Mapping regimes of data access - positioning researchers in platform ecologies
Team Members
Noemi Crescentini, Kieran Hegarty, Giuseppe M. Padricelli, Bernhard Rieder, CJ Reynolds
Summary of Key Findings
-
Analysis of multiple platforms has several advantages, offering insight into how platform governance and access regimes shape each other across different platform environments, as well as drawing out key distinctions. We found that Twitter has come to see external research as an instrument to help develop their service. Facebook, meanwhile, sees external research as a concession that is not mentioned in the ToS at all and not implemented as a specific "track" within the scope of the developer API. For YouTube, external research appears as an afterthought. There are no specific provisions, neither in the ToS, nor in the wider developer documentation. These three access regimes have existed across different platform environments at different times, with the ebb and flow of platform governance, and the position of researchers being shaped by changes to how actors in larger and more diverse developer communities are positioned.
- Overall there has been a general trend towards more restrictive access conditions for researchers across multiple platform environments. However, pointing simply to increasing restrictions to researcher access over the past 15 years is too simplistic. Rather, researchers are but one group of API users that have different relationships to various platforms. Access regimes for researchers shape, and are shaped by, the actions and demands of other groups that seek access or are sought out by platforms with the promise of access to platform data. As such, there is a need to study how access unfolds at multiple scales and its differential impact on different groups (and different types of research).
- There is a need for research to consider not just major controversies and scandals in social media data access regimes (Bruns 2019), but also incremental changes over time, and how technical and legal regimes for governing access mutually shape each other and the implications for "platform observability" (Rieder & Hofmann 2020). A focus on a "post-API age" (Tromble 2021; Perriam et al 2020) overlooks continuities as well as disjunctures in data access regimes, and how existing technical and legal regimes are built on top of, and steadily reorient, existing arrangements.
1. Introduction
For over a decade, researchers have been using APIs and web scraping to gather data from social media services to further our knowledge of both the platforms themselves and the social and cultural phenomena they are implicated in. Due to a variety of factors, this has often happened under problematic, precarious, and even tumultuous conditions. But other than stand-out events that have received considerable attention, such as the 2019 "APIcalypse" (Bruns 2019) or the recent introduction of Twitter’s API v2, there are many open questions concerning the practical, epistemological, and legal dimensions of existing access modalities. In this project, we seek to combine a number of research methodologies to fill in some of the gaps in understanding that persist around API-enabled data-driven research.
This was prompted by the many changes in data access research tool developers and researchers have had to grapple with over the last years. This includes outright loss of access, but also changes in scope and specification, various kinds of inconsistencies, and active technical and legal countermeasures to data gathering. Adding clarity to this increasingly complex and heterogeneous situation would help the academic community with their task to generate robust empirical knowledge concerning the many different ways social media platforms have come to affect societies around the globe. Better understanding of access regimes will help researchers in adjusting their goals and expectations, in interpreting the validity of findings, and in planning sustainable research projects; it may also prompt functional changes to research tools, better and more detailed documentation, and recommendations for best practices.
In this sub-project we investigated how three major platforms—Facebook, Twitter, and YouTube —present themselves to researchers in terms of data access, both through their web presence (e.g. subsites for research, developer documentation) and more specifically via their API’s Terms of Service (ToS).
2. Research Questions
While we started out considering a variety of research approaches, our work eventually coalesced around the following research questions:
-
Q1: How have platform API ToS changed over time? Do the evolution of these terms differ markedly across Facebook, Twitter, and YouTube?
-
Q2: What can we learn from the developer websites of Facebook, Twitter, and YouTube (not limited to ToS documents) about how platforms govern researchers specifically? Do they frame research access as a part of or separate from developer access?
-
Hypothesizing Q1: We hypothesized that, given their status as legal documents, the current versions of platform ToS documents look very similar across the majority of the texts, but that there may be notable differences prompted by past scandals (e.g., Facebook and Cambridge Analytica), the different types of data being handled (e.g., short form text on Twitter vs. videos on YouTube), or platform dispositions towards outside research (e.g., Twitter specifically offering an academic option for API keys).
-
Hypothesizing Q2: We expected that each web presence would have specific mentions about the rights of and expectations for researchers using the API, and perhaps also sections of the websites aimed specifically at researchers.
3. Methodology
Q1 - Terms of Service:
To create a dataset of ToS documents, we:
-
Searched for URLs of API Terms of Service and other legal use policies for APIs. Multiple URLs were identified for each platform under consideration (YouTube, Twitter, Facebook)
-
Ran collected URLs through the Internet Archive Wayback Machine Link Ripper and gathered one result per month for the duration of existence of each link.
-
Saved the HTML pages found by the Link Ripper, then manually extracted the text of each page.
To analyze the collected data, we:
-
Ran extracted texts through word count analyses to identify size of documents by word and sentence, and identify most used words.
-
Built a tool—diffstream—to compare changes over time for each ToS "stream" (i.e. the sequence of document versions over time).
-
Used diffstream to investigate textual changes between documents over time, including document length and readability.
Q2 - Web presence:
-
Starting from a set of manually collected URLs for each of the three platforms, we used Hyphe (Jacomy et al. 2016) to run network crawls to map the connections of each platform’s developer websites to other parts of the platform and off-platform networks.
-
We analyzed the resulting networks to understand how data access is framed in terms of target audiences and whether and how (external) academic research is presented as a particular use case.
4. Findings
Findings are presented for each platform, with a section 5 ('Discussion') addressing how these findings relate to our research questions and hypotheses.
YouTube
The first version of the YouTube API ToS surfaced on the Wayback Machine on 11 September 2007 and had been recently created, dated 17 August 2007. The ToS opens with a statement couched in casual language, noting, "The following Terms of Service (ToS) can feel like a legal document because, well, it is a legal document". The language is indicative of how YouTube was positioning itself at the time as both engaging with yet outside of corporate or legalistic discourse (GIllespie 2010).
Including the note at top, the 2007 API Terms of Service document is 3523 words broken into 179 sentences. Discounting stop words, "YouTube" is the most frequently appearing word at 168 instances, followed by "API" at 103 instances. "Access" appears 15 times. By comparison, the latest version of the YouTube API ToS (accessed 13 January 2022) was last edited 1 July 2021 and contains 6239 words broken into 325 sentences. Discounting stop words, "YouTube" is the most frequently appearing word at 278 instances, followed by "API" at 202 instances. "Access" appears 31 times.
The changes from 2007 to 2022 indicate a more than 77% increase in the size of the Terms of Service document over a period of approximately 14 years, and does not include the size of YouTube 's separate Developer Policies document, first surfaced in the Wayback Machine in August 2016 and specifically noted as being "part of the updated YouTube API Services Terms of Service." The August 2016 version of the Developer Policies contains 7876 words broken into 316 sentences. Discounting stop words, "API" is the most frequently appearing word at 370 instances, followed by "YouTube" at 244 instances. "Access" appears 65 times. By contrast, the Developer Policies (accessed 13 January 2022) include 9044 words broken into 376 sentences. Discounting stop words, "API" is the most frequently appearing word at 446 instances, followed by "YouTube" at 281 instances. "Access" appears 68 times. These changes indicate nearly a 15% increase in the size of the Developer Policies over approximately 5 years. Taken together, these two policy documents, as compared with the original 2007 API ToS, indicate an increase of more than 333% in the size of the document over approximately 14 years (3523 words to a combined 15283 words).
We developed a tool named diffstream to compare the changes made to a large corpus of documents. This was necessary as most difference comparison tools only allow for a one-to-one comparison of two documents, but we wanted to see the changes to a document across a large dataset and progressively through time. YouTube, for instance, has API Developer ToS and Policies dating from 2007 to 2022, and also has specific versions of the current ToS for the Americas, Asia-Pacific, Europe, the Middle East and Africa, and Russia markets. All versions of the ToS are in English, except the Russian market version (which is in Russian). The EMEA market version includes an English version of the ToS, which we scraped, as well as Dutch, French, German, and Spanish versions, which we did not scrape. Diffstream also allowed us to see that around mid-2016, YouTube marked both its Developer Policies and the API ToS as joint contributors to its legal agreements.
Readability scores, generated using the Gunning Fog Index, range from a high of 31.6 in 2008 18.9 in 2016 at the low end, currently sitting at 19.6 for the API ToS. Scores for the developer policies range from 18.9 in 2016 to 19.6 in 2022. These scores are very high, as the index considers anything over a 17 to be a "college graduate" reading level. Such high scores are not necessarily surprising, given the length and legal complexity of terms of service documents, and fall in line with previous research on public-facing terms of service (Fiesler, Lampe, and Bruckman, 2016; Jensen and Potts, 2004).
Network analysis run via Hyphe (Jacomy et al. 2016) indicates that YouTube 's API is connected to the broader online developer communities. 10 in pages were crawled, using both broader domains like developers.google.com and googledevelopers.blogspot.com and specific domains like the direct links to the API ToS and Developer Policies. 71 connected domains were discovered by these crawls, mostly consisting of links to sites like apache.org, devpost.com, and github.com. There were some links to other Google-based domains like codingcompetitions.withgoogle.com and cloud.withgoogle.com.
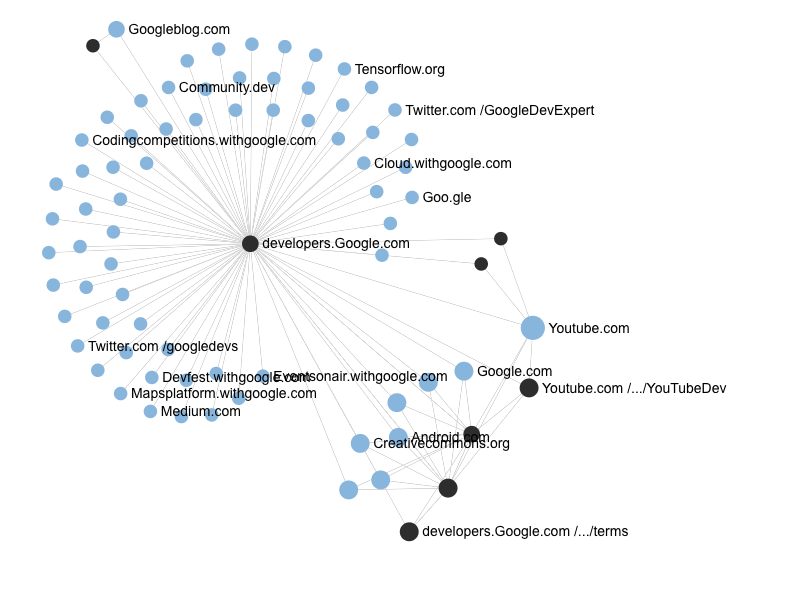
Figure 1: YouTube developer networks. Non-Directional Graph from Hyphe. Crawled domains in black, discovered domains in blue.
Preliminary close readings of the policy documents show a significant increase in the length and linguistic complexity of such documents, as indicated by our word counts and readability scores. Additionally, on YouTube, there is clear evidence of document proliferation as a single API ToS in 2007 becomes an API ToS, set of Developer Policies, and a Developer Compliance guide by 2022.
Twitter released its first public API in September 2006, and Twitter became known for its relatively open developer access, attracting developers to the platform to produce apps that allowed access and different uses of Twitter (Bucher 2013). These include many services and tools central to the service, including URL shortening services and the Twitter search function (Burgess and Baym 2020). From 2006 to 2010, Twitter made an effort to promote use of their API among a developer community, including through the Twitter Technology Blog and Twitter Developer Talk Google Group. As is documented in Bucher (2013), the relationship between developers and Twitter soured between 2010 and 2012. In an effort to improve platform stability, brand consistency and grow the company, Twitter began to exert more control over use of the API and the rules governing its use. This resulted in the introduction of the first developer terms of use, the Developer Rules of the Road in June 2011. API rate limits were dramatically curbed under the new rules. Bucher (2013:15) notes that "developers immediately expressed a huge disdain towards what they essentially felt as a hypocritical move from Twitter. Once utterly dependent on developer efforts, Twitter was now perceived to obstruct the very same people that had helped build Twitter in the first place".
The restrictions on APIs, of course, also had an impact on data access for researchers. In a way, researcher access to Twitter data can be seen as a byproduct of the company's desire to attract developers to use the API. 'Research' was not mentioned specifically in the Twitter API terms of use until the shift from the Rules of the Road (2011-2014) to the Development Agreement and Policy (2014-current). Even then, it was only mentioned in negative terms. This included the term "you will not conduct and your Services will not provide analyses or research that isolates a small group of individuals or any single individual for any unlawful or discriminatory purposes" (Developer Agreement and Policy, 22 October 2014), which has remained among the terms with slight variations over the years to include explicit mention of surveillance. This suggests the company did not yet see academic researchers in instrumental terms (either in terms of their latent economic value or ability to improve platform dynamics in the interest of Twitter), as became clear later, but rather as a risk to be managed. Academic researchers were first mentioned explicitly in the November 2017 update, in reference to more permissive terms for content redistribution. The next key change occurred with the latest iteration of the Developer terms (March 2020) which, again, explicitly reference more permissive terms for academic researchers, specifically in relation to content redistribution.
While controversies emerged about the distribution and amplification of politically extreme content and disinformation, Twitter promoted use of the API by researchers in order to "improve conversational health on Twitter" (March 2020). To facilitate this, Twitter explicitly enabled use of "the Twitter API and Twitter Content to measure and analyze topics like spam, abuse, or other platform health-related topics for non-commercial research purposes" (Developer Agreement and Policy, June 2020). More recently, with the release of the Twitter API v2, the platform has provisions for academic researchers to gain expanded access to Twitter data. To be eligible for academic research access, developers must complete an Academic Research application, with evidence of university affiliation, and detail "a clearly defined research objective" with "specific plans for how you intend to use, analyze, and share Twitter data from your research" (Twitter, 2021). The rationale behind acceptance/rejection of applications to the academic research track remains opaque, as the research team found when the process and outcome of their applications for access varied across different members.
Presently, use of the Twitter API assumes acceptance of the Developer Agreement and Policy (March 2020). This agreement and policy govern access to, and use of, material gleaned through the APIs. The agreement gives license to conduct analysis of Twitter content, within the terms of the agreement. However, Twitter may change this policy: the agreement binds the entity to the latest policy (this may include ceasing access). A history of these documents shows 14 changes, with four major changes:
-
Developer Rules of the Road (1 June 2011)
-
Developer Agreement and Policy (22 October 2014) - change in 95% of content
-
Developer Agreement and Policy (18 June 2017) - change in 20% of content
-
Developer Agreement and Policy (10 March 2020) - change in 66% of content
The difference in language and content between the Rules of the Road (2011) and the first Agreement and Policy (2014) are striking. Compare the information introduction to the Rules:
The Rules will evolve along with our ecosystem as developers continue to innovate and find new, creative ways to use the Twitter API, so please check back periodically to see the current version. Don’t do anything prohibited by the Rules and talk to us if you think we should make a change or give you an exception.
With the dense, legalistic tone of the Agreement, which opens with the all-caps, "IF YOU DO NOT AGREE TO BE BOUND BY THIS AGREEMENT, THEN YOU MAY NOT ACCESS OR OTHERWISE USE THE LICENSED MATERIAL". This shift typifies what Burgess and Baym (2020:11) refer to as "Twitter’s turn away from the Web 2.0 'open innovation' paradigm… toward a centralized, advertising- driven one, within which the user experience and user metrics need to be contained and controlled."
Analysis using diffstream shows four key changes in 2014, 2017, 2018, and 2020. With each of these successive changes, the length of the terms governing use increased, from 3886 words in 2011 to 9807 words in 2021. Along with more subtle changes to the terms over the past decade, there have been two more drastic alterations. These were the shifts from the Rules of the Road (2011-2014) to the first Developer Agreement and Policy in 2014, and from the 2018-2020 agreement and policy to its latest iteration (10 March 2020), which were—in essence—complete rewrites. These two changes are shown in figure 2 below, with the red dots showing the relative similarity/difference to the previous terms (the higher the dot, the greater the change).

Figure 2: A visualization of changes to the terms governing use of the Twitter API using the diffstream tool (beta v0.1). The red dot shows the relative similarity/difference to the previous terms (the higher the dot, the greater the change). The Y axis shows the number of words.
Looking at the changes over time, the following trends are detected:
-
A steady reduction in the amount of user tokens available to users of the API, with use of more tokens subject to additional terms of use.
-
A greater level of scrutiny over API use, with a greater degree of vetting uses of the API through detailing intended use in applications.
-
Sanctions introduced for any deemed misuse of the API, including revoking access.
-
Increased protection of a stable, consistent Twitter 'brand' (e.g. the introduction of 'Brand Assets and Guidelines' in 2014).
-
Explicit efforts to leverage developers to attract more users to the platform (both non-users and by limiting the replication of "the Core Twitter Experience" in external environments).
-
An increased focus on data security and integrity, particularly from 2017 onwards when a specific 'security' clause was introduced, and new terms were presented in response to the implementation of the GDPR in May 2018 .
-
A greater focus on user privacy. Uses of the term "privacy" increased four times between 2011 and 2021, from 5 to 23.
Explicit changes occured in the shift from the Rules of the Road (2011-2014) to the first Developer Agreement and Policy in 2014, in both style and content, particularly provisions to protect Twitter's intellectual property, and measures to nominally protect user privacy. Privacy provisions were strengthened with a less drastic alteration to the terms in June 2017, including explicit mention of human rights frameworks, a clause prohibiting targeting or profiling individuals based on a range of characteristics, and terms requiring developers to ensure content changed on the platform is reflected in a change to any data. The latter demand—to ensure datasets change to match the live platform—has significant implications for researchers. As Richard Rogers (2018:561) notes:
Twitter… asks tweet collectors to obey Twitter’s Rules and be a ‘good partner’ by routinely removing from one’s tweet collections those that have been withheld or deleted. It becomes a debatable norm when Twitter purges accounts that a researcher feels are worthy of study, such as Russian disinformation trolls or alt right figures…
A minor change later in 2017 was the first to make explicit provisions for academic researchers, particularly in regard to redistribution of content, as discussed above. The last major change occurred in March 2020, with around two thirds of the previous Developer Agreement and Policy altered. This included the 'post-Cambridge Analytica' clause that "you will not or attempt to... use Twitter Content, by itself or bundled with third party data, or derivative analysis therefrom, to target users with advertising outside of the Twitter Applications, including without limitation on other advertising networks, via data brokers, or through any other advertising or monetization services". At the same time, the new policy opened with the first explicitly developer-friendly language since the Rules of the Road (2011-2014) and more plain language.
Although changes to the terms governing the use of the Twitter API do not necessarily map neatly onto broader debates around platform power and data access, paying attention to their temporality reveals how Twitter sees its role in broader networks of knowledge production. The framing sees knowledge production embroiled in platform logics, whether in terms of attracting users to the platform, or helping to "improve conversational health on Twitter". It is notable that researchers are increasingly seen as a user group, and attracted to the platform by greater access to Twitter data. It is easy to see this move to "improve conversational health" as an effort to abate "wary advertisers, who are not keen to see their products paired with an X-rated video or a xenophobic rant" (Gillespie 2018:13). Critically, researchers are increasingly framed as instrumental agents, entrusted (through data access) to resolve larger problems surrounding public discourse, in which the platform is deeply enmeshed (see figure 3).
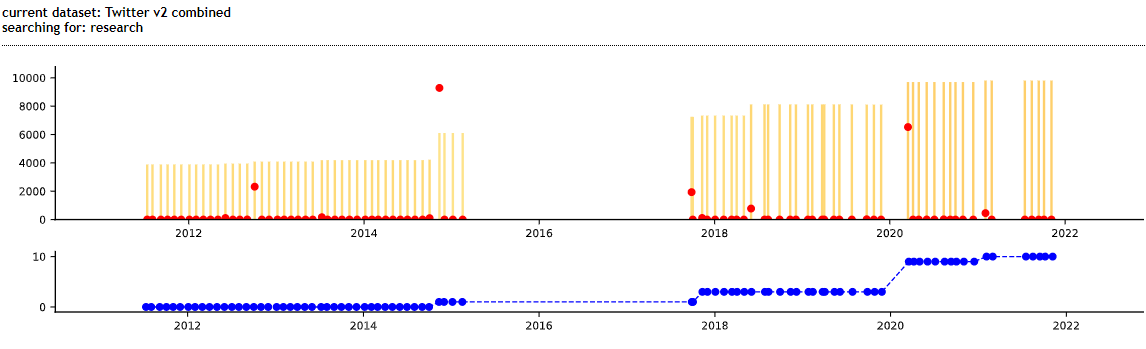
Figure 3: A visualization of changes to the terms governing use of the Twitter API using the diffstream tool (beta v0.1). The blue line graph at the bottom shows instances of the word "research" over the period 2011 to 2022. A steady shift in how research is seen, from invisibility (until 2014), to a source of potential risk (2014-2020), to an instrumental user group called upon to resolve problems relating to the platform (2020-current).
Network analysis run via Hyphe (Jacomy et al. 2016) indicates that Twitter's API exists within a largely self-contained network of Twitter-focussed developers (see figure 4). Three pages were crawled—the developer homepage (developer.twitter.com) and two key documents that govern use of the Twitter API—the Developer Policy and the Developer Agreement. 33 connected domains were discovered by these crawls, mostly consisting of links to other Twitter developer community sites. An illustration of these networks (exported from Hyphe to Gephi) is displayed in figure 4.
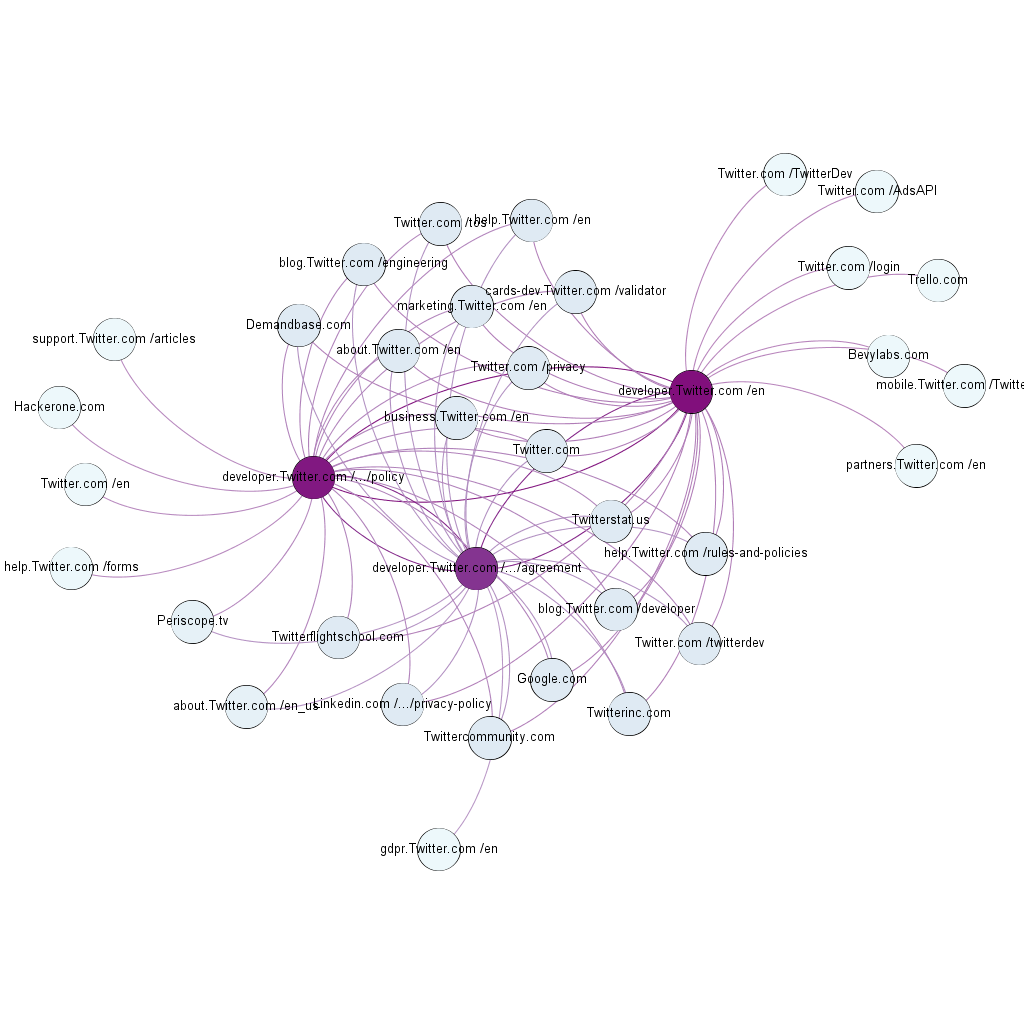
Figure 4. Twitter developer networks. Non-Directional Graph from Hyphe. Crawled domains in purple, discovered domains in light blue
"Terms and conditions are central in acquiring user consent by service providers. Such documents are frequently highly complex and unreadable, placing doubts on the validity of so-called informed consent" (Luger, Moran, Rodden 2013). At the Facebook developer event in July 2007, the company launched Facebook Platforms, a set of APIs and services that enabled conditional access to platform data for development. Just a month before, the first Facebook Terms of service (ToS) were launched. Using the Internet Archive WayBack Machine and the DMI Wayback Machine Link Ripper, we obtained monthly snapshots of the Facebook developer website from 2007 to January 2022.
The data reveals 25 ToS revisions and three corresponding documents title changes:
1. Developer Terms of Service (1 June 2007)
2. Developer Terms of Service (25 July 2007)
3. Developer Terms of Service (4 December 2008)
4. Platform Policy Overview (4 June 2009)
5. Developer Principles and Policies (21 April 2010)
6. Facebook Platform Policies (29 October 2010)
7. Facebook Platform Policies (15 November 2010)
8. Facebook Platform Policies (22 December 2010)
9. Facebook Platform Policies (10 February 2011)
10. Facebook Platform Policies (24 May 2011)
11. Facebook Platform Policies (1 July 2011)
12. Facebook Platform Policies (27 July 2011)
13. Facebook Platform Policies (12 August 2011)
14. Facebook Platform Policies (22 September 2011)
15. Facebook Platform Policies (10 October 2011)
16. Facebook Platform Policies (15 December 2011)
17. Facebook Platform Policies (25 January 2012)
18. Facebook Platform Policies (20 February 2013)
19. Facebook Platform Policies (9 April 2013)
20. Facebook Platform Policies (28 June 2013)
21. Facebook Platform Policies (20 August 2013)
22. Facebook Platform Policy (14 March 2018)
23. Facebook Platform Policies (25 April 2019)
24. Facebook Platform Policies (9 June 2020)
25. Facebook Platform Policies (26 June 2020)
More changes have emerged in terms of content and of context.
By the first version (1 June 2007) is possible in fact to retrace the legal assumptions from the beginning of the document "BY ACCEPTING THESE TERMS AND CONDITIONS, OR BY USING OR ACCESSING ANY PORTION OF THE FACEBOOK PLATFORM, YOU IRREVOCABLY AGREE TO THE TERMS OF THIS AGREEMENT, AND YOU REPRESENT AND WARRANT THAT YOU HAVE ALL AUTHORITY NECESSARY TO BIND YOURSELF (AND, IF YOU ARE EMPLOYED BY OR OTHERWISE REPRESENT ANY CORPORATION OR OTHER LEGAL ENTITY THAT WISHES TO USE THE FACEBOOK PLATFORM, THAT ENTITY) TO THIS AGREEMENT. IF YOU DO NOT AGREE TO THESE TERMS AND CONDITIONS, YOU MAY NOT USE THE FACEBOOK PLATFORM".
In this first version we found 7619 words (stop words included) in 235 sentences. Discounting the stop words, between the most frequent words emerge any elements related to legal and juridical assumptions, such as "agreement" ; "properties"; "rights" and "terms".
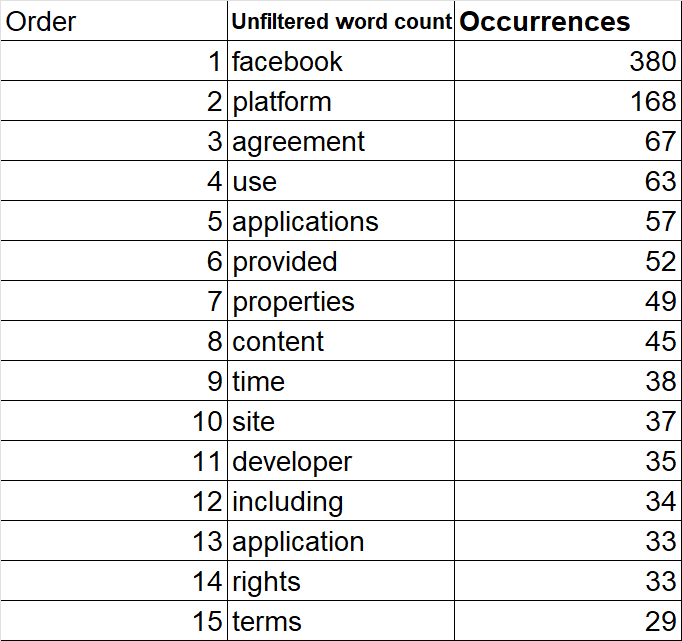
Table 1. 15 most frequent words in 1st version of the Facebook ToS (1 June 2007)
Between June 2007 and April 2010, Facebook updated their Developer ToS four times. The fifth change sees a change in title from "Developer Terms of Service " to "Developer Principles and Policies". This version counts 2606 words and 141 sentences. In this document, there is increased focus on expectations of access based on user expectations and privacy assumptions, typified in the regular appearance of phrases such as "you will not use Facebook if you are" ; "you will make it easy for users to"; "how to report claims of intellectual property infringement". From this version on, there appears to be a marked shift in this direction. As shown in Table 2, among the most frequent words were: "application"; "data"; "users"; "use"; and "content".

Table 2. 15 most frequent words in 5th version of the Facebook ToS (21 April 2010)
In the next three years, there were 15 updates to the ToS versions, including a change in the title from "Developer Principles and Policies"to "Facebook Platform Policies". Analyzing the documents revealed a discursive shift towards interest in giving "people the power to share and make the world more open and connected" and based on the following principles:
· Create a great user experience
· Build social and engaging application
· Give users choice and control
· Help users share expressive and relevant content
· Be trustworthy
· Respect privacy
· Don't mislead, confuse, defraud, or surprise users
· Don't spam - encourage authentic communications"
The 22nd revision of ToS, updated in 2018, features an increase in the length of the document compared to the previous 10 versions (6963 words and 500 sentences). The most recent major Facebook Platform ToS revision was in 2019, which saw a reduction in length to 4056 words and 168 sentences.

Table 3. 15 most frequent words in 23rd version of the Facebook ToS (25 April 2019)
The final stage of analysis deployed a network analysis using the Hyphe web crawler (Jacomy et al. 2016) to shed light on the connections between the Facebook developer and researcher environments. Two pages were crawled, which revealed 159 connected domains. The network graph (see Figure 5) shows three specific clusters. The first cluster we labeled "Doing research" and related to the web environment of "research.facebook.com" that is connected by "facebook.com" and "facebook/career" to the second cluster ("Accessing data") where "developers.facebook.com" becomes central. Finally, further crawls show the multiple domains that implicate both researchers and developers in a cluster labeled "Sharing knowledge".

Figure 5. Facebook developer and research networks. Non-Directional Graph from Hyphe. Crawled domains in black, discovered domains in light blue.
5. Discussion
Analysis of multiple platforms has several advantages, offering insight into how platform governance and access regimes shape each other across platform environments, as well as drawing out key differences. Across all platforms, we can see there has been a significant increase in the length and linguistic complexity of such documents, as indicated by our word counts and readability scores of different streams of developer ToS and policy documents. While there has been a general trend towards more restrictive access conditions for researchers across multiple platform environments, pointing simply to increasing restrictions to researcher access over the past 15 years is too simplistic. Rather, researchers are but one group of API users that have different relationships to various platforms. Access regimes for researchers shape, and are shaped by, the actions and demands of other groups that seek access or are sought out by platforms with the promise of access to platform data. As such, there is a need to study how access unfolds at multiple scales and its differential impact on different groups (and different types of research).
With our network analysis on Hyphe, we found some interesting differences between platforms in how researchers are positioned in relation to other API users and audiences platforms seek to target. While YouTube shows mostly outlinks to the wider development community, there is little evidence of focus on either research or interest in redirecting users to internal domains and tools. Twitter, by contrast, shows a vibrant yet self-contained developer network that links extensively within Twitter's own domain. Facebook demonstrated the most distinct network clusters, showing a highly insular network that links to several unique areas of its site, including an entire internal domain devoted to research.
Our diffstream analysis allowed us to trace the steady updating of policy documents over time, and identify several significant rewrites for each. We conclude that these are living agreements and that researcher access is contingent on a complex array of technical, legal, political, and economic shifts that are constantly being (re)negotiated. One test we ran was a search for the word "audit" within policy documents, which showed that, across all three platforms, the term displayed a distinct rise in use after 2020. "Compliance" and "sell," by contrast, exhibit use from the early days of the terms of service, though the frequency of compliance has risen mildly. In these documents we can—as Tarleton Gillespie (2018:15) suggests—"see the scars of past challenges", as major controversies and scandals interact with changes to organizational arrangements and reorientations, as platforms seek to retain their market dominance amidst increasing scrutiny and efforts to regulate.
Contrasts can be made between different platform environments in how researchers are positioned in wider logics of data governance. For example, in the case of Twitter, we registered a steady shift in how research is seen, from being invisible (until 2014), to a source of potential risk (2014-2020), to an instrumental user group called upon to resolve problems relating to the platform (2020-current). Meanwhile, in the case of YouTube, researchers are seen as what we describe as an "afterthought'', closest to the pre-2014 position of how Twitter related to researchers. Finally, Facebook has always seen (external) research as a risk to be managed, as well as being distinctive to other platforms through their large stable of in-house researchers, including a group of Computational Social Science researchers.
6. Conclusion
On a broad level, the main outcome of this subproject concerns the important differences between the three platforms under investigation. Twitter has come to see external research as an instrument to help develop their service: "we support research that helps improve conversational health on Twitter", the current ToS state rather unambiguously. The prominence of research on the larger web presence and the newly introduced—and rather generous—academic track confirm this impression. Facebook sees external research as a concession that is not mentioned in the ToS at all and not implemented as a specific "track" within the scope of the developer API. Instead, external research is relegated to a number of rather limited and heavily controlled access schemes and hardly prominent within the larger research cluster on the web presence, which mainly highlights Facebook’s internal research and employment opportunities. For YouTube, external research appears as an afterthought. There are no specific provisions, neither in the ToS, nor in the wider developer documentation. At the same time, however, the developer API allows for considerable leeway when it comes to data availability and although free access quotas have been reduced considerably over the years, the company does not actively thwart research into its platform.
These findings resonate with the work from the other two subgroups in this project, for example when it comes to the high popularity of Twitter in academic research - as the most accommodating platform it is simply easier to study than the other two. Further research is needed, however, to put company declarations - whether formulated as ToS or less formally through a broader presentation on the web - in relation to company practices, this is, with the ways they actually handle things like access decisions, blocking, or even legal action against inconvenient scholarship. Given the complexities of changing modalities and temporalities of data access, there is a need for research to consider not just major controversies and scandals in social media data access regimes (Bruns 2019), but also incremental changes over time, and how technical and legal regimes for governing access mutually shape each other and the implications for "platform observability" (Rieder & Hofmann 2020). A focus on a "post-API age" (Tromble 2021; Perriam et al 2020) overlooks continuities as well as disjunctures in data access regimes, and how existing technical and legal regimes are built on top of, and steadily reorient, existing arrangements.
7. References
Bucher, T. (2013). Objects of Intense Feeling: The Case of the Twitter API. Computational Culture, 3. http://computationalculture.net/objects-of-intense-feeling-the-case-of-the-twitter-api/
Burgess, J., & Baym, N. K. (2020). Twitter: A Biography. NYU Press.
Fiesler, C., Lampe, C., & Bruckman A.S. (2016). Reality and Perception of Copyright Terms of Service for Online Content Creation. CSCW ‘16, February 27-March 02, 2016, San Francisco, CA, USA.
Gillespie, T. (2010). The politics of ‘platforms’. New media & society, 12(3), 347-364. https://doi.org/10.1177/1461444809342738
Gillespie, T. (2018). Regulation of and by Platforms. In J. Burgess, A. Marwick, & T. Poell, The SAGE Handbook of Social Media (pp. 254–278). SAGE. https://doi.org/10.4135/9781473984066.n15
Jacomy, M., Girard, P., Ooghe-Tabanou, B., & Venturini, T. (2016, March). Hyphe, a curation-oriented approach to web crawling for the social sciences. In Tenth International AAAI Conference on Web and Social Media. https://www.aaai.org/ocs/index.php/ICWSM/ICWSM16/paper/viewPaper/13051
Jensen, C. & Potts, C. (2004). Privacy Policies as Decision-Making Tools: An Evaluation of Online Privacy Notices. CHI 2004, April 24–29, 2004, Vienna, Austria
Luger E., Moran S., Rodden T., (2013) Consent for All: Revealing the Hidden Complexity of Terms and Conditions, In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI '13). Association for Computing Machinery, New York, NY, USA, 2687–2696. DOI:https://doi.org/10.1145/2470654.2481371.
Perriam, J., Birkbak, A., & Freeman, A. (2020). Digital methods in a post-API environment. International Journal of Social Research Methodology, 23(3), 277-290.
Rieder, B., & Hofmann, J. (2020). Towards platform observability. Internet Policy Review, 9(4), 1-28. http://dx.doi.org/10.14763/2020.4.1535
Rogers, R. (2018). Social media research after the fake news debacle. Partecipazione e Conflitto, 11, 2035–6609. https://doi.org/10.1285/i20356609v11i2p557
Tromble, R. (2021). Where have all the data gone? A critical reflection on academic digital research in the post-API age. Social Media+ Society, 7(1), https://doi.org/10.1177/2056305121988929
Ideas, requests, problems regarding Foswiki? Send feedback