You are here: Foswiki>Dmi Web>DmiSummerSchool>SummerSchool2010>AdvancedProgramProjects>StartingPoints2 (10 Sep 2010, EstherWeltevrede)Edit Attach
Starting points 2.0
Team members
Erik Borra, Martin Feuz, Marc Tuters, Marijn de Vries-Hoogerwerff, Simeona Petkova, Esther WeltevredeIntroduction
Google CEO Eric Schmidt has admonished Twitter as "the poor man's email". However, recent statistics show that microblogging and social media are taking over Google's role as entry point of the web from search. Search engines like Google value the links that come out of social media differently than links from web 1.0. Links from Twitter, for instance, have a nofollow tag so they are not taken into account (see Matt Cutts). Our approach is to look at the Web's engine demarcated source sets, or "spheres" (e.g. google web, google news, google blogsearch, google updates). Based on the currency of the hyperlink, the research tool we have developed is the issuecrawler.net. The insight of issue crawler is that hyperlinks are made selectively, thereby allowing one to locate "issues" on the Web, and their concomitant "experts". The claim however, is that the "quality" of the "currency" of the hyperlink itself, by which these experts are located, has in fact changed with social media, and in so doing it has reorganized the sphere (see Wired on Facebook's "plan to dominate the Internet"). To test this claims we look specifically at how Twitter might reorganize "expertise" on the web. Taking the issue of the BP oil spill as our starting point, we see what web is created by Twitter by following its actors, results which we compare against the issue network generated by the issuecrawler.Question
We want to know if social media reorganizes the spheres and how it can reorganize expertise. This will help us establish the currency and quality of the hyperlink in web 2.0. To this end our research asks: who should one follow if one is interested in a certain topic, how does one locate experts in social media and what type of issue flow do these expert feed?Protocol
On Twitter, users create lists around a specific issue; people to follow if you are interested in a specific topic. The public lists can subsequently be followed by other Twitter users (http://listatlas.com/ and http://listorious.com/ are two Twitter-based services that allow searching the lists created on Twitter). The premise of Twitter is that if your network is good, you will get good information? Thus, instead of finding websites as starting points, our approach here is to look for the experts and get their feeds. How then to find the experts? 1. The queries for the two list engines are: bp oil spill, bp oil leak, gulf oil leak, gulf oil spill, deepwater horizon. 2. From the results, take up to the top 10 based on nr of followers. 3. Fetch the members (or following) of these lists with http://marijn.digitalmethods.net/dmi/2010/twitter_list_member_scraper.php. data:Raw User Data 4. Triangulate the members. Data:The Experts 5. Take the members that are at least present in 4 of the lists 6. Fetch the urls from their tweets. Input username (without http://twitter.com/) in http://marijn.digitalmethods.net/dmi/2010/twitter_user_tweets.phpIssuecrawler 2.0 - hard links, soft links
We compare the account that comes out of this latter approach with those of the issuecrawler. Take users urls and see what kind of network; what web is created by Twitter by following Twitter’s actors Content network made by users Twitter content network analysis (find lists of experts; locate experts); Method: finding expert seeder/feed; scrape, harvest, retrieve their Tweets in specific time interval (maybe); either just extract urls and put them in issue crawler and see if they reply to each other; discussion or discourse; co-user analysis; semantic analysis; need of reaserchers; give us the experts and we dive you the discussion; have users hashtags and say who are the experts (sub-hashtags)Conclusions?
The issue network overlaps with Twitter experts with the big nodes.Data
Triangulated Twitter users: The Experts Raw User Data- oilspill_colinkedHashTags.gephi.pdf: oilspill_colinkedHashTags.gephi.pdf
- oilspill_colinkedHashTags.gephi.png:
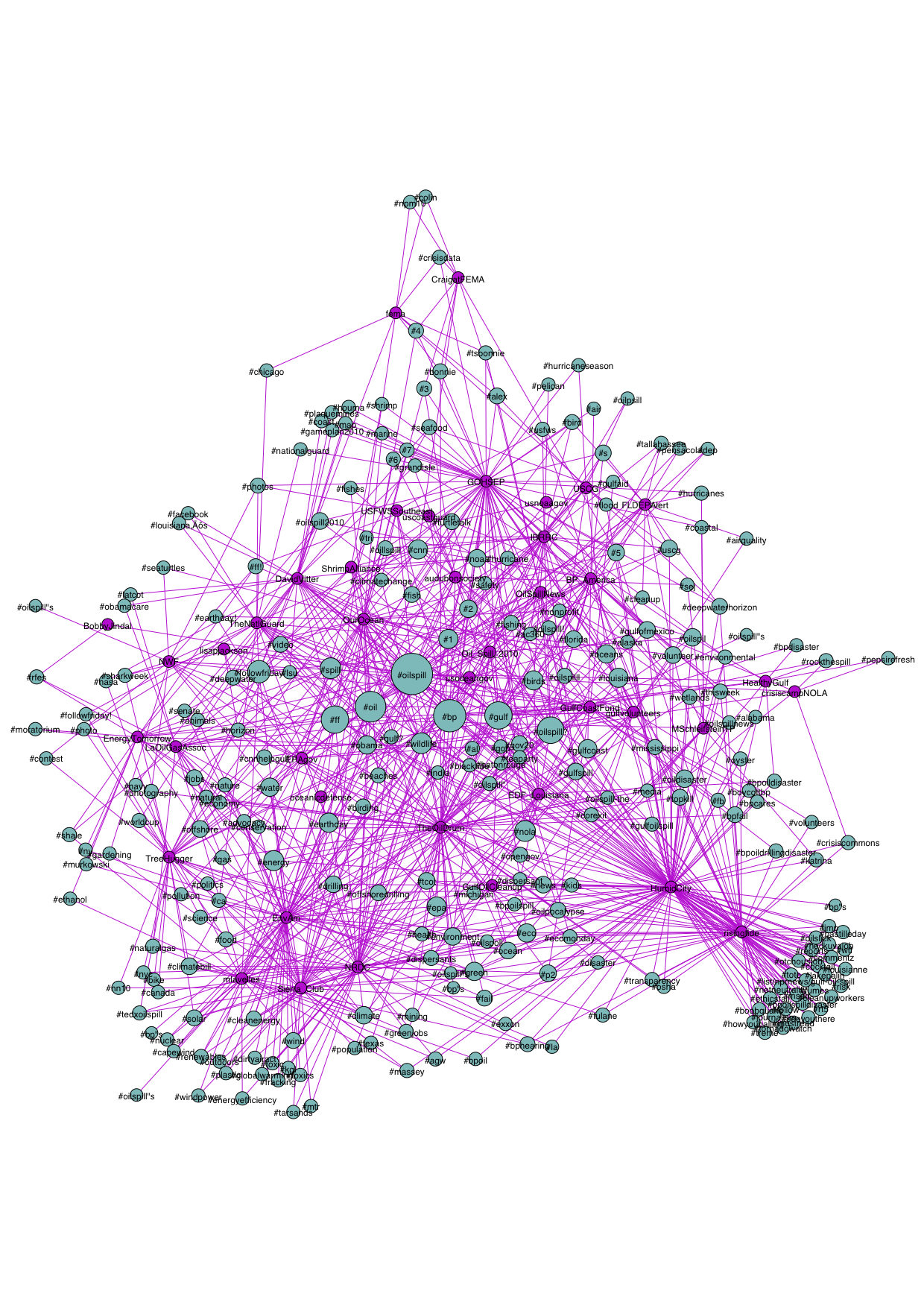
- oilspill_colinkedURLs.gephi.pdf: oilspill_colinkedURLs.gephi.pdf
- oilspill_colinkedURLs.gephi.png:
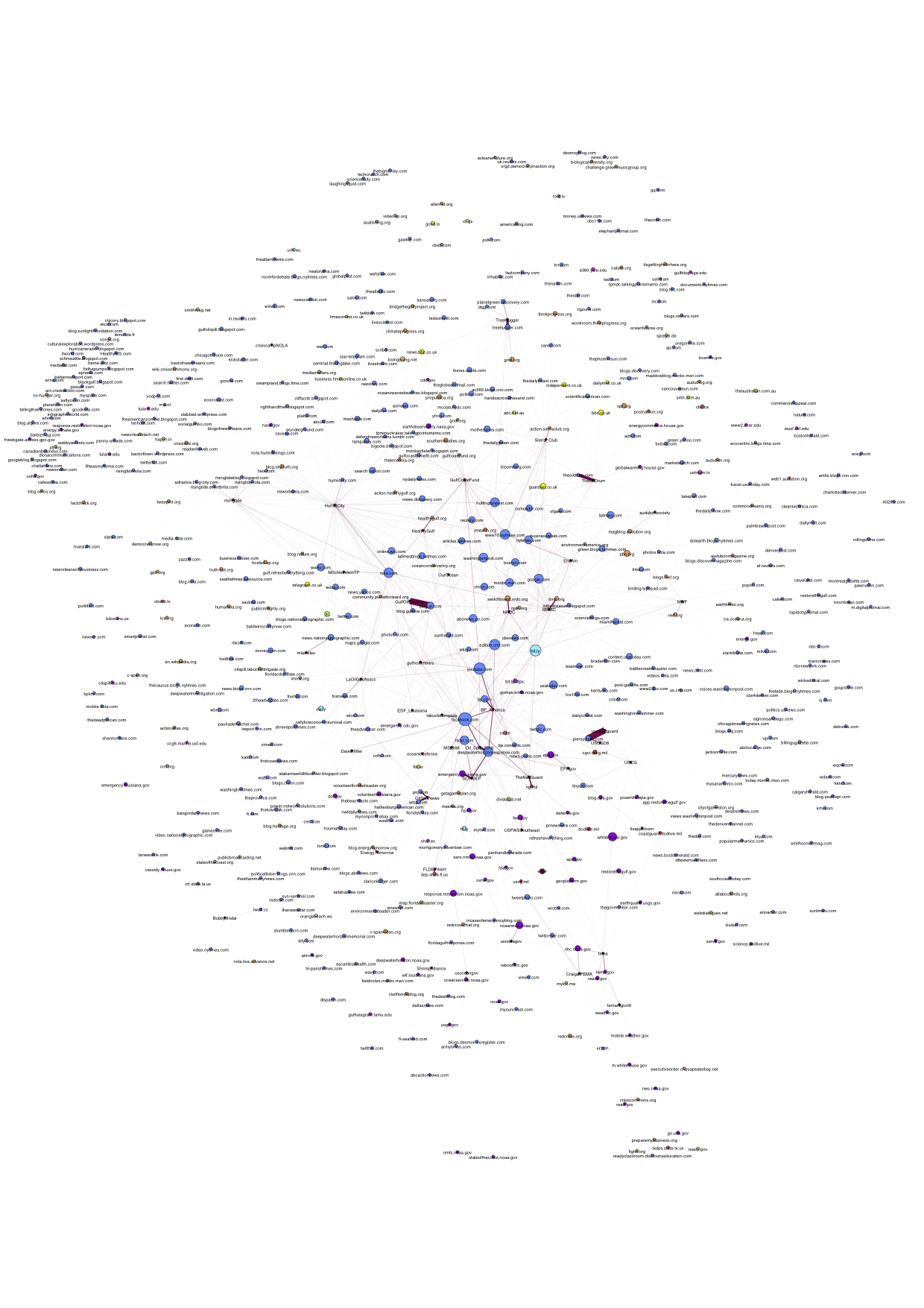


{kind=link}
{kind=link}
Edit | Attach | Print version | History: r8 < r7 < r6 < r5 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r8 - 10 Sep 2010, EstherWeltevrede
Ideas, requests, problems regarding Foswiki? Send feedback