Mapping regimes of data access: A bibliometric overview of platform prominence in academic research
Team Members
Stijn Peeters, Victor Loye
Summary of Key Findings
-
After approximately 2015, Twitter is very clearly the most important source of data for academic research from the three platforms we study.
-
The trend towards Twitter started before the 'APIcalypse' following the Cambridge Analytica scandal in 2018.
-
Alongside the shift from Facebook to Twitter, we also observe a shift from media and communication studies initially to computer science and related fields more recently
1. Introduction
Academic research increasingly often uses data sourced from social media platforms to study societal or subcultural trends, a process that has also been dubbed a 'computational turn' (Berry, 2011). This is an attractive approach because it does not require researchers to, for example, set up surveys or do interviews; instead, they can get their data seemingly pre-packaged on request. While it is rarely so simple in practice (see e.g. Bucher 2013) - and indeed the question has been raised if the proliferation of this kind of research does not come at the cost of data quality (Rieder et al., forthcoming; Van Es et al., 2012) - social media nevertheless remains attractive as a place to do semi-automatic 'fieldwork'.
However, the umbrella term 'social media' covers many distinct platforms which all have different users, affordances, features, modes of interaction and access regimes (Gillespie 2018). In other words, it matters what platform is chosen as the source of research data; any choice of platform comes with implicit biases towards particular modalities of communication while precluding others. This conundrum can be addressed, at least partially, with a cross-platform analysis, where a certain phenomenon is studied across different platforms and data is sourced from multiple sites (see e.g. De Zeeuw et al. 2020). This nevertheless comes with its own issues, as owing to the aforementioned differences between platforms, data is not always readily comparable.
Much work therefore sources data from a specific platform. Usually, this data is then acquired via the platform's API (Application Programming Interface), which can be queried systematically to retrieve e.g. posts or comments within a specific set of parameters. As doing so requires some programming skill, many tools exist that act as a (relatively) user-friendly middle-man between the researcher and the platform, offering a graphical interface that allows one to set parameters after which data is acquired and saved in some standard format (e.g. a csv file; see for example Borra & Rieder, 2013; Peeters & Hagen, in press).
While this approach is broadly similar for all platforms, they differ significantly in how easy this process is, and to what extent the platform's API affords academic research. Facebook famously had a relatively expansive and open API initially, but removed or limited many of its features that were useful to researchers around the Cambridge Analytica scandal in 2018, in which it became apparent that these features had also been used to collect user data for the purpose of marketing and political campaigning, the effects of which have been called an 'APIcalypse' for research (Bruns, 2018). Sometimes a platform makes specific allowances for academic research, as in the case of Twitter which in 2020 opened a special 'academic track' of its API that offered many of the features missing from the 'standard track' that were nevertheless important for academic research, such as being able to collect historical tweets.
In summary, most platforms offer some sort of standardised access to their data in the form of an API, but the limitations of this access vary wildly, between platforms but also within a single platform over time. One may hypothesise that this has an impact on aforementioned research, which relies on data collected through these APIs for its analyses. It can be expected that as one platform limits access and another one affords it more substantively, researchers might source their data from the 'platform of least resistance'.
This can be problematic, as platforms are not interchangeable; as discussed, even a simple comparison between data about the same topic for different platforms is complicated. Additionally, Facebook (for example) has different demographics than Twitter, and 'what Twitter says' about something may well be coming from a very different group of people than 'what Facebook says'. Changes in access to a platform's API may thus have real effects on the topics and themes academic research relying on platform data is able to effectively cover.
In this paper, we therefore investigate whether indeed particular platforms are over-represented in academic research, whether this changes over time, and whether these changes can be correlated with changes in access regimes for a given platform. We focus on what are arguably the three largest platforms in the Western world, all three of them offering a robust API; Facebook, YouTube and Twitter. In the next sections, we first explain our method; then we discuss our review of the relevant literature and what platforms are prevalent as academic data sources; and finally, we discuss the implications of our findings.
2. Method
Our method can be characterised as a systematic bibliometric analysis. We query Scopus, a database of academic publications, for research that uses data from the Facebook, YouTube or Twitter API, or relies on it in some other substantial way. In other words, we are looking for work that would be impacted by changes to these APIs, because it relies on them in some way. These results can then be grouped per year, to produce an impression of how prominent the respective platforms are at different moments in time.
While academic databases such as Scopus are often used for similar analysis (see e.g. Özkula et al. 2022; Kang & Beomul 2014), they are not a perfect representation of the body of work that relies on these APIs. Many, but not all journals are indexed by Scopus, and indexing may lag behind publication, which can mean that especially recent work or papers in less prominent journals are not included. Nevertheless, the database offers a decent impression of the work in this area, even if it is not fully complete.
Our query for Scopus was intended to find work that refers to the Facebook, YouTube or Twitter's API directly, or refers to a research tool that in turn queries these APIs (which would still make the work reliant on access to them). We elected to exclude book chapters from the results (75 excluded results in our final query), because these are often difficult to acquire, and hence could not be checked to verify the accuracy of the query. We furthermore limited the query to only search for works within computer science, communication studies, social sciences, "business, management and accounting", and "engineering" (this latter category mostly comprises software engineering). Including more than these fields lead to a sharp increase in false positives. We verified the results of the query by manually coding a 10% sample of the results for relevance. The final iteration of the query (Figure 1) returned 1,565 documents published between 2008 and 2022 and was coded as 92% accurate. While more finetuning could produce a yet more accurate query, this nevertheless indicates that the results can be used as a representation of the body of work we seek to analyse.
| "twitter api" OR "facebook api" OR "youtube api" OR "dmi-tcat" OR "youtube data tools" OR netvizz OR facepager OR twapperkeeper OR yourtwapperkeeper OR twitterscraper OR twint OR 140kit OR rfacebook AND ( LIMIT-TO ( SUBJAREA , "COMP" ) OR LIMIT-TO ( SUBJAREA , "SOCI" ) OR LIMIT-TO ( SUBJAREA , "BUSI" ) OR LIMIT-TO ( SUBJAREA , "ENGI" ) ) AND ( EXCLUDE ( DOCTYPE , "ch" ) ) |
Figure 1. The final Scopus query
Results were exported via Scopus' web interface and then semi-automatically coded as depending on a particular platform's data based on whether the platform name was mentioned in the abstract (i.e. works could be categorised for multiple platforms if they mention multiple). This annotated data was then converted to a network in order to analyse the high-level topology of this discourse and render visible pronounced shifts in terms of quantity or focal points of the corpus. The network here was a bipartite network that connects nodes representing works from the corpus to nodes representing the keywords Scopus had indexed these works with. For example, a work might be connected to the nodes 'facebook', 'activism' and 'sentiment analysis'.
Using the time series feature of network visualisation tool Gephi (Bastian et al. 212), we were then able to capture the evolution of our network through time, as Scopus’ metadata included the year of publication. To make visible the shift in academic production we were looking for, we highlighted the nodes for the keywords best representing our platforms of choice ('Facebook', 'YouTube' and 'Twitter') as well as two keywords strongly connected to specific fields: computer science ('data mining') and social and media studies ('social relationships'). Finally, to clean up the network and remove less connected keywords, only keywords used for at least three different works were retained.
3. Findings
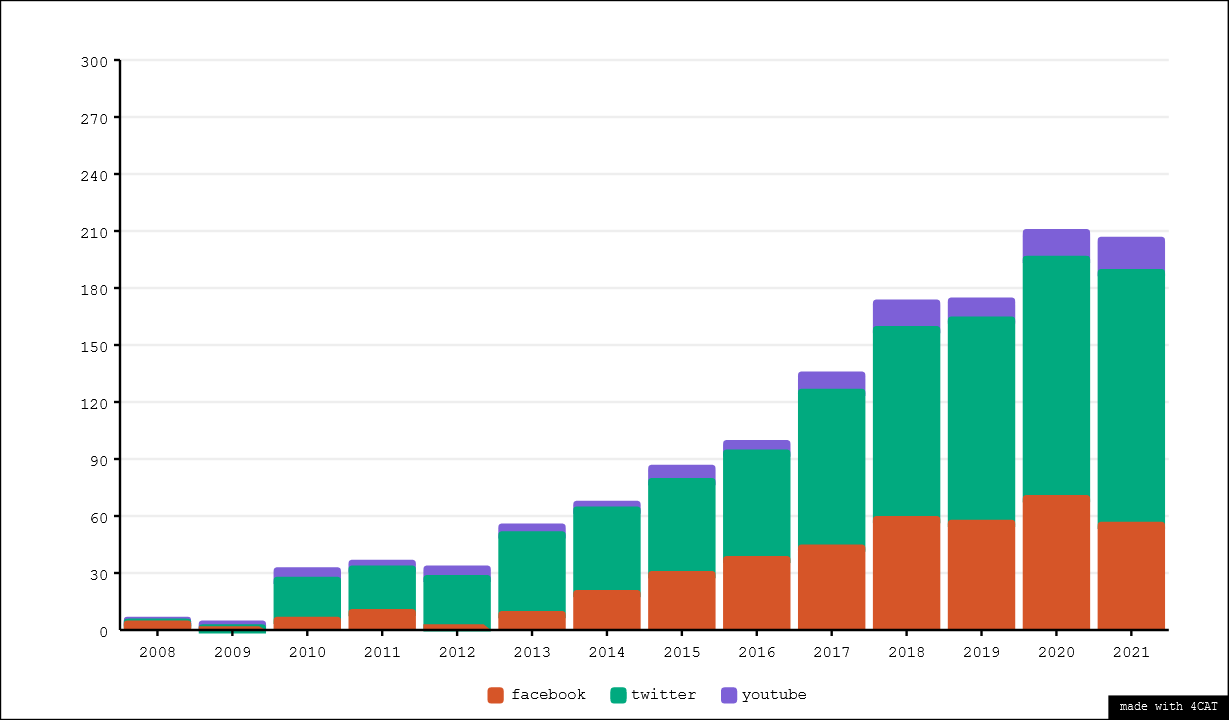
The result of categorising the corpus by platform can be found in Figure 2, visualised over time. As can be readily observed, the amount of works per year that deal with the API of any of our three platforms rises steadily over the years. Notable here is however that the amount of works relying on Twitter's API increases faster than the amount of works relying on the other two platforms, which can be interpreted as Twitter being a more and more popular source of data for research. Facebook represents roughly half as much work as Twitter, with YouTube occupying a distant third place.
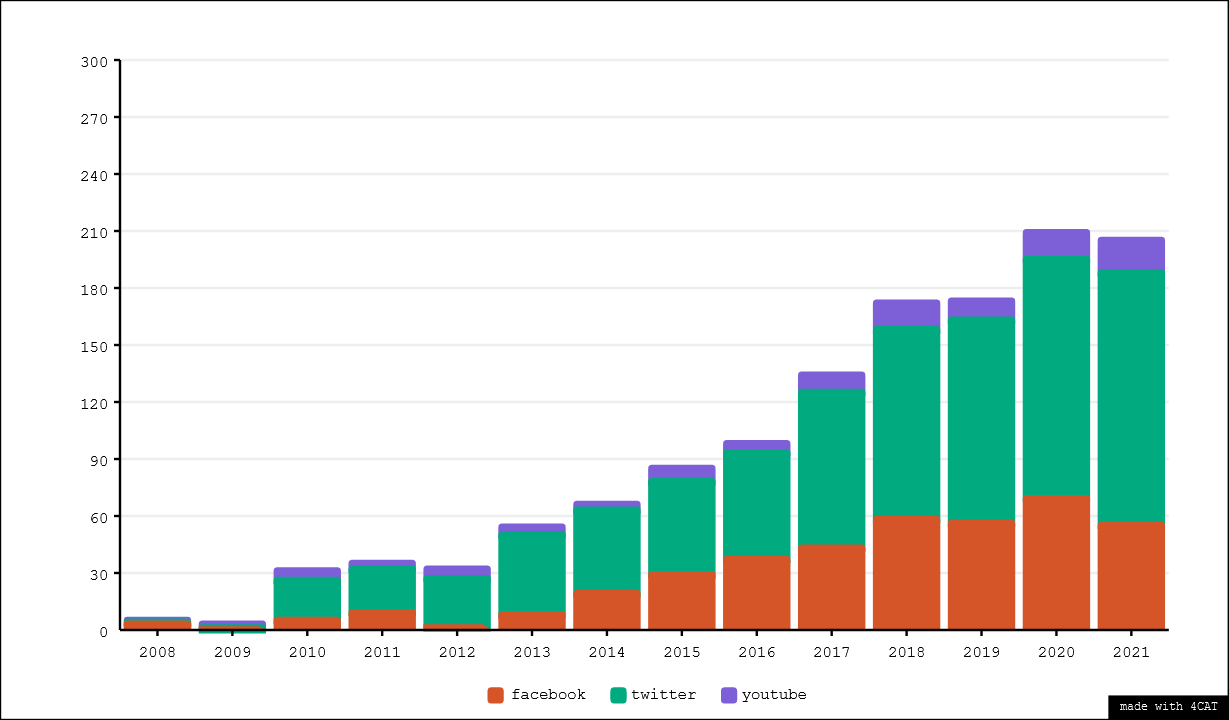
Figure 2. Scopus results per year, by platform(s) referenced in their abstract
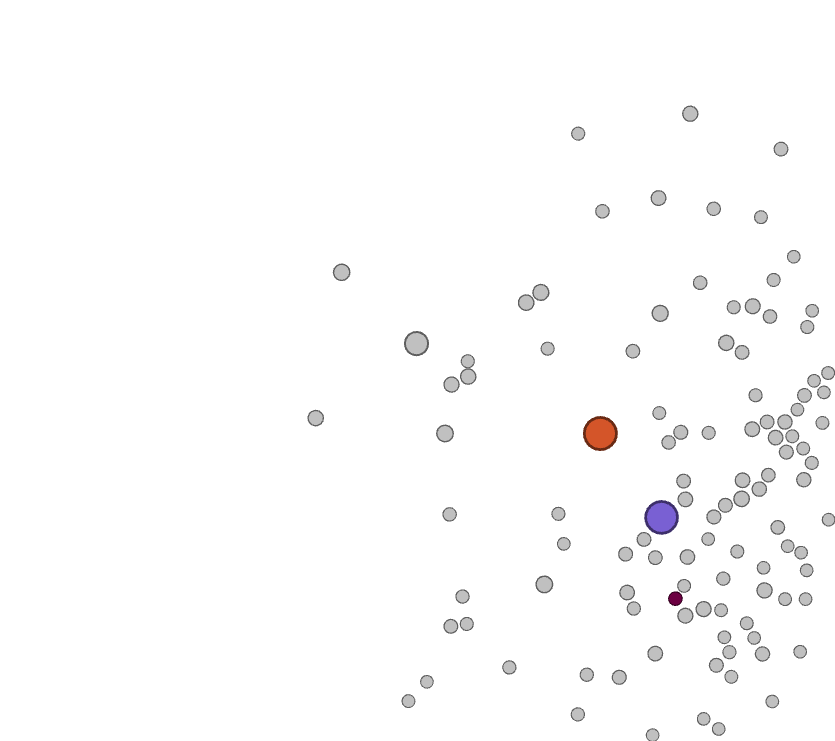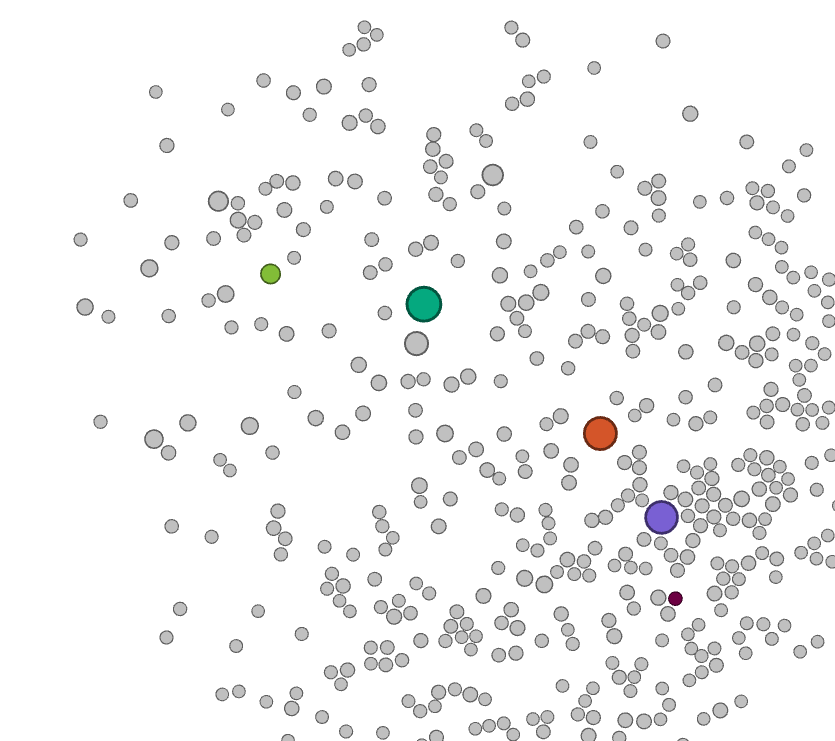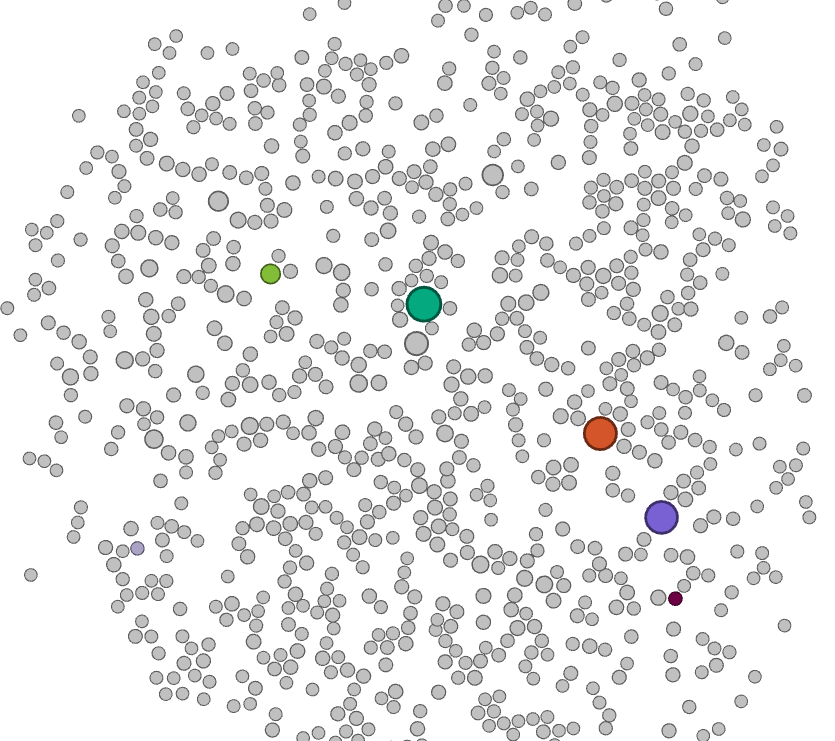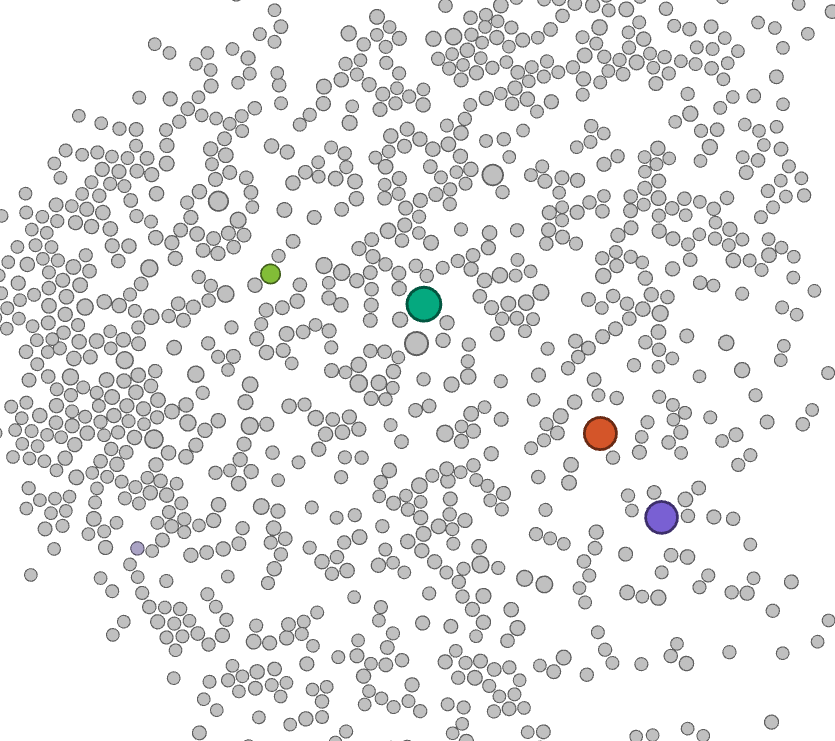
A network analysis of the bipartite work-keyword graph (Figure 3) reveals that this platform shift is accompanied with a clear disciplinary shift. Whereas initially most works are associated with keywords related to social sciences and humanities - displayed in the bottom right in Figure 3, with the keyword 'social relationships' highlighted - in later years works are more strongly associated with keywords that can be associated with disciplines such as computer science, as illustrated by the highlighted node 'data mining' in Figure 3.
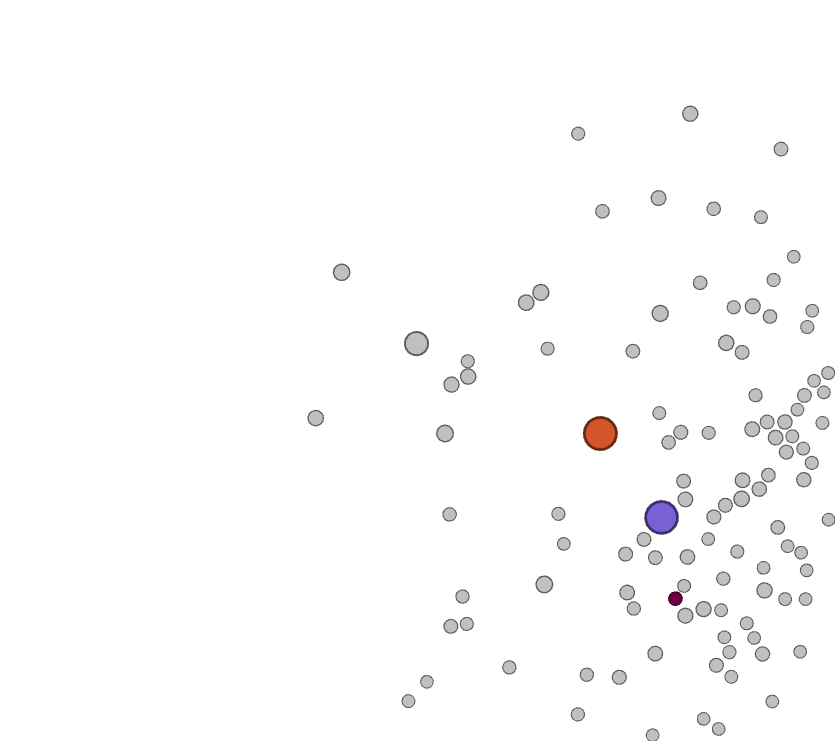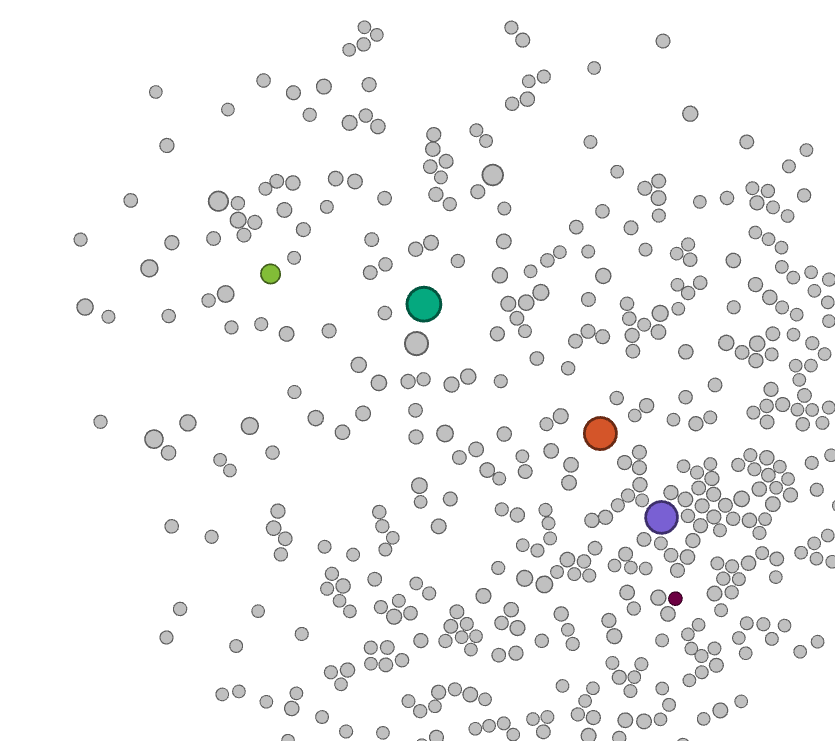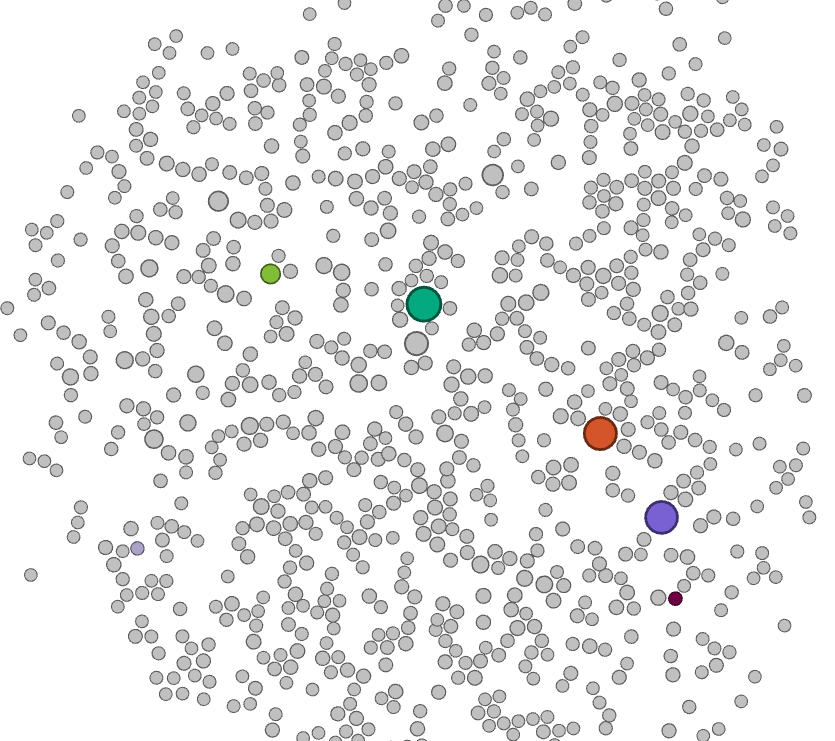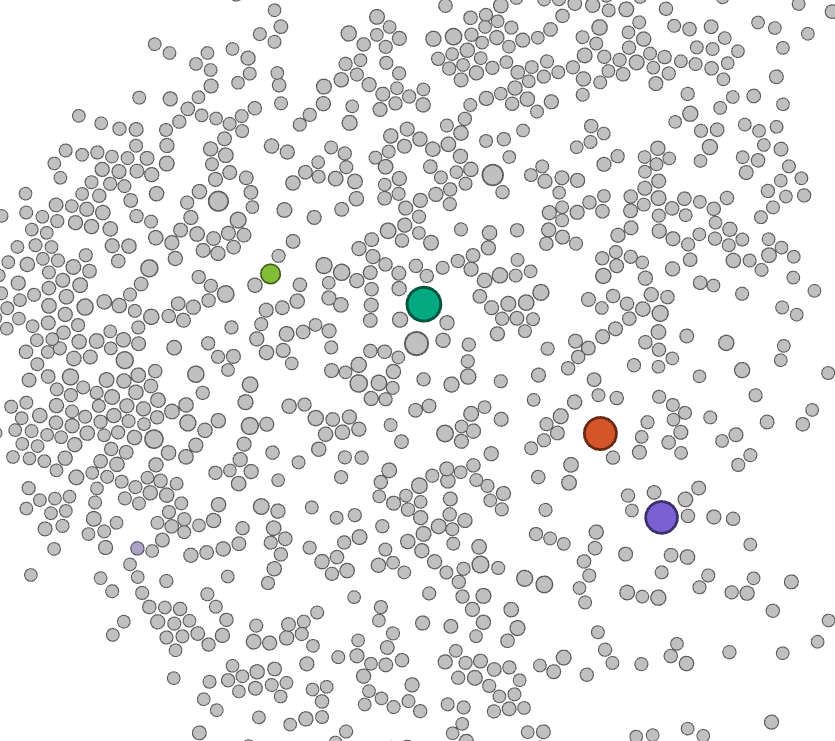

Figure 3. Animated visualisation of a bipartite network, visualised with the ForceAtlas 2 layout, of keywords and papers. Five keywords are highlighted - three large nodes represent the three platforms of interest, two smaller nodes represent the approximate centres of a disciplinary keyword cluster around computer sciences and communication/media studies respectively. Each snapshot represents approximately two years of data.
Overall, we observe in our corpus a clear increase in data access related knowledge production over the last 15 years. This progression is particularly shown in Twitter-related work. Conversely YouTube seems to be a relatively under-studied platform while activity around Facebook is the most unstable and fluctuating of the three.
In addition, as shown by the animation in figure 3, while work dealing with these APIs was spearheaded by the fields of media and communication studies initially, more recently the exact sciences and in particular computer sciences have provided the bulk of activity in this area. A cursory investigation of the works from our corpus that fall within this category indicates that much of this can be attributed to the use of social media data as a case study or verification of various classification algorithms, for example for sentiment analysis or machine learning-based approaches to political categorisation.
4. Discussion & Conclusion
This preliminary research corroborates our findings from the other subgroups of this project. Namely, that Twitter sees API-based research as an instrument, while Facebook and YouTube respectively see it as a concession or an afterthought, is clearly apparent in our corpus. Indeed, Twitter’s active engagement with researchers and licensed access to its data makes it a very enticing platform to work on, which is a plausible explanation for its over-representation in our corpus. Its recent announcement of a special 'academic track' of API access does not seem to have had a direct effect on the amount of work that uses Twitter data; this could be because existing access was 'good enough' and the effect of this change to the platform's access regime can be found in a changed quality of work rather than an increase in the quantity of work. A more fine-grained classification of the corpus could potentially reveal such nuances.
YouTube, on the other hand, while not clearly engaging directly with researchers, also makes little attempt to actively prevent academic research and provides a relatively feature-rich API. A possible explanation for the relatively small body of work that sources its data from this platform could be that YouTube is an inherently audiovisual medium. While one can analyse its text content and metadata as well (and indeed many authors have done so; see e.g. Rieder et al. 2020; Thelwall 2017) its main form of content remains video, which is more challenging to analyse than text or still images. From this perspective, other, more text-based platforms offer a lower methodological barrier to entry, which can explain why they are more attractive to researchers.
Finally, though Twitter is clearly the more prominent platform, Facebook is still very much studied, despite the “APIcalypse” fears following the Cambridge Analytica scandal (Bruns 2018). This scandal, which has triggered Facebook to restrict the data available from its’ API to limited availability publicly accessible content (public pages and groups), might have shifted the nature (and methods) of the research done on this platform but did not fully deter academics from engaging with it, and there remains a stable (but fluctuating) undercurrent of research activity that sources its data from Facebook. In fact, Twitter started outpacing Facebook well before the Cambridge Analytica scandal, and the explanation of the difference in popularity should therefore be found elsewhere.
An interesting prospect for future analysis could be to map more precisely the way data from these platforms is accessed, where one might see a shift for Facebook from direct usage of its APIs to a more prominent role of services like the Facebook-owned CrowdTangle, which act as an intermediary for data access. Such an analysis could offer an explanation for the observed trend and lack of clear 'tipping points', and may reveal such tipping points that do exist in terms of the more specific methodological approach to social media data analysis.
Overall, this initial bibliometric analysis suggested that changing regimes of access do not have a strong direct impact on what platforms researchers acquire their data from, though one platform (Twitter) is clearly more prominent than one might expect based on e.g. its number of users. It does reveal a clear shift over time, from Twitter to Facebook, and communication & media studies to computer sciences as the centres of gravity. It furthermore suggests a more specific analysis of the results may reveal more specific methodological shifts, which would be a useful avenue for further work in this area.
5. References
Bastian, M., Heymann, S., & Jacomy, M. (2009). Gephi: An Open Source Software for Exploring and Manipulating Networks. Third International AAAI Conference on Weblogs and Social Media, 361–362.
Berry, D. (2011). The computational turn: Thinking about the digital humanities. Culture Machine, 12.
Borra, E., & Rieder, B. (2014). Programmed method: Developing a toolset for capturing and analyzing tweets. Aslib Journal of Information Management. (world). https://doi.org/10.1108/AJIM-09-2013-0094
Bruns, A. (2019). After the ‘APIcalypse’: Social media platforms and their fight against critical scholarly research. Information, Communication & Society, 22(11), 1544–1566. https://doi.org/10.1080/1369118X.2019.1637447
Es, K. van, Wieringa, M., & Schäfer, M. T. (2018). Tool Criticism: From Digital Methods to Digital Methodology. Proceedings of the 2nd International Conference on Web Studies - WS.2 2018, 24–27. Paris, France: ACM Press. https://doi.org/10.1145/3240431.3240436
Gillespie, T. (2018). Regulation of and by Platforms. In The SAGE Handbook of Social Media (pp. 254–278). 55 City Road: SAGE Publications Ltd. https://doi.org/10.4135/9781473984066
Kang, B., & Lee, J. Y. (2014). A Bibliometric Analysis on Twitter Research. Journal of the Korean Society for information Management, 31(3), 293–311. https://doi.org/10.3743/KOSIM.2014.31.3.293
Özkula, S. M., Reilly, P. J., & Hayes, J. (2022). Easy data, same old platforms? A systematic review of digital activism methodologies. Information, Communication & Society. (world). Retrieved from https://www.tandfonline.com/doi/abs/10.1080/1369118X.2021.2013918
Peeters, S., & Hagen, S. (In press). The 4CAT Capture and Analysis Toolkit: A Modular Tool for Transparent and Traceable Social Media Research. Computational Communication Research. https://doi.org/10.2139/ssrn.3914892
Rieder, B., Peeters, S., & Borra, E. (Forthcoming). From Tool to Tool-Making: Reflections on Authorship in Social Media Research Software. Convergence.
Zeeuw, D. de, Hagen, S., Peeters, S., & Jokubauskaite, E. (2020). Tracing normiefication: A cross-platform analysis of the QAnon conspiracy theory. First Monday, 25(11). https://doi.org/10.5210/fm.v25i11.10643

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Figure2.png | manage | 21 K | 01 Feb 2022 - 17:52 | StijnPeeters | |
| |
Figure3a.gif | manage | 288 K | 01 Feb 2022 - 17:56 | StijnPeeters | |
| |
Figure3b.png | manage | 4 K | 01 Feb 2022 - 17:56 | StijnPeeters |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback