabad (city in India; India has a smart city agenda). For the specific sources it shows that Voicestorm is driving marketing hashtags: TeamEricsson, Socialinnovtion, NeverBetter.

 Figure 7: Top 10 hashtags per source for the issues [drones] and [detox]
Figure 7: Top 10 hashtags per source for the issues [drones] and [detox]
 Figure 8: Top 10 hashtags per source for the issue [brexit]
Figure 8 suggests that [brexit] is NOT mainly driven by automated sources. The specific source Ivotestay displays hashtags about the voting process and results.
Figure 8: Top 10 hashtags per source for the issue [brexit]
Figure 8 suggests that [brexit] is NOT mainly driven by automated sources. The specific source Ivotestay displays hashtags about the voting process and results.
Conclusions
- Source determines activity pattern more than the issue
- Automated activity is often rudimentary
- Type of automation often shows a recognizable activity pattern
- Moving beyond bot-user distinction? Vocabulary suggestions: schedulers, automators, cross-syndicator, content augmenters and content reproducers.
New language question. Why do we need new language? Buying into the words used by marketeers? They often also obfuscate what automated tools do (e.g. Social customer experience management)so Emic attunement is sometimes not enough , because that does not take into account how technology may also be repurposed by users. Here we adopted a more utilitarian language to describe them.
It is also a way of moving beyond user-bot distinction: e.g. Content reproducers not just spammy bots, but can also be seen as pushing issue agenda’s (indian smart city agenda). To move beyond this utilitarian way of describing these practices/tools, future research can dive into the affordances of sources and the variety of uses of them.
Bibliography
Geiger, R. Stuart. 2014. “Bots, Bespoke, Code and the Materiality of Software Platforms.” Information, Communication & Society 17 (3): 342–56. doi:10.1080/1369118X.2013.873069. Gerlitz, Carolin, and Bernhard Rieder. 2013. “Mining One Percent of Twitter: Collections, Baselines, Sampling.” M/C Journal 16 (2). http://www.journal.media-culture.org.au/index.php/mcjournal/article/viewArticle/620. Gerlitz, Carolin, and Bernhard Rieder. 2014. “Tweets Are Not Created Equal. Intersecting Devices in the 1% Sample.” AoIR Conference. Daegu, South Korea. Niederer, Sabine, and José Van Dijck. 2010. “Wisdom of the Crowd or Technicity of Content? Wikipedia as a Sociotechnical System.” New Media & Society 12 (8): 1368–87. doi:10.1177/1461444810365297.Presentation slides
Digital Methods Summer School 2016 presentation slides

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
IDcard-01.jpg | manage | 771 K | 02 Jul 2016 - 14:42 | AnneHelmond | |
| |
IDcard-02.jpg | manage | 583 K | 02 Jul 2016 - 14:42 | AnneHelmond | |
| |
IDcard-03.jpg | manage | 758 K | 02 Jul 2016 - 14:43 | AnneHelmond | |
| |
IDcard-04.jpg | manage | 911 K | 02 Jul 2016 - 14:43 | AnneHelmond | |
| |
IDcard-05.jpg | manage | 648 K | 02 Jul 2016 - 14:43 | AnneHelmond | |
| |
figure2.png | manage | 42 K | 15 Jan 2016 - 12:32 | AnneHelmond | Group of the Italian University websites tracked and the network of the trackers used. |
| |
figure3.png | manage | 73 K | 15 Jan 2016 - 12:33 | AnneHelmond | Bubble chart of the typology of trackers used in Italian University websites |
| |
heatmap-overlap.png | manage | 271 K | 02 Jul 2016 - 15:03 | AnneHelmond | |
| |
heatmap-specific.png | manage | 277 K | 02 Jul 2016 - 15:08 | AnneHelmond | |
| |
slides6-02.png | manage | 964 K | 02 Jul 2016 - 14:40 | AnneHelmond | |
| |
slides_5-01.png | manage | 1 MB | 02 Jul 2016 - 14:24 | AnneHelmond | |
| |
topHashtag-brexit.jpg | manage | 600 K | 02 Jul 2016 - 15:14 | AnneHelmond | |
| |
topHashtag-detox.jpg | manage | 588 K | 02 Jul 2016 - 15:15 | AnneHelmond | |
| |
topHashtag-drones.jpg | manage | 636 K | 02 Jul 2016 - 15:14 | AnneHelmond | |
| |
topHashtag-smartcities.jpg | manage | 715 K | 02 Jul 2016 - 15:14 | AnneHelmond |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback