Prompting for biodiversity. Visual research with AI (2024)
Team Members
Facilitators
Gabriele Colombo, Carlo De Gaetano, Sabine Niederer
Participants
Catherine Bouko, Elif Bozkurt, Matilde Ficozzi, Nicoletta Guglielmelli, Mark Mets
Contents
Summary of Key Findings
All generative models promote an overall idealized and stereotypical representation of biodiversity. Biodiversity is framed positively; there are no signs of biodiversity loss or its drivers. Biodiversity is predominantly associated with tropical landscapes and species. For different continents, biodiversity is associated with different species, whereas the 2023 bias for lack of insects has been partly compensated in 2024 results.
Each model has a distinct ‘house style’ when prompted for biodiversity. While some models have changed quite drastically in style from 2023 to 2024 (except Midjourney), they maintained their own distinct identities.
Using ChatGPT as a research assistant to analyze collections of images provided more detailed tags of species compared to usual computer vision tools such as Google Vision API. It tends to guess hybrids, tagging with scientific names animals that don’t exist. Further testing is needed, especially to review ChatGPT tags with biodiversity experts. As an information design assistant, ChatGPT commits multiple mistakes in summarizing and visualizing data, but can be corrected when the task is approached conversationally and not in one go.
1. Introduction
This project asks what kind of research one can do with machine-generated visuals and—more particularly—how we can conceptually and practically move from prompt engineering towards prompt design (Niederer & Colombo, 2024), in line with the ‘query design’ approach of the Digital Methods Initiative (Rogers, 2017). In this project, we address the problem of bias and the lack of diversity present in generative AI imagery and zoom in on the representation of biodiversity. We test different prompt design strategies, including ambiguous prompting for the generic term [biodiversity] and comparative prompting for biodiversity across continents. Comparing results for 2023 and 2024, we trace changes and consistencies in the model outputs regarding content and their respective ‘house styles’. By focusing on biodiversity, we aim to gain an understanding of how competing text-to-image models may deal differently (or similarly) with questions of diversity when not limited to the representation of humans and how this may have evolved in a year’s time (2023-2024).2. Initial datasets
We generated 20 sample images using the prompt “biodiversity” on Stable Diffusion, Midjourney, Dall-E 3 and Adobe Firefly. This expands the data we collected in 2023 for the same project (see wiki here), where we used Midjourney, Dall-e bing, Stable Diffusion, Craiyon, Dream, Lexica, and Adobe Firefly. We used the same strategy for prompting biodiversity for different continents (biodiversity in [Africa, Asia, Antarctica, Europe, North America, South America, Oceania]).
For Dall-E, images were generated through API as well as playground (regular chat) with new chat for each image one at a time. Midjourney images were created through Midjourney Alpha online user interface. Stable diffusion was gathered through Dreamstudio. Adobe Firefly was gathered through Adobe web interface, 4 images at a time. As Adobe required us to choose art of photo style, we chose photo. We compare these images to those from the predecessors of the same modeles from July 2023 that likewise includes 20 images per prompt.| Dall-E | Midjourney | Adobe Firefly | Stable diffusion | |
| biodiversity | generate a square image of biodiversity | biodiversity | biodiversity | biodiversity |
| photorealistic biodiversity | generate a pohotorealistic square image of biodiversity | pohotorealistic image of biodiversity | pohotorealistic image of biodiversity | pohotorealistic image of biodiversity |
| biodiversity in [Africa, Asia, Antarctica, Europe, North America, South America, Oceania] | generate a square image of biodiversity in Africa | biodiversity in Africa | biodiversity in Africa | biodiversity in Africa |
3. Research Questions
A. Full variety of biodiversity across models
- Which dominant ‘house styles’ for the representation of biodiversity can be discerned across visual generative AI models?
- How is biodiversity represented by different generative AI models, and how has this changed in a year’s time?
B. Comparative analysis of species across models with ChatGPT
- Which species dominate the representation of biodiversity?
- How can generative AI be put to use as a research aid in interpreting and captioning images, identifying species, structuring and even visualizing data?
C. Biodiversity world map
- How is biodiversity represented by Midjourney for different continents?
- How has this changed in a year’s time?
4. Methodology
Research protocol: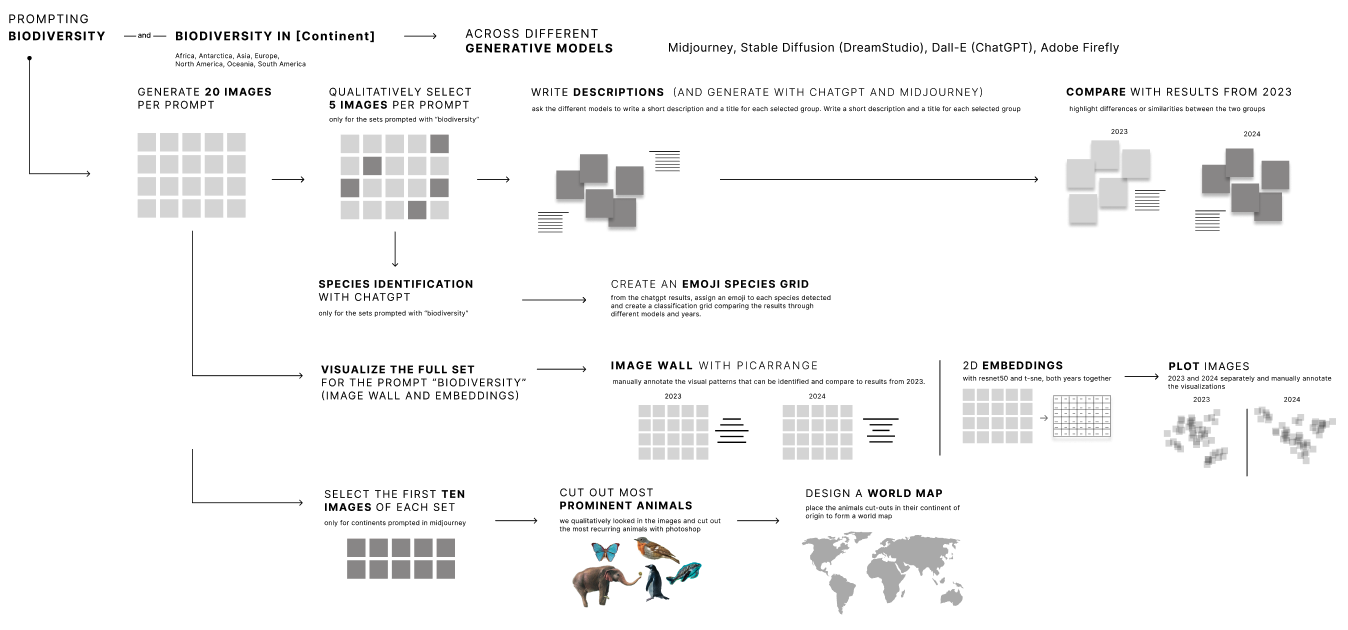
A. Full variety of biodiversity across models
We present the complete set of 160 images generated for the prompt biodiversity by four different models in both 2023 and 2024. These images are displayed as an "image wall," a scatterplot, and a selection of emblematic images chosen manually.
Image wall
This method displays collections of images in a grid, organized by similarity with the software PicArrange. Images are generated with the prompt [biodiversity], arranged in a grid, and annotated. The grids show the full variation in color, content, artistic styles and many other aspects. Presenting them side by side for both years reveals how the representation and house styles evolve over time.
Scatterplots
The method compares the formal features of our images to the formal features in resnet-50 pretrained model to derive the relative similarities between the images. The dimensions of the output of the model is then reduced with t-SNE to create a scatterplot map.
We created scatterplots to map the same images whilst showing their possible relative distances and clustering. The method takes the formal features of the images and compares them to the formal features of the images in the pretrained model to derive the relative similarities between the images. We compared the results from PixPlot and using Google Colab with Python. We chose to continue with the latter for better image quality. We used the Resnet50 pretrained model (He et al., 2016) to get the image embeddings. Resulting many dimensional embeddings were processed with T-SNE (Maaten, Hinton, 2008) for clustering and dimension reduction into 2 dimensions (default parameters gave a satisfactory result).
Emblematic images
For this subproject, researchers selected 5 emblematic images per model (of the 20 generated) for Dall-E, Midjourney, Adobe Firefly, and Stable diffusion. The style and content of each set of 5 images was manually described by the researchers, as well as by ChatGPT and Midjourney. Subsequently, the researchers compared and described the representation of biodiversity across models and over time (23-24).B. Comparative analysis of species across models with ChatGPT
This method involves using ChatGPT as a biodiversity expert, requesting a detailed analysis and categorization of species and elements within images, followed by transforming the findings into an emoji table. This approach provides a novel and accessible way to compare and analyze biodiversity across different AI-generated images. See the full conversation with ChatGPT here.-
Image Analysis:
-
Receive Images: Screenshots of the 5 selected images per model for the prompt ‘Biodiversity’ were uploaded to ChatGPT (both for 2023 and 2024 collections).
-
Identify Species and Elements: Prompt ChatGPT with ‘You are a biodiversity expert. Here is an image generated with AI for Biodiversity. Please, name the species you recognize in this image’.
-
-
Categorization:
-
Organize Species and Elements: Ask ChatGPT to group the identified species and elements into specific categories (e.g., Birds, Insects, Mammals, Plants, Ecosystems, Other Species/Elements).
-
Assign to AI Models: Categorize the identified species and elements based on the AI model that generated each image.
-
-
Create Detailed Table:
-
Structure the Table: Create a structured table that lists the identified species and elements under their respective categories for each AI model.
-
Populate the Table: Fill in the table with the species and elements identified from each set of images generated by the different AI models.
-
-
Transform to Emoji Table:
-
Finalize Emoji Visualization:
-
Review and Adjust: Ensure the emoji table accurately reflects the detailed table, maintaining consistency in the number of items and their categories. Copy the table to Google Spreadsheet and finetune the layout.
-
C. Biodiversity world map
Using the Midjourney data of 20 generated images for the prompt biodiversity in [continent], we took the first 10 images, cut out the 2–3 most prominent animals depicted in each picture, and arranged them on a world map. Inspiration was taken from Wild World, a hand-drawn world map of species by Anton Thomas (2023), as well as from the method of “knolling”.5. Findings
General findings:
We encountered multiple biases in image output during the image generation process that was different between models. Dall-E, used through Chat-GPT, stood out as creating more simplified (cartoonish style) images if many images were previously generated. In comparison, other models were more stable in their output. The models have their own house styles, which have evolved over a year, with Midjourney being the most consistent. The chosen model has a strong effect on the images represented, with noticeably large differences between models. Some models, like Dall-E, output changes over time based on usage patterns, making image consistency hard to achieve. An overall idealized and stereotypical representation of biodiversity is promoted by all models. We find it relevant that biodiversity is framed positively and in the present, with no signs of biodiversity loss and its drivers. Biodiversity is predominantly associated with tropical landscapes and species. For different continents, biodiversity is associated with different species, whereas the 2023 bias for a lack of insects has been partly compensated in 2024 results.A. Full variety of biodiversity across models
Image wall
 In this image wall of 2024, we identified five major patterns: photorealistic images of fruit, photorealistic images of nature in the forest, sceneries of tropical life depicted in a children's book style, human portraits embedded in nature, and taxonomies. Four patterns were identified in 2023, namely visions of paradise, diverse styles, enchanted forest bliss and nature’s fairy tale. The main difference lies in the prevalence of taxonomies in Dall-E in 2024.
In this image wall of 2024, we identified five major patterns: photorealistic images of fruit, photorealistic images of nature in the forest, sceneries of tropical life depicted in a children's book style, human portraits embedded in nature, and taxonomies. Four patterns were identified in 2023, namely visions of paradise, diverse styles, enchanted forest bliss and nature’s fairy tale. The main difference lies in the prevalence of taxonomies in Dall-E in 2024.
Scatterplots
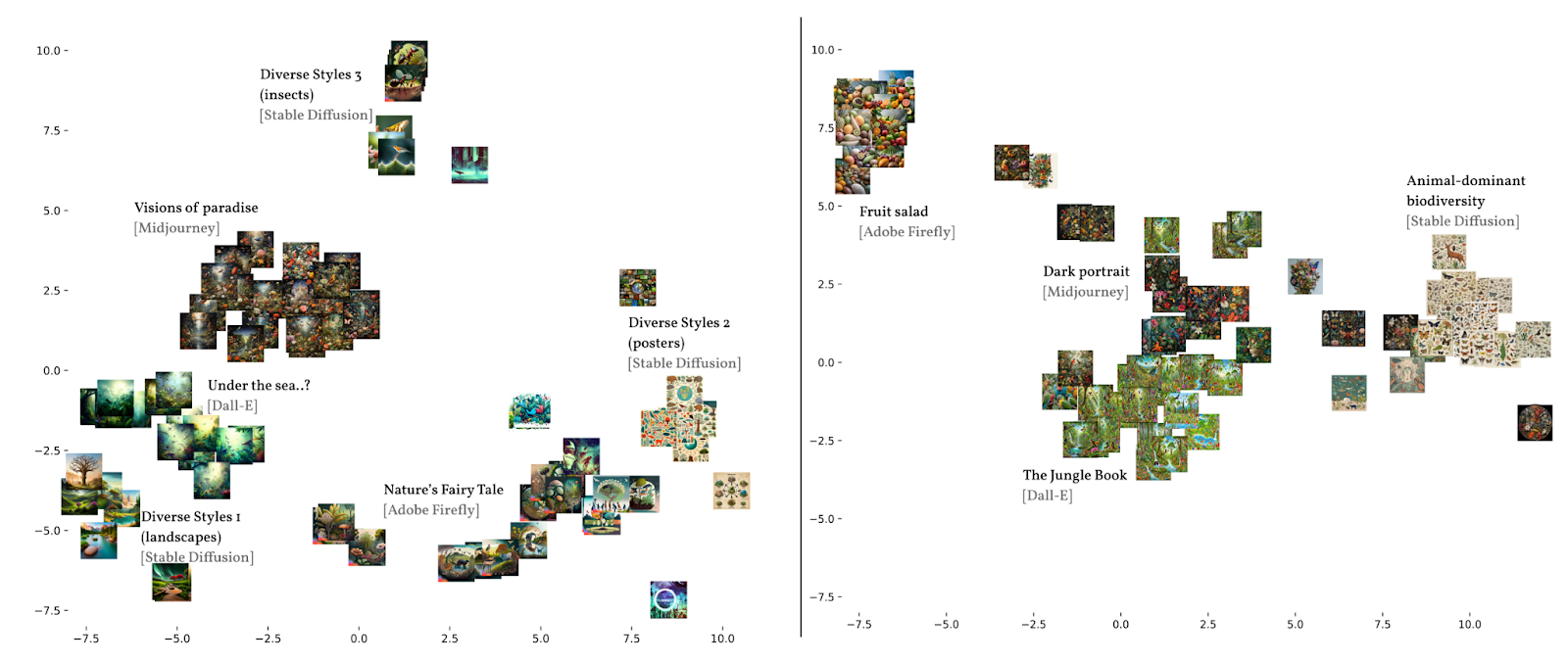
The map illustrates that each model has a distinct “house style” (Manovich, 2024) that divides the set into clusters. Here, we can recognize the clusters from the qualitative image comparison, but also see how certain models produce more diverse styles (in particular, Stable Diffusion). While certain models have changed quite drastically in style over the past twelve months, they have not become more similar. The scatterplots exemplify that from this formal features perspective, Adobe model has had a more drastic style change than Dall-E and Stable Diffusion, and that Midjourney is the most consistent.
There is a noticeable variability and homogeneity in the representation of biodiversity, whilst the models still form clear clusters (on T-SNE plot and manual categorization). The plot also brings out further subgroups besides the 4 manual categorizations. For example, there are 3 subgroups in “Diverse Styles” in 2023. Some differences between models are more pronounced than others, like Adobe Firefly in 2024. Adobe model’s style change is also perhaps the most noticeable from 2023 to 2024 in comparison to Dall-E and Stable Diffusion.Emblematic images

Overall, there are major changes, in terms of colors, subjects and styles, from all the models except for Midjourney.
-
For Stable Diffusion, 2023 featured diverse styles, while 2024 showed uniform, simple 2D drawings.
-
For Dall-e, 2023 had a mysterious atmosphere, but 2024 is bright and colorful with more animals, yet few aquatic species.
-
Midjourney remains consistent in color and detail, with the addition of a human face in 2024.
-
Firefly shifted to an ad-like style in 2024, with fewer animals and a focus on fruit in the flora.
Stable Diffusion: In 2023, biodiversity was depicted in various styles. These included expansive landscapes, macro-focus images, diagrams, and simple scientific botanical drawings. In the 2024 dataset, however, all the images present the same style, featuring simple scientific botanical drawings in a two-dimensional presentation without depth or movement.
Dall-e: The 2024 images have lost the mysterious atmosphere of 2023, showing more bright and colourful daytime scenes now. Landscapes are filled with animals, and the variety of species has increased. Even though water is always present in the scene, we hardly see any aquatic animals.
Midjourney: The color palette and attention to detail in depicting plants and animal species remains unchanged between 2023 and 2024. The main difference is the appearance of a human face.
Firefly: The style of the images drastically changed, moving towards an ad-like style. The variety of animals has decreased, and the flora changed from trees and lichens to mainly fruit and some background trees.
B. Comparative analysis of species across models with ChatGPT
Read an extensive comparative analysis with ChatGPT here, describing in detail the differences and similarities in species represented across time and models.
When asked what is missing from this overview of biodiversity, ChatGPT highlights a few interesting points:
-
While fungi are depicted to some extent, microorganisms are largely absent, despite their critical roles in ecosystem functioning.
-
Many less charismatic but ecologically important species, such as small mammals, amphibians, and a wider variety of reptiles, are underrepresented.
-
Specific habitats like wetlands, deserts, and grasslands are less frequently illustrated compared to forests and rivers.
-
The behavior of species, such as hunting, foraging, and huddling together, is not extensively represented, which is crucial for understanding ecological dynamics.

C. Biodiversity world map
As for the continents, biodiversity is associated with different species; in some cases, certain species dominate the continent (such as colorful tropical birds in South America and penguins in Antarctica). The species bias found in 2023, with insects mainly represented by colorful butterflies, seems to have been compensated for in 2024, when more insects (including fictional ones) are depicted. Midjourney seems to find it the hardest to generate images for biodiversity in Asia, rendering fictional species, including giraffe-hybrids.
The 2023 world map revealed that Midjourney favored colorful and tropical species when visualizing biodiversity across continents. South America was predominantly represented by tropical birds, which also appeared in depictions of other regions. The only insects featured were butterflies, highlighting a narrow focus on certain charismatic species. Meanwhile, Antarctica was exclusively populated by penguins, underscoring a simplified and stereotypical portrayal of the continent's biodiversity.
In 2024, we see that many more insects have entered the realm of biodiversity, and the colours have become more muted for some continents (e.g., Europe and North America), indicating the model tries better to replicate the fauna of the continent, at least in its colour palette. The model still has the hardest time depicting biodiversity in Asia, which results in many fictional and hybrid creatures. In depictions of biodiversity in Oceania, most species are depicted underwater, even the birds. Antarctica still is only populated by penguins.

6. Conclusions
The findings from the research highlight several overarching conclusions regarding the evolving capabilities and limitations of generative models in visualizing biodiversity. The models display distinct trajectories in their ‘house style’ aesthetics, with Midjourney maintaining a consistent aesthetic while others, such as Firefly and Stable Diffusion, have undergone significant changes. Longitudinal analysis to trace these changes could reveal whether the models will become more uniform in style or -as this comparative analysis indicates- remain distinct.
Despite some progress, the underrepresentation of species persists. While the inclusion of more insect species besides butterflies in 2024 signals improvement, less charismatic insects and microorganisms, as well as specific habitats like wetlands and deserts, remain underrepresented.
The comparative analysis of the models underscores their differences in representing species. For instance, Dall-E’s brighter and more animal-rich visuals in 2024 suggest an improvement in biodiversity richness, yet aquatic species remain conspicuously absent. Firefly’s focus on fruit and Midjourney’s consistent color palette and detail further reflect distinct stylistic directions, while Stable Diffusion’s reductive shift emphasizes simplicity at the expense of diversity. These variations highlight the models’ differing approaches to representing the natural world.
Biases in model outputs also remain evident. These biases are reflected in overly simplistic portrayals of certain regions (such as Asia and Oceania), stereotypical species representations, and challenges in visualising the drivers of biodiversity loss.
Overall, the findings suggest that while generative models have made strides in visualizing biodiversity, they require further development to incorporate more contextual complexity. Expanding representation to include less-stereotypical and underrepresented species and habitats, as well as capturing animal behavior (e.g., hunting, eating, huddling together), could foster a deeper and more comprehensive understanding of biodiversity.
When prompting generative AI ambiguously, we see biases not only in the represented species but also in the formats of the generated images. For example, there is a tendency to represent continents with maps or certain cities with iconic buildings depicted in a photographic style. This technique is useful to surface model-specific house styles and representation formats.
The technique of ambiguous prompting can be applied with a dual objective: observing what the machine leaves out or fails to depict (machine bias research) and serving as a process that helps us clarify what we believe a specific word or concept should represent. In the case of biodiversity, it is easy to notice when certain species are over-represented, for example, when the only insects are butterflies or imaginary creatures. In this case, an expert reading of the results can provide deeper insights into the inconsistencies and missing elements in the representation of species. For example, birds having the wrong colours or plants depicted side by side that would not grow together in nature. Carefully reading the results of ambiguous prompting requires knowledge of the issue to avoid comparing machine bias - what is in the results- to human bias - how do these results match our assumptions of what should be in the images.
7. References
Harrison M. (2023, February). ChatGPT is Just an Automated Mansplaining Machine. Futurism. Retrieved from https://futurism.com/artificial-intelligence-automated-mansplaining-machine
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA. pp. 770-778, doi: 10.1109/CVPR.2016.90.
Luccioni, S. (2022). Diffusion Bias Explorer—A Hugging Face Space by society-ethics. Retrieved from: https://huggingface.co/spaces/society-ethics/DiffusionBiasExplorer
Monge, J. C. (2022, August 25). Dall-E2 VS Stable Diffusion: Same Prompt, Different Results. Retrieved from: https://medium.com/mlearning-ai/dall-e2-vs-stable-diffusion-same-prompt-different-results-e795c84adc56
Munk, A.K. (2023) Coming of Age in Stable Diffusion, Anthropology News website, May 8. Retrieved from https://www.anthropology-news.org/articles/coming-of-age-in-stable-diffusion/
Niederer, S., & Colombo, G. (2024). Visual methods for digital research: An introduction. Polity Press.
Nicoletti, L., & Bass, D. (2023, April 23). Humans Are Biased. Generative AI Is Even Worse. Bloomberg.Com. Retrieved from https://www.bloomberg.com/graphics/2023-generative-ai-bias/
Van der Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of machine learning research, 9(11). Retrieved from https://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback