Greenwashing, in_authenticity & protest.*
Following the dynamics and relations of an ambiguous term on Twitter and the Web
*Additional data and figures with a higher resolution can be accessed through GitHub.
Team Members
Stefan Laser (facilitator), Xinyue Chen, Maria Lompe, Suay Melisa Ozkula, Estrid Sørensen, Lena Teigeler, Mariangela Vespa, Tianshi Zhao. Designers: Matteo Bettini, Valentina Pallacci, Fabiola Papini, Marìa Paula Vargas Triana.Contents
Summary of Key Findings
-
Greenwashing is now an established term in the digital public sphere. Studying claims of greenwashing – e.g., when companies are criticized – offers a compelling case study of inauthentic activities due to its ambiguous form and content.
-
There are popular targets, common sentiments and established routines of greenwashing accusation, yet there is plenty of room for interpretation, diversion, turnarounds and surprises. Calling out greenwashing is a way to establish a critical account and call for accountability. However, one key problem is that the discourse quickly lapses into superficial truth-politics and prefabricated critique patterns.
-
URL sources and contents (i.e. materials/evidence) on “greenwashing” are by and large (successfully) targeted towards progressive movement actors. Marginalised discourses (such that could be related to potential anti-programmes) were not found. Even so, significant differences existed based on the platforms where these URLs have shown high engagement.
-
Cross-platform analyses of Greenwashing claims illuminate different cultures of Greenwashing. The approach of a research endeavour (e.g., user focus vs evidence focus; single-platform vs cross-platform) significantly influences how Greenwashing is understood, enacted, and mobilised.
General Introduction
There is a new global interest in ecological, so-called green transformation through infrastructural reform and investment. Take the example of a “Green New Deal” as discussed in the US or EU, and the “Belt and Road” initiative in China. Such reforms are public matters of concern, tied to national and transnational initiatives and shaped by propositions of various interest groups. Among the crucial groups are activists, non-governmental institutions and engaged scientists. Such initiatives are intended to give companies new vitality, all under the umbrella of sustainability. This provides anchor points for global controversies such as those gathering around climate change (cf. climaps.eu). At the centre of the issue space are capitalist corporations and state initiatives responsible for mining and production systems. Our project examines a particular mode by which corporate and state actors are scrutinised and held accountable for changes pursued or called upon. We discuss greenwashing claims: when actors are accused that their activities or reforms only seem sustainable and that corresponding measures are first and public relations efforts or insensitive to harmful consequences of industrial practices. Greenwashing accusations, we argue, play a significant role in shaping the public debate. They build on decades of systemic and cultural critique and add new avenues for intervention (Klein 2015), which actors mobilise in various ways. These claims impact negotiations on major “green” reforms and their role should be taken seriously.
However, the way greenwashing is uttered and then attached to actors may differ a lot, with a large grey area as to what is actually defined as a greenwashing problem and the consequences of an accusation. This ambiguity is further reinforced by the mediation of digital media. Social networks, newsfeeds and web resources in circulation add new dynamics to the discussion of greenwashing; indeed, in the nested relations and multiple temporalities of digital platforms, the phenomenon is produced in a particular way. Our project argues that Greenwashing claims offer a compelling case study for digital method advancement insofar as they demarcate an ambiguous issue space where the actors involved grapple with questions of inauthenticity in a unique way. In contrast to matters of toxicity, hate crimes, trolling, or bot intervention – albeit partially entangled with it – users and scholars alike need to check both the claim practices and oneself for their stance. At times, a greenwashing accusation feels inauthentic; it can sound annoying. Still, the normative classification is more difficult to establish than other topics treated under the theme of "fake everything." Our methods can learn from engaging with this ambiguity. Simultaneously, our project also speaks to the rich scholarly discourse about the phenomenon of greenwashing (claims) more generally (Gatti et al. 2019, de Freitas Netto et al. 2020). In this discussion, authenticity (especially looking through the lens of digital mediation) has not been systematically addressed.
Following an interpretative research approach, we want to understand what’s going on when people engage with Greenwashing. This project asks how greenwashing accusations are enacted in social media and the web, inquiring how actors manoeuvre authenticity issues. We divide our inquiry into two distinct projects that explore the themes of greenwashing, in_authenticity and protest in their own yet interlinked way. Group number 1 unravels Twitter events and their relations, with the keyword of Greenwashing as the main query. Group number 2 follows URL network dynamics and issue language across platforms, focusing on the most engaged with Greenwashing URLs on Facebook, Twitter and Reddit.
Group 1: Twitter activity on #Greenwashing
1.1. Group Members
Stefan Laser, Postdoctoral researcher, Siegen University, CRC Media of Cooperation
Lena Teigeler, PhD Student, Siegen University, CRC Transformation of the Popular
Xinyue Chen, Master Student, University of Science and Technology of China, Science Communication Center of Chinese Academy of Sciences
1.4. Introduction
Initial exploratory data analysis emphasised that Greenwashing has only been a major buzzword thrown around in digital discourses for a few years (Fig. 1). Now, however, it is a permanent feature. This insight runs counter to theories about the development of greenwashing claims in social media. In 2013, Lyon and Montgomery suggested that companies would be cautious with strong PR campaigns online and that users would therefore find less space to challenge them. However, we are not so much interested in an approximation or even a classification of certain problematic corporate social responsibility practices (there’s plenty of great work on this, e.g. Adi et al. 2018). We want to understand how users on Twitter understand and use greenwashing as a term and what dynamics characterise it. Thus, we argue against a substantial understanding of greenwashing and unravel the issue space through lived practices and relations.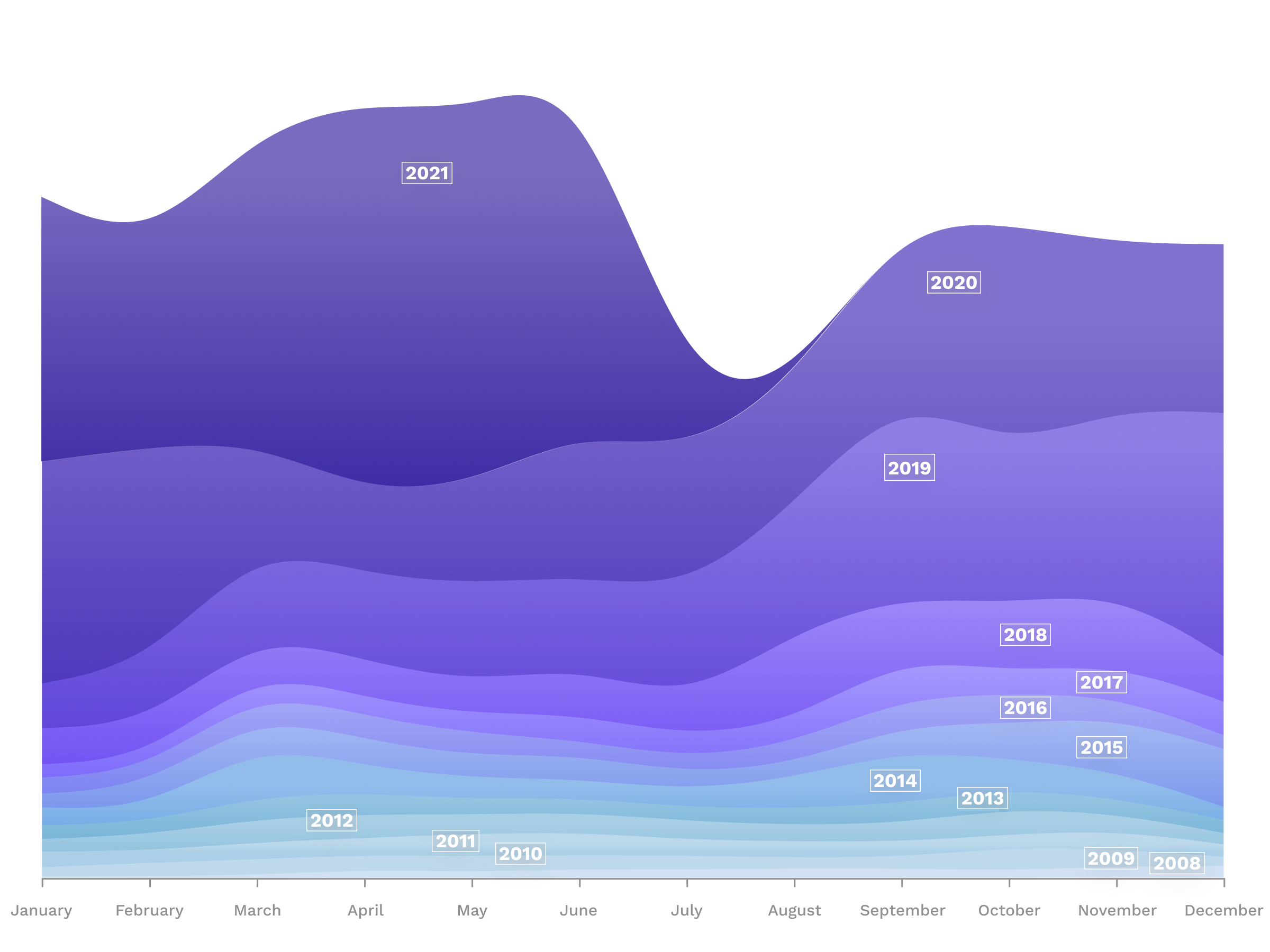 Fig. 1: “Greenwashing” on Twitter (count/day since 2008 and until mid-2021, stacked/year)
Fig. 1: “Greenwashing” on Twitter (count/day since 2008 and until mid-2021, stacked/year)
1.3. Research Questions
The project started out with the broad questions: When and how is “Greenwashing” mobilised? When and in which frequency is the term used? Who is participating in its usage and how do users refer to each other? Which events is the term attributed to? To what kind of discussions is the term attached? Initial observations then lead to a specification of research questions:
RQ#1: What makes a peak in the frequency of tweets containing ‘greenwashing’?
RQ#2: What are the semantics of greenwashing?
The first question resulted from the observation that greenwashing seems to be most frequently used in relation to specific events, like a french union strike or #Earthday. The second question aims at describing how authenticity is addressed within the Twitter discourse. We use both questions to get at the heart of greenwashing claim activities on Twitter.
1.4. Methodology
We followed “greenwashing” as an online discursive feature to reveal its distinct way of addressing the inauthentic. Our analysis was driven by a hermeneutical circle. Through statistical analysis and visualisations, we first gained a broad overview of key relations. We then used particular hints in social media data to discuss outstanding features of the dataset and qualitative differences. Finally, the differences were used to generate new questions about the shape of the dataset more generally.1.4.1. Initial Data Sets
The initial data set was retrieved via the Twitter APIv2 through academic researcher accesses with the help of the DMI toolkit 4CAT and the python script twarc(2). It consists of all tweets from 1 January 2014 until 7 July 2021 containing the word ‘greenwashing’ (greenwashing OR GREENWASHING OR Greenwashing OR #greenwashing OR #Greenwashing OR #GREENWASHING). This selection certainly doesn’t incorporate all forms of discourses around greenwashing (accusations) on Twitter, as users might use different wording to point at similar phenomena. Still, turning exclusively to tweets containing this word bears the potential to shed light on specific dynamics around accusations that describe a particular form of inauthentic behaviour precisely in one word. Through the query, our research thus centres on claims of Greenwashing. Fig. 2 summarizes the research protocol we thus followed. We also briefly worked with other data sets and explored certain sub-issues. Before any queries, members of the group explored the Twitter-sphere through manual search to test the topic’s relevance. And beyond the primary dataset, we also scraped the most relevant correlated hashtags, which gave us a broad (too broad) dataset of climate change discussion. Finally, querying certain company accounts (such as @shell or @DB-Bahn), we looked at how users mention particular accounts over time.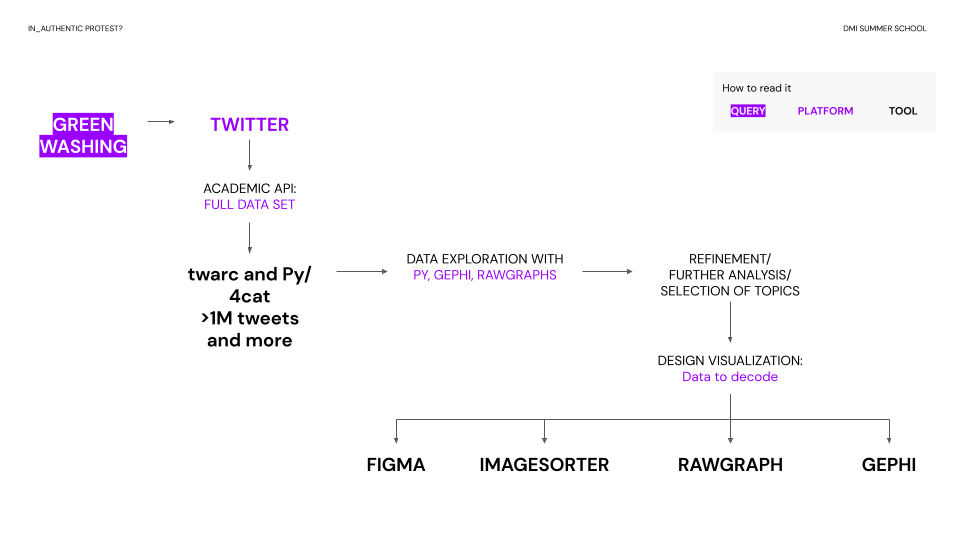 Fig. 2: Research protocol
During the project, the data sample was refined: As the usage of greenwashing on Twitter has increased since 2014, and 2021 appearing to be the year with the most tweets containing the term, we decided to focus on 30th June 2020 until 30th June 2021. Then, we selected three days out of this period to further zoom in and observe the dynamics taking place on these specific days. To compare possible cultural differences, we also introduce a Chinese case of consumers’ complaints about big companies' usage of paper straws which is regarded as a typical phenomenon of greenwashing in China. The reasoning for this selection is described below.
Fig. 2: Research protocol
During the project, the data sample was refined: As the usage of greenwashing on Twitter has increased since 2014, and 2021 appearing to be the year with the most tweets containing the term, we decided to focus on 30th June 2020 until 30th June 2021. Then, we selected three days out of this period to further zoom in and observe the dynamics taking place on these specific days. To compare possible cultural differences, we also introduce a Chinese case of consumers’ complaints about big companies' usage of paper straws which is regarded as a typical phenomenon of greenwashing in China. The reasoning for this selection is described below.
Publicly, we store only the Tweet IDs of the Tweets included in the data analysis. We do not keep full tweets due to restrictions in the Twitter terms of use. You can access the IDs and the Python code we used, plus also plots generated, through GitHub.
1.4.2. Event profiles
The data and meta-data provided by Twitter are plenty; what is required is a critical reflection of the wealth of metrics being supplied. We draw on Roger’s suggestion to reframe engagement through unravelling social issue networks. This requires following “(1) the specific actors that give voice to the issue with the greatest strength, (2) the issue areas or fields taking up the concern and those ignoring it, (3) the longevity or durability of actors’ concern, (4) its specific articulation as well as counter articulation, and (5) the set actors who specify the concern in the same manner but who may not be allies.” (Rogers 2018, 455) We tackle this research programme through the creation of “event profiles”: a combination of time series data, Gephi network visualisation, user and hashtag information ranked by popularity and engagement, and granular analysis of scattered drivers of spikes in activity. Our aim is to identify "events" and narrow down the data pool to individual days and their dynamics.
1.4.2. Topic modelling and keyword distribution
In order to approach the question of how authenticity is addressed within the Twitter discourse, we worked with a combination of quantitative (machine-learning-based) and qualitative approaches. Our dataset consisted of close to 1M tweets. How to get an understanding of the themes and words commonly used in this vast collection of text?
We started with topic-modelling (Latent Dirichlet Allocation) to map the themes the tweets assemble around (see the Jupyter notebook on GitHub). Topic modelling uses co-occurrences and calculates the probability of words appearing together. It reads documents as a larger collection of words and forces them into a fixed order. The same word may appear in multiple topics, although with different partners. Additionally, topic modelling gives a “weight” to each word for a topic, thus representing a hierarchy of terms for each topic. What we get as a result are clusters of words that are supposed to be related to each other. We looked closely at the results of models and the meaning of the assembled words to give each topic a name. Extensive data cleaning is the backdrop for the analysis. After multiple rounds of testing, we ended up focusing on English text only, removed the “greenwashing” word from the dataset (because it dominates every topic), while only using tokenized and lemmatized versions of words – the bare minimum, if you will.
We need to be careful with any interpretation of the topics discovered because the algorithm seems to load meaning with objectivity. It just makes a risky bet (the model itself calls for qualitative and quantitative evaluation, Chang et al. 2009). The very nature of what a “topic” actually implies in a particular context is up for discussion. Nonetheless, the approach allows us to work with large “bags” of text and approach the data with further qualitative questions. With its two directions – representing a corpus and predicting future text – it invites us to explore the performance of Greenwashing tweets. We also used topic modelling to conduct comparisons across our two groups, which helped us better understand platform-specific notions of Greenwashing.
Drawing on the topic modelling results, our Twitter group looked more closely at keywords. Time series visualisations for particular terms were created, while wordtree analysis got us closer to keywords and their contexts. We used the Python package "wordtree" by Will Chrichton, in contrast to the WordTree plugin used by Group2. Lower/upper case denote that difference between the code used.
1.5. Findings
1.5.1. Exploring the data set
Greenwashing is a popular term on Twitter, yet it is only popular for roughly half a decade (see above, Fig. 1). Looking at the users active in the discussion as represented in profile pictures (Fig. 3), a common pattern emerges throughout the past years: the share between individual user accounts (using headshots) and larger organisational accounts (using logos) stays constant.

Fig. 3: Twitter profile pictures accumulated and grouped via logo and people
The term Greenwashing isn’t used frequently every day, what stands out are “peaks” on particular dates (Fig. 4). Many tweets on these specific dates indicate the prevalence of certain events, such as a protest of Greenpeace France on #WorldEnergyEfficiencyDay.
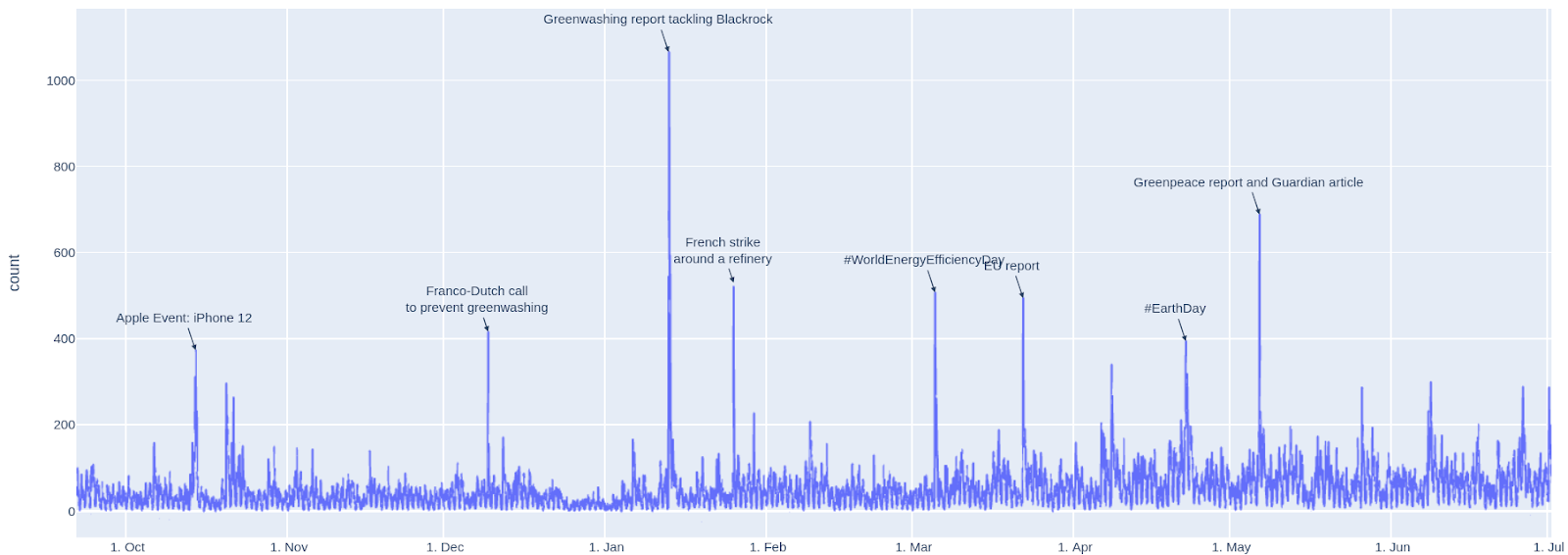
Fig. 4: “Greenwashing” on Twitter time series with qualitative annotations. The graph is created through the Python plotly package. It is an interactive graph that allows us to identify concrete hours of Twitter activity “peaks”. The interactive version is available as a download here.
The relationship between peaks and certain events appeared to be confirmed by a Gephi network analysis of authors and hashtags. While the five most used hashtags, #climateaction, #esg, #climatecrisis, #climatechange and #sustainability have been attached to different events and topics and have been used by various actors, some bigger hashtags have been used in tweets that refer to certain events. #grandpuits and #total were attached to tweets on a union strike around the French Total Grandpuits refinery in January or #eutaxonomy was used to criticise the taxonomy for sustainable activities. At the same time, #RWE or #Shell were attached to several different greenwashing accusations, most of them also event-driven.
The hypothesis that tweet activity on greenwashing is driven by specific events was then tested by zooming into three days, marking a peak in the overall frequency: 1) 13. January 2021: Most tweets most probably referred to the release of a report accusing Blackrock of greenwashing, 2) 25 January 2021, which we connected to a French union strike around the refinery Grandpuits, and 3) 5 March 2021, a peak presumably created by tweets referring to the Greenpeace France protest on #WorldEnergyEfficiencyDay.
1.5.2. What makes a peak? Towards Twitter event profiles
RQ#1, What makes a peak?, was investigated by exploring the data-set in different ways. In a first step, the relationship of authors and mentions was analysed with the help of a network visualisation created with Gephi.
Such a network visualisation shows how authors refer to each other and can hint at topical clusters and sub-clusters or conversations taking place between certain actors. With the help of Gephi, we further analysed the role of certain actors in a network, e.g. by calculating their betweenness centrality (=their property to connect different clusters in a network with each other). When re-connecting the network analysis to the original tweets, we’ve noticed that they don’t account for the whole data set as many tweets didn’t include any mentions. Hence, we didn’t keep on following that path.
Drawing on these observations from the network analysis, we created three profiles for the alleged events and their spikes. This helped us represent the differences identified through different angles. Relating the discussion to the larger dataset offers additional comparative leverage. We propose three different angles to represent profiles.
First, looking at basic tweet type statistics helps get a sense of the type of communications dominating an event (Fig. 5). As indicated above, we can thus clearly identify the particularity of the activity on the 13th of January, 2021.

Fig. 5: Tweet types throughout the events and compared with the entire dataset.
Second, the language distribution helps us get a sense of cultural specificities dominating a particular event. Greenwashing is a profoundly European theme, with networks centring around French, English, Spanish and German clusters and some theme and institution-based exceptions (notable around the EU). But looking closer at event languages shows how certain discussions are situated in very particular ways (Fig. 6). The retweet mentioned above in Thai stands out, as does the French strike.

Fig. 6: Top languages compared by events
Third, a quick glimpse at the share of verified/unverified accounts indicates the amount of larger institutions or well-known people of public interest being active in the discussions (Fig 7).

Fig. 7: The share of verified accounts active during the different events
1.5.3. Topics brought forward through the Greenwashing hashtag on Twitter
We classified the results from the most reliable topic model (k=5 topics) as follows: collective action (with words such as climate change, action, campaign), accountability (investment, fund, just), energy transition (energy, carbon, renewable), protest (destruction, accused, Greta Thunberg), and brands (fashion, palmoil, marketing). This representation of the main discussion points makes sense and resonates with what a regular news recipient from Europe might expect. Yet we propose one more qualitative twist. The topic modelling gave us complex lists with some dazzling overlaps depending on the number of topics chosen (from 3 to 100). For short texts, it’s pretty common that not all topics produced by the machine learning algorithm are coherent, and the five topics highlighted above also live through cross-references. We suggest that the language relevant for our research is either protest or truth driven. Topic modelling shows us that the discussion is aimed at systemic problems of capitalism and operates either in the language of capitalism (e.g., via accountability or energy transition) or against it (e.g., through protest mobilisation or brand-specific ad-busting). The machine learning approach has trouble operating with such different modes, even though it hints to follow certain words and metaphors. Here it is important to remember the analytical dependencies of topic modelling (see 1.4.2). What topics mean – and what the very notion of “topic” implies – requires interpretation. In this sense, we argue that the accounts do not talk about some prefixed themes. Rather, in the Greenwashing Twitter-sphere they talk through topics. Protest language is a mediator, while truth-specific language appears through all topics and attaches claims.
Drawing on the topics and keywords, we wanted to understand how topics unfolded through time. Fig. 8 looks at tweets from the summer of 2020 until 2021 to compare key themes representing protest or truth. We took the terms from the relatable terms throughout the topics. This representation emphasises that protest terms are more event-driven than others, while truth-based language is a constant feature of the Greenwashing tweet discourse (“fact” being skewed by one event). This resonates with the topic modelling. We then looked closer at the sentences used around “truth” – as displayed in wordtrees (Fig. 9). We found out that users are likely to attach Greenwashing in a particular pattern, mobilising singularised claims. In other words, it is the truth that is called for. It is here where actors introduce layers of redundancy to discussions. We will discuss this result in 1.7, but first, we will look at the evaluation of inauthentic activities.
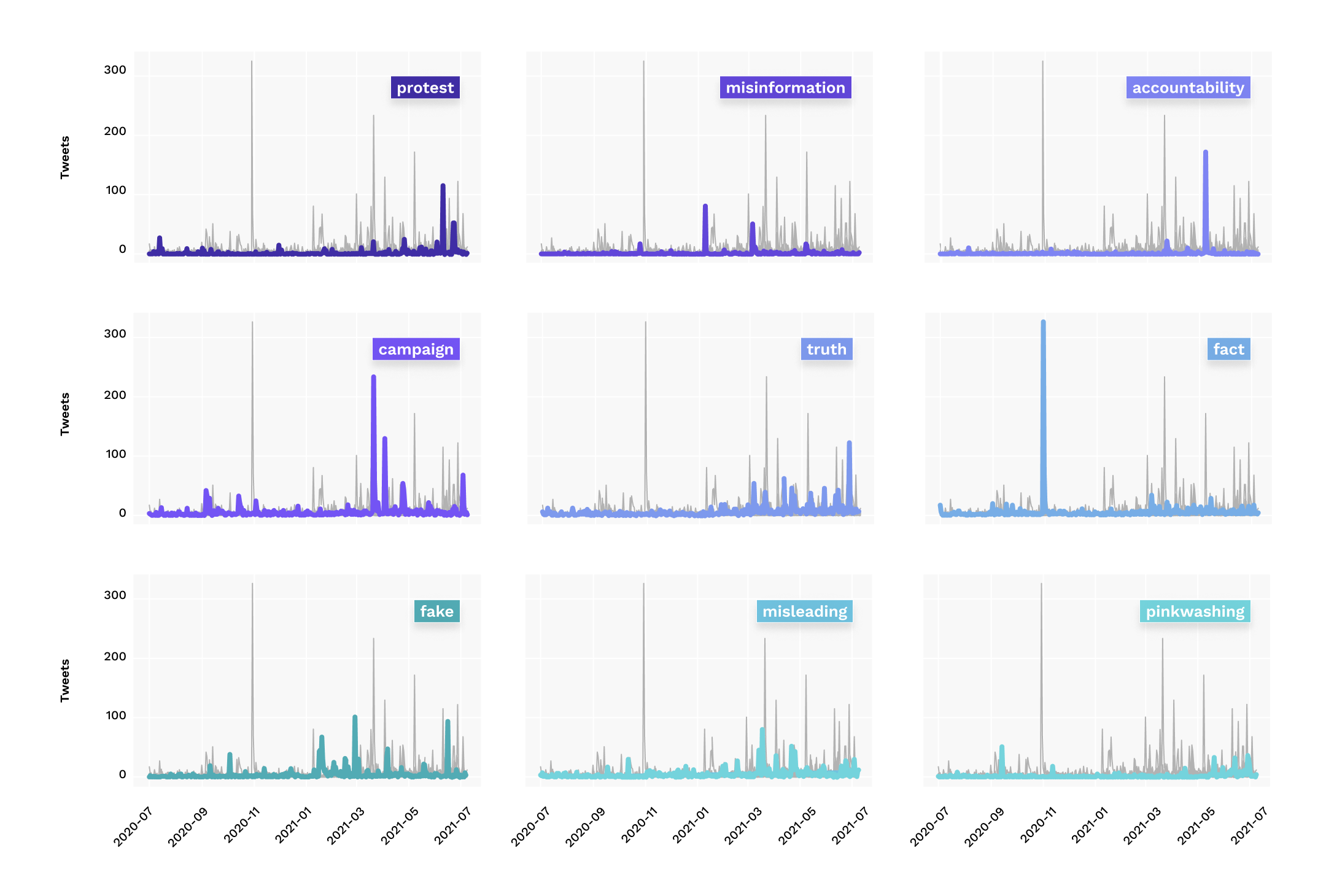
Fig 8: Keywords in the Twitter dataset from 07.2020 until 07.2021
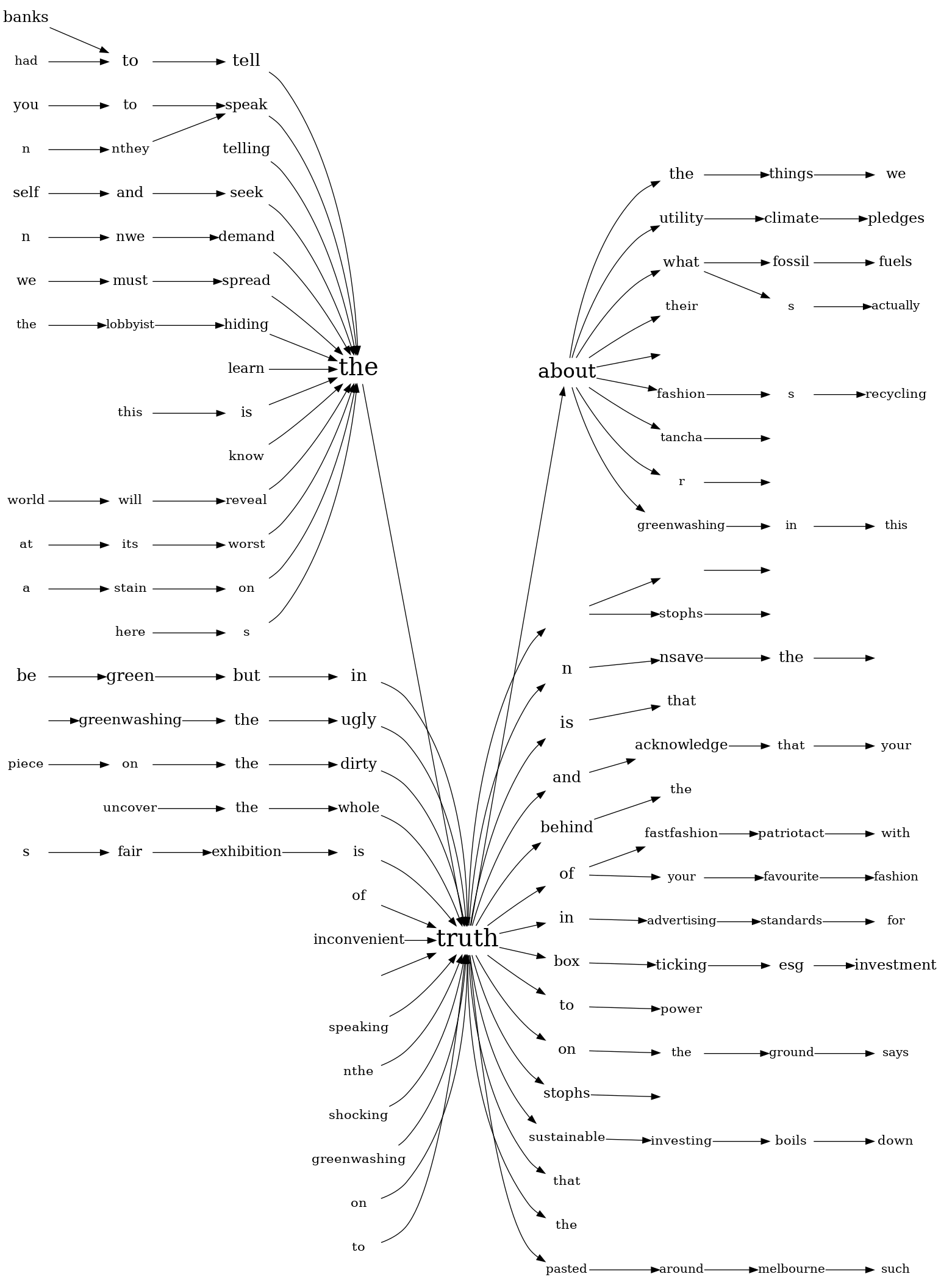
Fig. 9: Word trees displaying words connected to “truth”
We want to explore whether the meaning and inauthenticity of the term “greenwashing” may differ in different cultures. By examining the “paper straws case” in China (data is collected by Python on Microblog, the most popular social media platform in China, in the same time period of Twitter data), we found both similarities and differences. We also find some words that are closely related to “truth” in this case.
The similarities mainly rely on political and commercial levels. The Chinese ban on free plastic is the background of companies’ usage of paper straws, but Microblog users care little about the fact and claim that big companies use paper straws for saving money. Transnational corporations like Coca-Cola, KFC and McDonald are the main actors to be attacked, as well as some milk tea suppliers. It’s similar internationally that big companies are accused of “greenwashing”, but the discussion sometimes is not limited to “greenwashing”, but refers to more commercial scandals. It’s worth noting that many green-related terminologies are applied like the discussion that the potassium permanganate consumption of paper straw exceeds the standard which indicates that the netizen focuses on the technology itself and not “The Crowd” in stereotype and can not be easily cheated by “greenwashing”. The words that are closely related to “truth” are “cheat” and “doubt” which also shows that consumers are vigilant at greenwashing (Fig. 10).
In this case, it can be observed that China is still in the initial stage of greenwashing, most discussions are about consumers’ personal experience and commercial accusations. However, Chinese consumers are vigilant about the inauthenticity of green activities and have little trust in the labels of green branding.
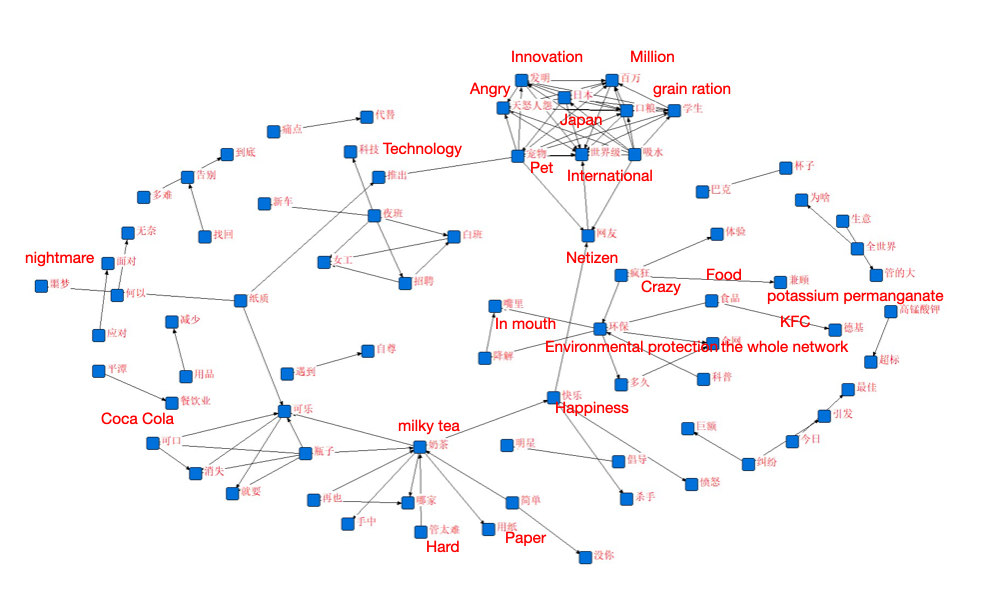
Fig. 10: Semantic network of “paper straws case” in China
1.5.4. Inauthentic activities
Let’s go back to the events and critically re-examine the emerging themes from a different angle. As a reminder: 13 January presents a much higher proportion of retweets than the 25 January and 5 March samples. While the overall data set is dominated by English tweets, most tweets on 13 January are published in Thai. When zooming into the tweet texts, it becomes clear that the data sample at 85% consists of retweets of only one tweet. This tweet was published by a user with 571 followers but later was retweeted by larger accounts. The tweet was retweeted 5548 times on 13 January in a total of 6549 tweets containing the term ‘greenwashing’ on that day. This number could be explained by larger accounts participating in retweet activity. It refers to the cosmetics company Lush cooperating with anti-trans organisations and, in this context, accusing it of greenwashing as well. In a thread, the account links a business insider article (accessed: 22 July 2021). Greenwashing isn’t the first accusation in this tweet. The user rather speculates that apart from cooperating with anti-trans organisations, they also heard of greenwashing allegations against the company but don’t know if these rumours are true. Two very different accusations are combined here.
To examine these larger accounts, we calculated the follower to following ratio, which according to Bastos and Mercea is one of various standard metrics to detect bot activity (Bastos/Mercea 2019, 43). This is a list of the accounts with the highest number of followers compared to the number of accounts they are following, that retweeted the tweet on 13 January.
A top ten list was taken as an entry point to walk through these accounts manually. Some of them predominantly retweet without showing any original tweet activity. One offers to sell retweets, the offer is placed in the geo-tag: “rate card retweet please DM”. This could be seen as a creative strategy to avoid being removed by Twitter, whose policies explicitly prohibit trading engagement metrics such as retweets (https://help.Twitter.com/en/rules-and-policies/platform-manipulation, accessed 22 July 2021). This excursion into accounts promoting the tweet that made the peak on 13 January opens up further questions that couldn’t be investigated within this project, like: Did one of the suspicious accounts trigger the chain of retweets? Are their followers real? The extremely high tweet activity also opens up questions that address automation or semi-automation.
Regarding greenwashing, this tweet and its (not totally inauthentic) resonance illustrate that greenwashing is connected to other types of accusations against large companies, e.g., collaboration with certain organisations. It’s articulated in an overall demand for more ethical behaviour and not solely expressed by users active in climate change issues.
All three selected events consist of a larger proportion of retweets than the overall sample. However, the amount of retweets from 25 January and 5 March isn’t generated by only one tweet. On 25 January, the most retweeted tweet was one by a French communist politician, calling the conflict behind the union strike at the Total Grandpuits refinery a social and environmental issue and publishing a video with a striker’s statement. On 5th March, in turn, the most retweeted tweet was posted by French tv moderator Mac Lesggy referring to the protest action of Greenpeace against Air France, accusing Greenpeace itself of greenwashing for selling fossil gas as ‘green gas’. For these two days, the events connected to tweet activity indeed account for a large proportion of tweets. All three most retweeted tweets clearly name the targeted organisations. Regarding the 13th of January and the 5th of March, the tweets contain an element of disclosure: Lush is presented as a dubious company and Greenpeace is converted into a target.
1.6. Discussion
Exploring the dataset by using different analytical tools lead to divergent insights: While the network analysis on author-mention relationships confirms the attribution of events ascribed in the hypothesis and to reveal how and by whom accusations were attached to targets, producing sample profiles led to reconsidering these conclusions. ‘Greenwashing’, this analysis of proportions presents, is mobilised by events like strikes and protest activities, but also re-activated when companies that were accused of greenwashing in the past are criticized for very different activities (e.g., in the most retweeted tweet from 13 January). Greenwashing, then, is articulated in a manner of disclosure. This element of disclosing unethical activities can also be observed in the most retweeted tweet from 5 March 2021, in which Greenpeace is alleged of selling fossil fuels.
Twitter analysis needs critical method reflection. For example, our analyses indicate that network visualisations can develop “a virtual life of their own” (Power 2004, 772): When solely turning to the relationship of authors and mentions, certain actors appear as crucial for a data sample. Namely, actors that present a particularly high betweenness centrality, meaning that they have the property to connect different user clusters, appear especially influential. Actors that include many mentions in their tweets appear especially active. However, both types of actors do not account for many tweets, and their content is rarely included in discussions that users participate in. Certain actors seemed to play a central role in Twitter activity around greenwashing at first sight, which appeared to confirm the preliminary attribution of events to activity peaks. However, the underlying tweets did not account for most tweets, as most of them didn’t comprise any mentions and thus appear more central than they actually are. Power describes this phenomenon as typical for aggregated metrics: They detach from their origin and introduce new standards (Power 2004), in this case: the amount of mentions or a level of betweenness centrality. While these metrics can deliver exciting insights, they have to be re-connected to the tweets they are part of to analyse them correctly.
In digital, highly mediated discourse spaces, context is difficult to maintain; with Marres (2020), one could argue that situational integrity is at stake. However, a central context of the greenwashing discussion is evident. In the discourse, truth is up for grabs. Both the literature on greenwashing PR and the literature on inauthentic activities in social media highlight that truth is a highly debated topic among the actors involved. Our analyses build on this and show that truth and accountability are called for by critical voices via greenwashing accusations. However, we find it problematic that this claiming is often pursued with a narrow understanding of truth and that actors cut off discourses with their criticism. With Latour (2004), this tendency can be problematised as "truth politics": actors claim direct access to some sort of stable truth that is always there, hiding below the surface (Harman 2014). In fact, on the one hand, it is open to debate to what extent certain accused actors are justifiably accused – active companies are sometimes easily attacked, which is also known in research as "brownwashing" (Kim and Lyon 2015). On the other hand, a narrow notion of truth prevents greenwashing claims from mobilising a diverse crowd and actors for cultural or systemic critique. Empirically, the paradox of truth-politics could only be resolved in the sense that actors formulate fierce resistance through greenwashing accusations. In a large-scale strike addressing the fossil fuel infrastructure, as seen in the example of the French refinery, this can prove fruitful. At times, the style of some greenwashing allegations appeared to us to be irritating. Still, for affected actors, it may be one of the few remaining ways to respond to the “brutalism” (Truscello 2020) of the fossil fuel infrastructure and its harmful consequences, thus desperately calling for an alternative, liveable future.
1.7. Conclusion of Group 1
Greenwashing is used on Twitter to negotiate truth through labelling processes. This becomes apparent in the most retweeted tweet from 5 March 2021: The accusation is pushed over to Greenpeace, who had accused Air France of greenwashing before. The tweet is not about Greenpeace selling fossil gas but about making their claims appear hypocritical and therefore invalid. Something similar can be observed in the most retweeted tweet of 13 January 2021. It’s not about Lush donating to anti-trans organisations. It rather enumerates labels that have the property to defame the company. Greenwashing, these examples emphasise, has established itself as a claim on Twitter, where it functions as a vehicle for cultural and systemic criticism. Yet, a critical examination of dynamics is required. The topic modelling could be developed further. Perhaps a “word embedding” approach produces even better results (e.g., via word2vec, lda2vec). We also suggest doing research on green(washing)-specific ratios to understand the differences in how certain users or themes are addressed (e.g., comparing the ratio of mentions of accounts with a certain tag).
We recognise a tension between accusation and appropriation, i.e. conservative actors sometimes take greenwashing charges to the absurd and turn them on their heads. This is in the tradition of climate change deniers and environmental degradation relativists who may use greenwashing PR as a strategy to preserve business as usual (Malm and Zetkin Collective 2021). But the appropriation does not often succeed; greenwashing accusations have a fairly stable power across Twitter to hold companies accountable. The dominant topics represent this tendency. So what? Greenwashing accusations have their legitimate place on Twitter – as they overcome the dubious focus on individualised consumer responsibility that is so common in the public sphere. Yet, as the discussion above has highlighted, one key problem is that the discourse easily lapses into superficial truth-politics and prefabricated patterns of critique. Only in certain cultural contexts can this become a far-reaching resistance movement.
Group 2: Cross-platform URL dynamics
2.1. Group Members
Maria Lompe, Nicolaus Copernicus University in Toruń
Suay Melisa Oezkula, Università degli Studi di Trento
Estrid Sørensen, Ruhr-Universität Bochum
Mariangela Vespa, Institut für Zukunfts Energi und Stoffstromsysteme (IZES gGmbH)
Tianshi Zhao, University of Pennsylvania
2.2. Introduction
This sub-project explored online dynamics around the keyword “greenwashing” with a focus on discourses surrounding URLs. The positioning of greenwashing as an (to a degree) inauthentic practice suggests that online coverage of greenwashing would be ambiguous, i.e. tied to conversations around inauthenticity, “fakeness”, or fact-checking, yet not part of the dynamic and sometimes toxic spaces that fake news discussions have been affiliated with. These expectations were grounded in the different ideological orientations and targets of accusation that greenwashing claims pertain to. Greenwashing is typically understood as an accusation of exaggeration or inauthenticity in environment-conscious behaviour, above all in carbon footprints. These claims typically originate from pro-environmental groups and are targeted at commercial organisations, for whom “green behaviour” has become a significant part of corporate social responsibility and the subsequent market value and consumer relationships. In comparison, fake news debates more commonly relate to a vast array of issues that split groupings on opposite sides of the political spectrum (e.g. anti-vaccination campaigns, flat-earther groups, election campaigns) and often target either a specific political party, their following, or media conglomerates publishing the news. As such, debates on greenwashing claims should, in theory, more uniformly be targeted at pro-environmental groups that seek to monitor, watch, and hold accountable organisations overstating their environmental impacts.
In response to this issue, this sub-project explored in how far the association of the term “greenwashing” with pro-environmental movements is indeed reflected in URL sharing on social platforms and with the contents of these URLs. The project conducted this study through an examination of (1) issue language in URL contents, and (2) a mapping of the wider URL networks. In doing so, this project combines what has been described as a combination of ‘computational heuristics and close reading’ (Rogers, 2019: 43) towards understanding wider discourses of an ambiguous phenomenon.
The project included a cross-platform element by comparing URL contents and URL networks that were highly engaged with on the social media platforms Facebook, Reddit and Twitter. This choice created a unique set of methodological challenges. It sought not only to understand a single URL network and its issue language. It also conducted a comparison of several lists of URls that social media users engaged with across platforms, which can only be done by comparing across each platform’s specific technological mechanisms, tagging markers, and affordances. In other words, the study was based on a methodological approach, which differed both from single-platform studies and from the more conventional cross-platform analysis. This innovative approach was deliberately chosen towards generating an alternative pathway for exploring both platform differences and the different repercussions URL sharing on different platforms have.
2.3. Research Questions
Following research questions were posed:
RQ#1: To what extent are URL sources and contents (i.e. materials/evidence) on “greenwashing” (successfully) targeted towards progressive movement actors?
RQ#2: Alternatively, do the issue networks and discourses surrounding greenwashing indicate the existence of marginalised discourses, including potential anti-programmes? (as per the distinction of programme and anti-programme in Rogers, 2019)
RQ#3: What differences exist based on the platforms where these URLs have shown high engagement? (i.e. does the platform space matter in terms of discourse)
RQ#4: How does issue language and discourse differ between social media commentary & URL contents? (comparison with Facebook and Twitter posts)
2.4. Methodology
2.4.1. Initial dataset: building a link list
The initial dataset for this enquiry consisted of a URL link list created through Buzzsumo (https://buzzsumo.com/). The tool was queried on URLs relating to “greenwashing” that have been most engaged with on Facebook, Twitter, and Reddit over the past 12 months (July 2020 to July 2021). Toward creating a consistent dataset that could be interpreted by all group members, only English texts were selected. Although the tool also provides data for Pinterest, these data were not judged relevant to the query. The resulting URL list consisted of 2227 links. It was extracted from Buzzsumo and then split into 4 datasets based on different sorting:
-
Ranked by overall top engagement across platforms
-
Ranked by top engagement on Facebook
-
Ranked by top engagement on Twitter
-
Ranked by top engagement on Reddit
These links were read & mined in full and as capped lists of top 100 (for text-mining) and top 20 (for CrowdTangle). The choice to cap the lists emerged from disparities in engagement. For example, Reddit showed considerably less engagement with URLs on greenwashing than Facebook. As a result, not all of the 2227 links were engaged with (and therefore relevant) for the platform. The lists were therefore capped to exclude very low engagements.
2.4.2. Python topic modelling & WordTree
For a broad overview of issue language, python topic modelling was used (assistance from Stefan Laser from sub-group 1) for identifying related word clusters. These initial clusters provided a basis for a basic comparison with sub-group 1 (c.f 3.5.3).
For a more detailed understanding of issue language, the URL contents from the Buzzsumo link lists were scraped from the link collection through a custom program (created by Stijn Peeters). The contents were then exported from the csv file into Word documents for cleaning. The cleaning was a reiterative process, for which a common stop list was used and further exclusions were made after initial WordTree visualisations. A particular challenge lay in the exclusion of undesirable contents scraped alongside the article body, e.g. disclaimers, user guidance features, and additional columns. Therefore, the final cleaning run for each file was manual. The final datasets were entered in WordTree (https://www.jasondavies.com/wordtree/) by Martin Wattenberg and Fernanda Viéga) for visualisation.
2.4.3. URL social media networks
IssueCrawler:
An IssueCrawler (https://www.issuecrawler.net/) snowball analysis was used to study the extended network of the web pages that are likely to be reached when following the URLs that are mobilised on the three social media platforms when engaging with the notion “greenwashing”. The data used as a basis for these analyses were the same top 100 URLs engaged with on Twitter, Reddit and Facebook and extracted with Buzzsumo, as explained above. The chosen crawl degree of separation was set to 1. The aim was to capture the wider URL networks as a way of determining where and how greenwashing discourses spread, and also to gain a sense of the wider source networks surrounding the debate. While a co-link analysis was preferred towards understanding specificity in links, technical issues in data collection limited the choice to snowball analyses.
CrowdTangle:
Capped lists of 20 URLs each were additionally entered into CrowdTangle ( https://www.crowdtangle.com/ ), separated by Boolean operator OR. Although larger URL lists (e.g. 100 top links) would have been preferred, word count restrictions on CrowdTangle limited the enquiry to 20 links. The aim of this exercise was to create a database in csv format that listed the Facebook groups and Reddit sub-groups sharing these links. While it was also possible to generate such a database for Twitter, CrowdTangle limited the extraction of data to 7 days (rather than 1 year), and the data contained individual rather than group or public accounts. Due to the thus appearing lack of comparability data for Twitter was not considered here.
The resulting csv files included the names of Facebook pages and Reddit sub-groups, the type of group and sub-group (e.g. NGO, political, news), the number of reactions to the link, the shared link, and the content of the post in which the link was published. Towards creating a visualisationbetween links and social media groups, additionally a metafile including the name of the Facebook or Reddit group, group type, and the shortened link was created. The aim of this part of the study was to explore what kind of actors shared links circulating on the web related to the term greenwashing, whether these are indeed the anticipated progressive pro-environmental actors, and what these URL uses suggest about greenwashing discourses surrounding highly engaged materials. Of particular interest was the discovery of any potential anti-programmes stemming from significant disparities in actor types and issue language in those spaces. Towards that purpose, these files were used for both relational visualisations (alluvial diagrams) and the post contents were also visualised with WordTree for an analysis of discursive features. A particular challenge in the cleaning of the WordTree files were common words in Facebook posts as well as the frequent embedding of the URLs that subsequently informed the results. This was mitigated through further manual cleaning processes.
2.4.4. Data outputs, refinement, & visualisation
The final dataset (see Fig. 11) consisted of 2227 URLs scraped from Buzzsumo (in the full list, not separated by platform). These were split into 3 URL lists by platform (Twitter, Facebook, and Reddit), which produced 8000 A4 pages of textual URL content data (through scraping for URL contents with a custom program) and 128 A4 pages of Facebook comments (through CrowdTangle scraping).
Data was refined based on engagement by platform, i.e. separate URL lists (Buzzsumo), as well as engagement by platform with these links on Facebook and Reddit (CrowdTangle). The individual lists were analysed through a reiterative process using WordTree, IssueCrawler snowball network analysis, and CrowdTangle relational alluvials
Fig. 11: research protocols Data were visualised through word trees and clusters (= discursive features) and network graphs. As part of a comparative element that situated the URL work with the Twitter work of sub-group 1, additionally, a time series and topic modelling comparison were created. IssueCrawler visualisation The visualisations are of interest to find out what web pages - and organisations or actors - profit from people engaging with the term “greenwashing” in the way they do on social media. When people use the notion of “greenwashing” on a social media platform and also post a link to a webpage, then it is likely that people will click on that link and read the web page. Maybe they will also click on links on that webpage. If they do so, they are likely to end up on one of the pages that are shown as nodes in the visualisations below. The visualisations show the interlinkages of these pages. The nodes show are two clicks away from the social media posts on “greenwashing”. We suspect that they are not always the organisations and actors that the social media users expected to mobilise - or even wanted to contribute to mobilising - when they included a URL in their post. Thanks to Valentina Pallacci and Fabiola Papini for improving the visual quality of the IssueCrawler networks. CrowdTangle visualisation: To show the connections between URLs links and Facebook groups and Reddit sub-groups, an Alluvial diagram was used. The visualisations were divided into eight diagrams. For each list of links that gained the highest total engagement, highest engagement on Facebook, Reddit, and Twitter, a visualisation was created showing the Facebook groups that shared the links and the Reddit sub-groups that shared the links. To enhance the clarity of the visualisation, the groups have been sorted by their type: purple - environmental pages, green - news, yellow - NGOs, red - politics, company and organisation, blue - education and brown - science. The thickness of the lines corresponds to how much engagement (reaction, liking, commenting, publishing the post) the link shared in the post gained.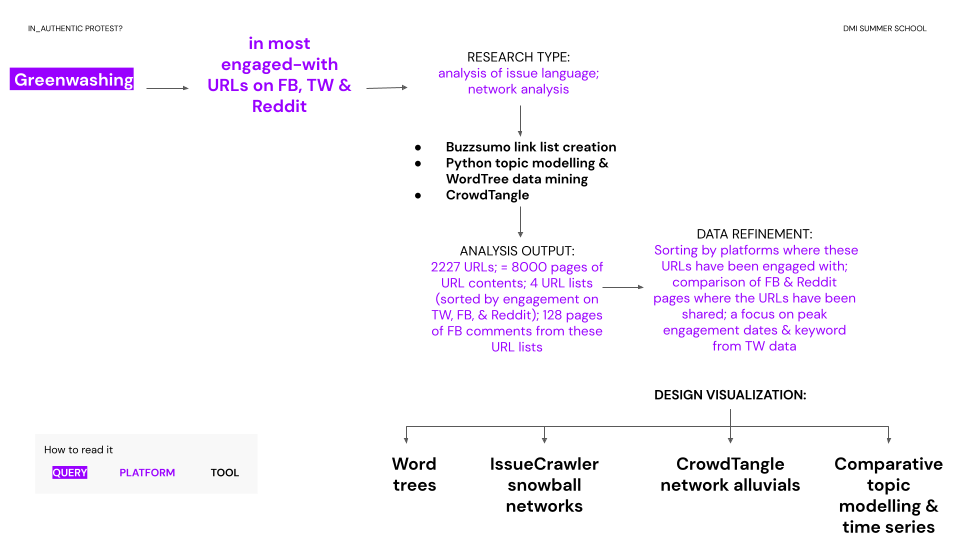

2.5. Findings
2.5.1 URL issue language (WordTree) Full dataset issue language A general finding of the word trees was that greenwashing mentions frequently related to definitions and explanations of the term rather than wider discussions of the issues, claims, or accusations. These explanations were typically framed as “greenwashing is…” or “greenwashing example” (see fig. 12 & 13). Together with wording that suggested a general (rather than expert) target public, the word trees suggested that URLs are often used for contextualised understandings of the term rather than evidence of the greenwashing claims and accusations.

Fig. 12: greenwashing word tree

Fig. 13: greenwashing definition word tree
Issue language by platform
Few differences emerged when the URL lists by platform were mined. While the top URLs had shown few differences across the platform sorting, the full lists had shown more discrepancies. Even so, URL contents did not show significant differences in issue language. As such, Reddit, Facebook, and Twitter were fairly homogenous in the URLs they shared.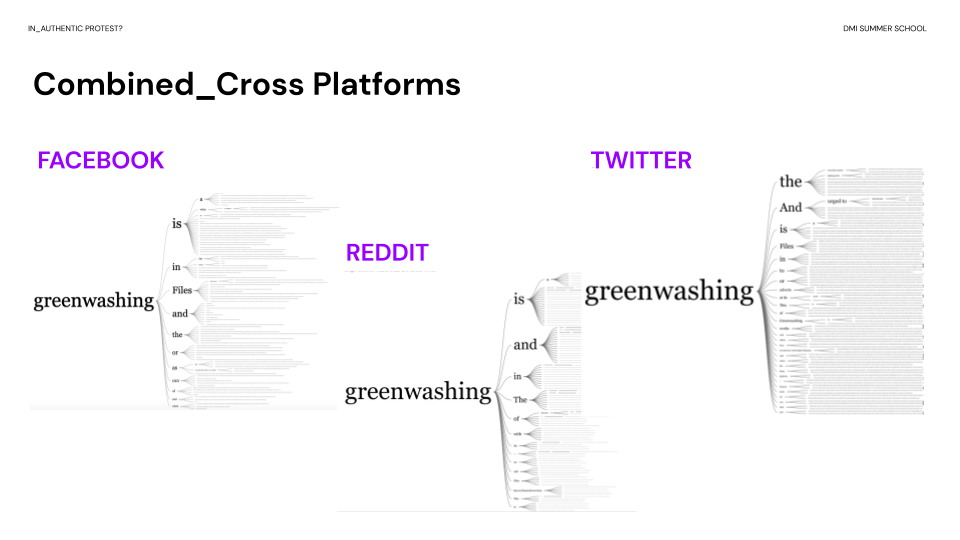
Fig. 14: word tree comparison across platforms
Issue language in Facebook comments
In comparison to the mined URL contents, the mined Facebook commentary on the URLs (CrowdTangle scraping) showed more differences. The URL lists by highly engaged platforms (Facebook, Twitter, and Reddit) showed that Facebook comments varied more strongly depending on which URLs they used. As output, it is possible to underline that the Facebook commentary highly engaged with on Twitter and Reddit are more focused on business, such as investments and marketing; while the Facebook commentary highly engaged with on Facebook are focused on environmental issues, such as emissions and risks.
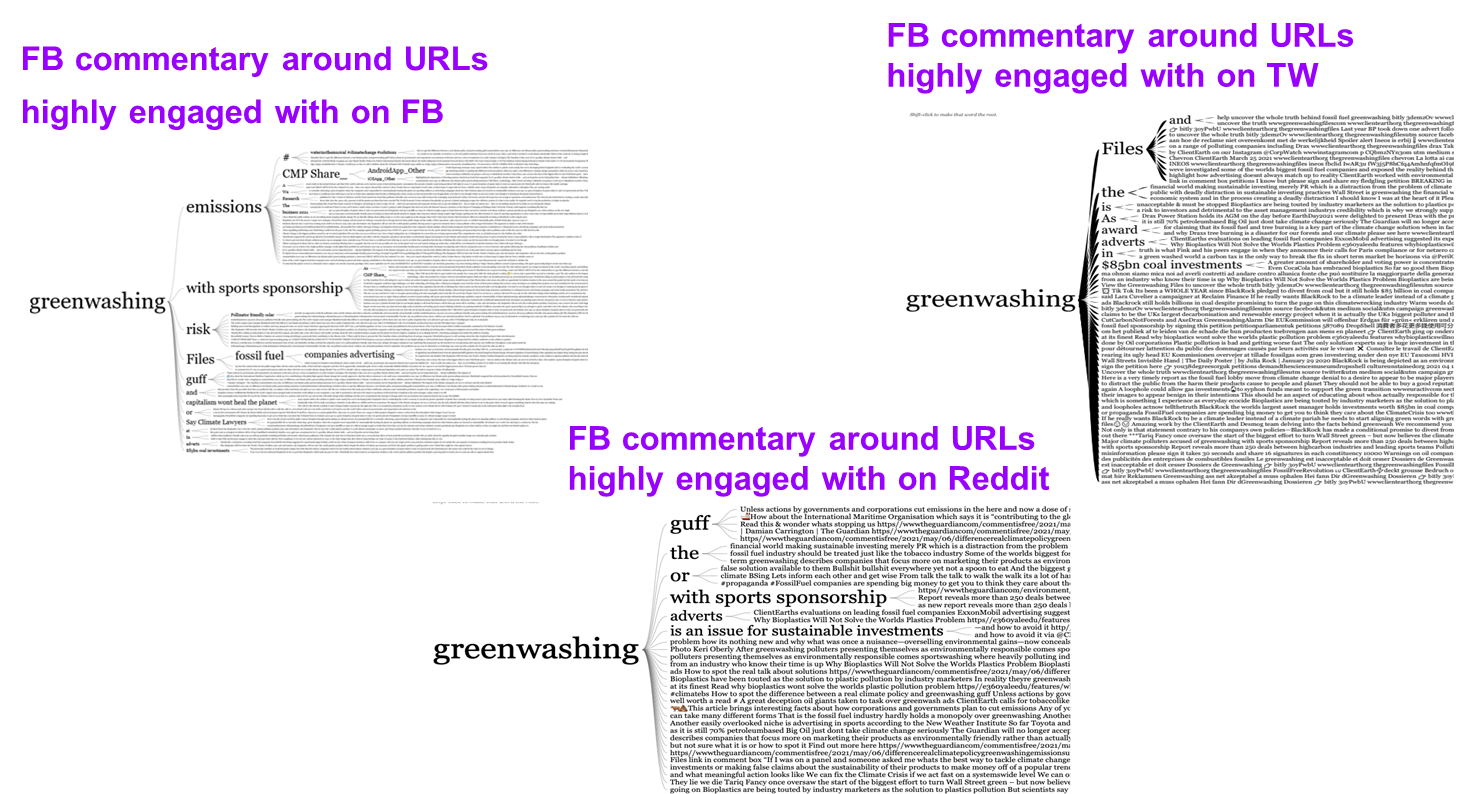
Fig. 15: word tree comparison of Facebook comments across platforms
2.5.2 Issue networks (IssueCrawler)
The visualisation of the URL networks emerging out of the three platforms’ engagement with “greenwashing” all mobilise finance and investment web pages, which appear in the three visualisations as the large clusters on the right-hand side. The interesting differences lie in the smaller clusters that are mobilized. Only on the URLs following off of Reddit we encounter a small cluster on leftwing news shown on the left in the visualisation.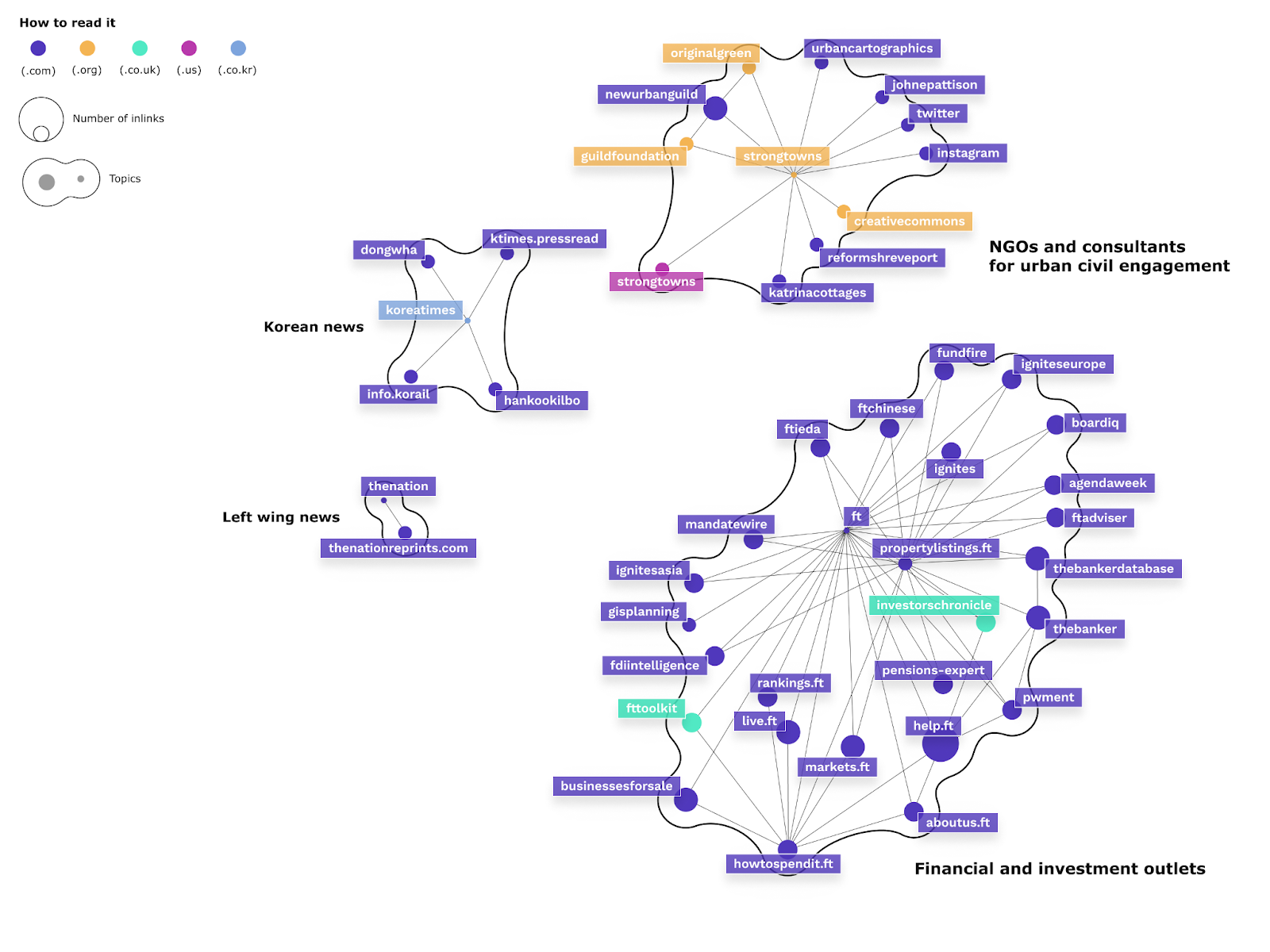
Fig. 16: Snowball network of URLs one distance from the URLs engage with on Reddit
The visualisation of the URLs linked to from the URLs engaged with on Facebook show a small cluster of Republican news backfiring “greenwashing” accusations at the left, at the top of the visualisation.
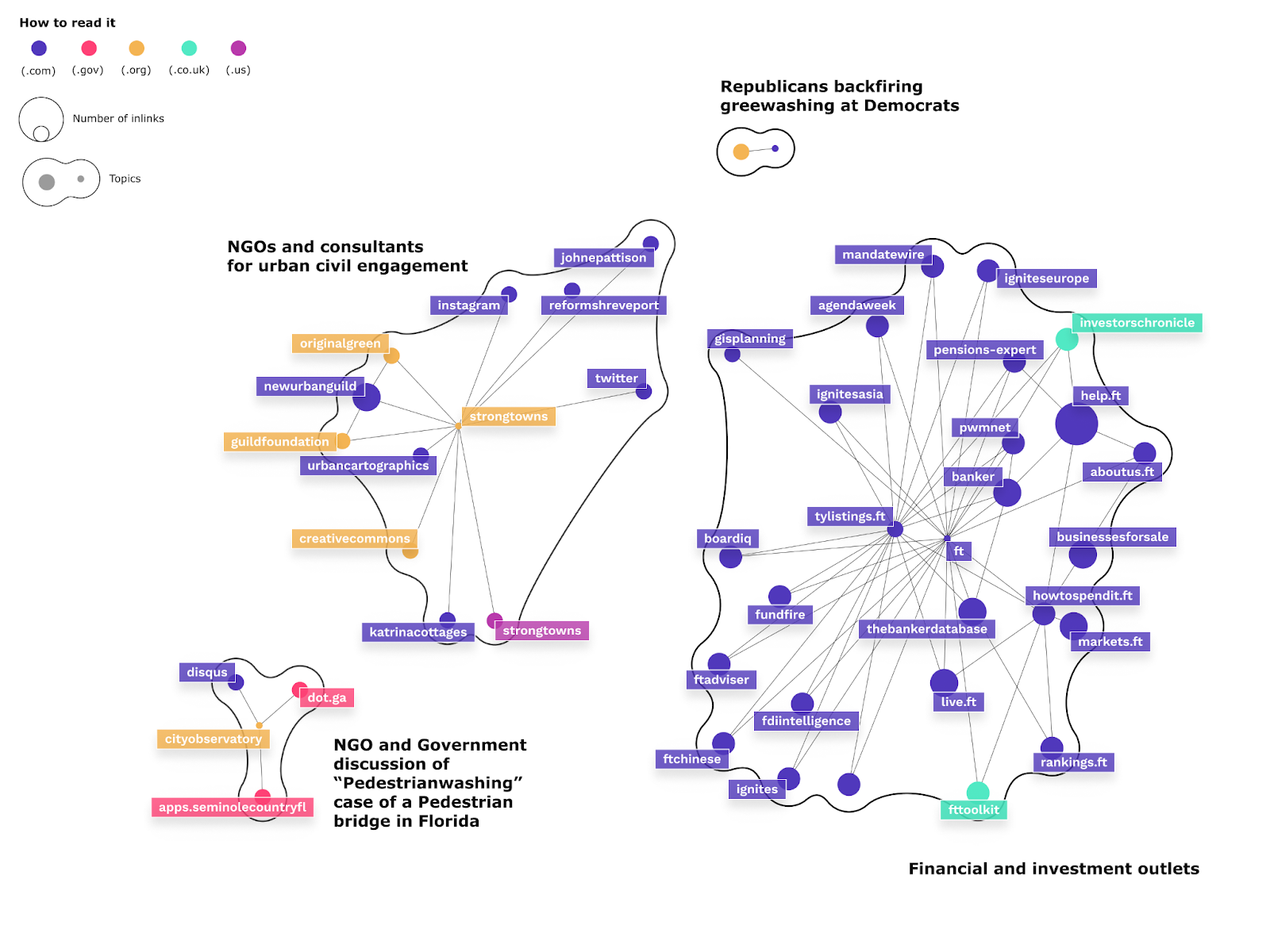
Fig. 17: Snowball network of URLs one distance from the URLs engage with on Facebook
Looking at the URLs that are mobilised through engagement with “greenwashing” on Twitter we encounter a large cluster of Chinese news and social media platforms. This is interesting in comparison to the pages following from Reddit engagement with “greenwashing,” which beyond US pages only mobilise Korean web pages, while the Facebook engaged URLs primarily link to US pages.
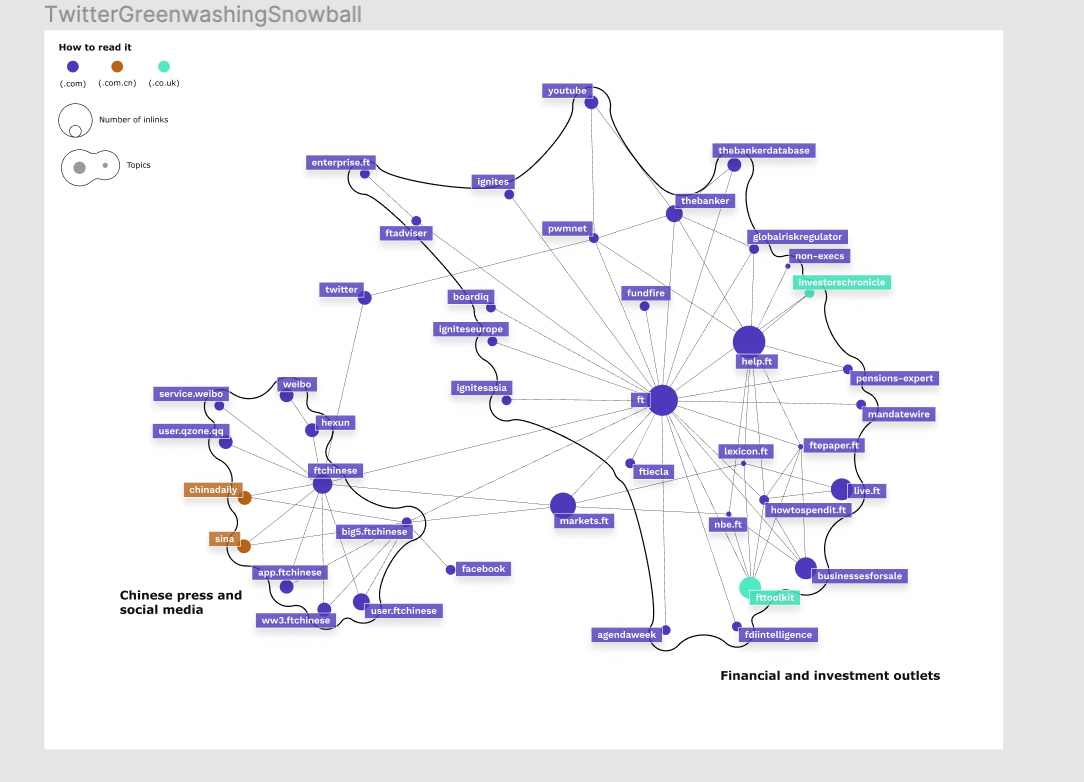
Fig. 18: Snowball network of URLs one distance from the URLs engaging with “greenwashing” on Twitter
The extended network of URLs following from engagement with “greenwashing” on Twitter shows furthermore that Financial times and indeed Twitter are the bridges that connect the large financial and investment cluster with the Chinese pages.
Together, the three visualisations give interesting insights into the internet repercussions that social media engagement have beyond their own platforms.
2.5.3 Issue networks & discourse analysis (CrowdTangle)
The issue language in word trees showed high similarity in the links associated with “greenwashing” across the platforms where these have seen the highest engagement. In comparison, more significant differences were found in the way they were mobilised by social media groups depending on platform. URLs links that gained the highest engagement were shared on Facebook primarily in mainstream newsgroups (Fig. 19) and in grassroots and NGOs groups. Sub-groups on Reddit were also mostly mainstream news, but the second-highest gaining topic was political groups (Fig. 20). These included sub-groups using counter-language (e.g. Skeptic, Cryptocurrency News & Discussion) and more politicised discourses (e.g. Late State Capitalism, British Labor Party). Reddit also showed a higher amount of environmental sub-groups (e.g. Green, Environment, Live with a Lower Impact), even though Facebook had overall a considerably higher amount of link-publishing posts and groups (which showed little environmental content). (The images below can be accessed with a higher resolution through GitHub.)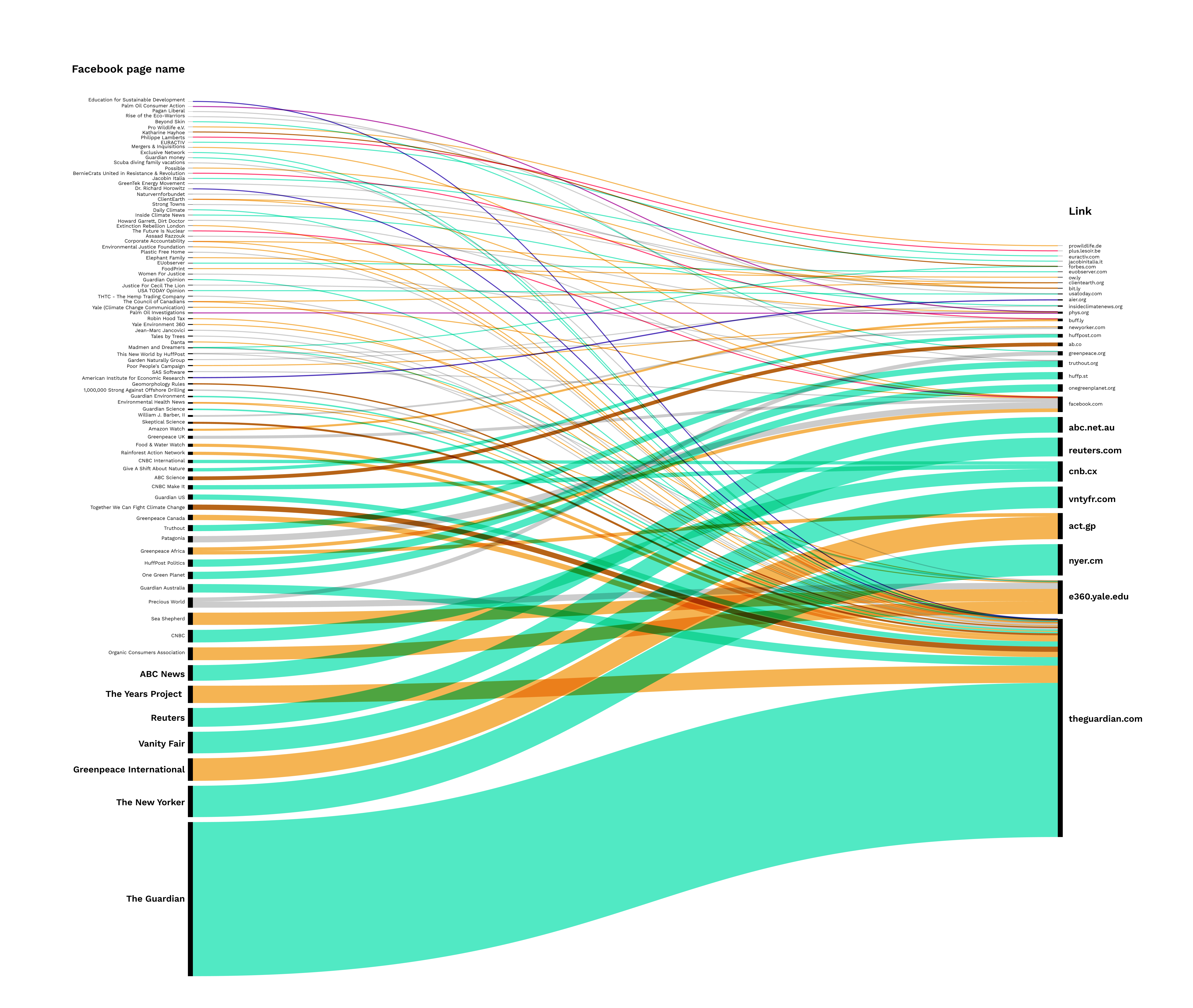
Fig. 19: Top URLs for total engagement - Facebook groups
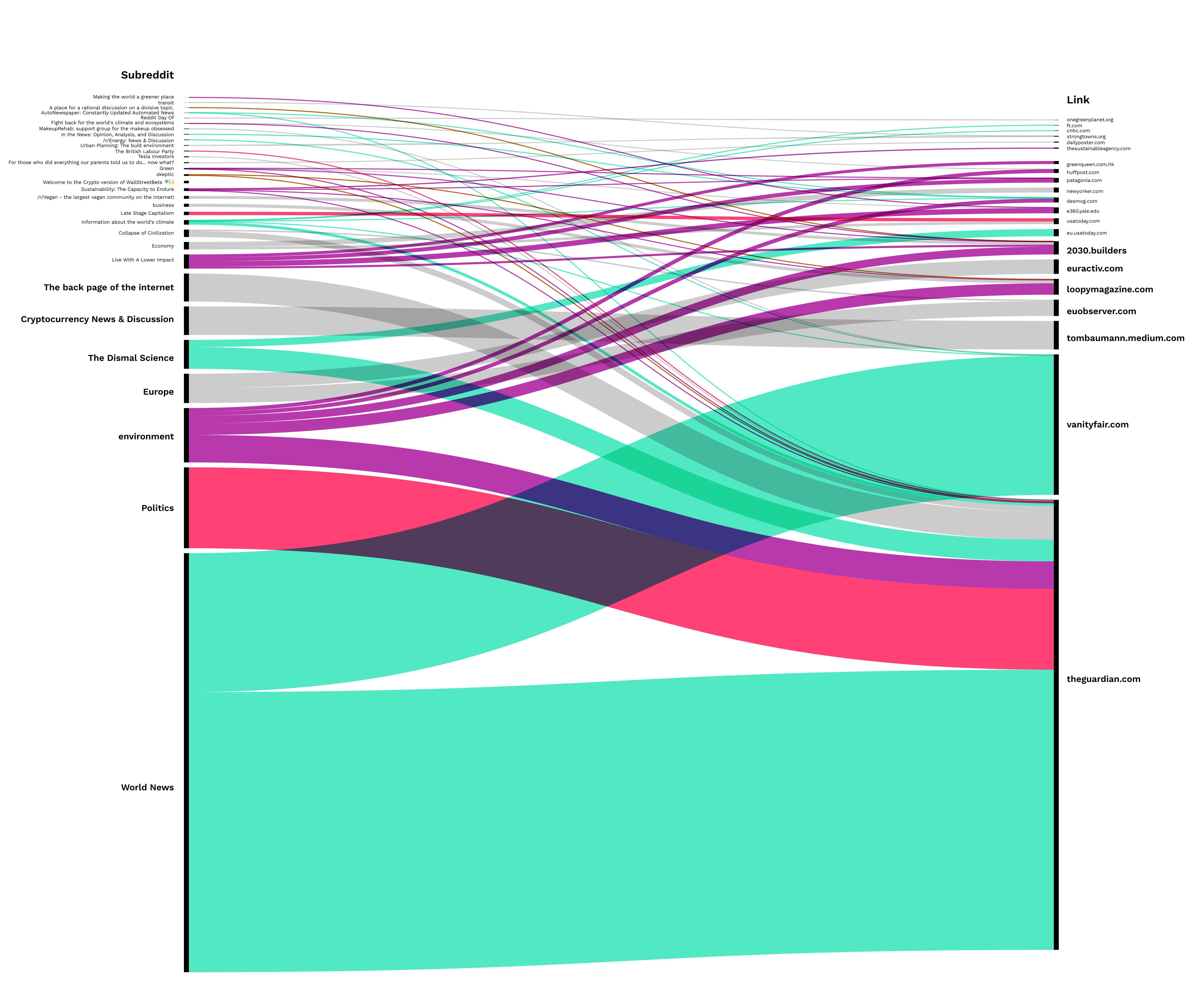
Fig. 20: Top URLs for total engagement - Reddit Sub-groups
A similar trend was identified in a comparison of Facebook groups and Reddit sub-groups for links with the highest engagement for particular platforms. Facebook groups largely consisted of NGOs, with a few environmental groups (above all Greenpeace, which mostly overlaps with official NGO pages). The exceptions were sub-groups on Reddit for links, which gained the highest engagement on Twitter. These were dominated by science groups (The Dismal Science, and groups dedicated to Cryptocurrencies). These sub-groups primarily published scientific articles rather than (like the other groups) news articles.
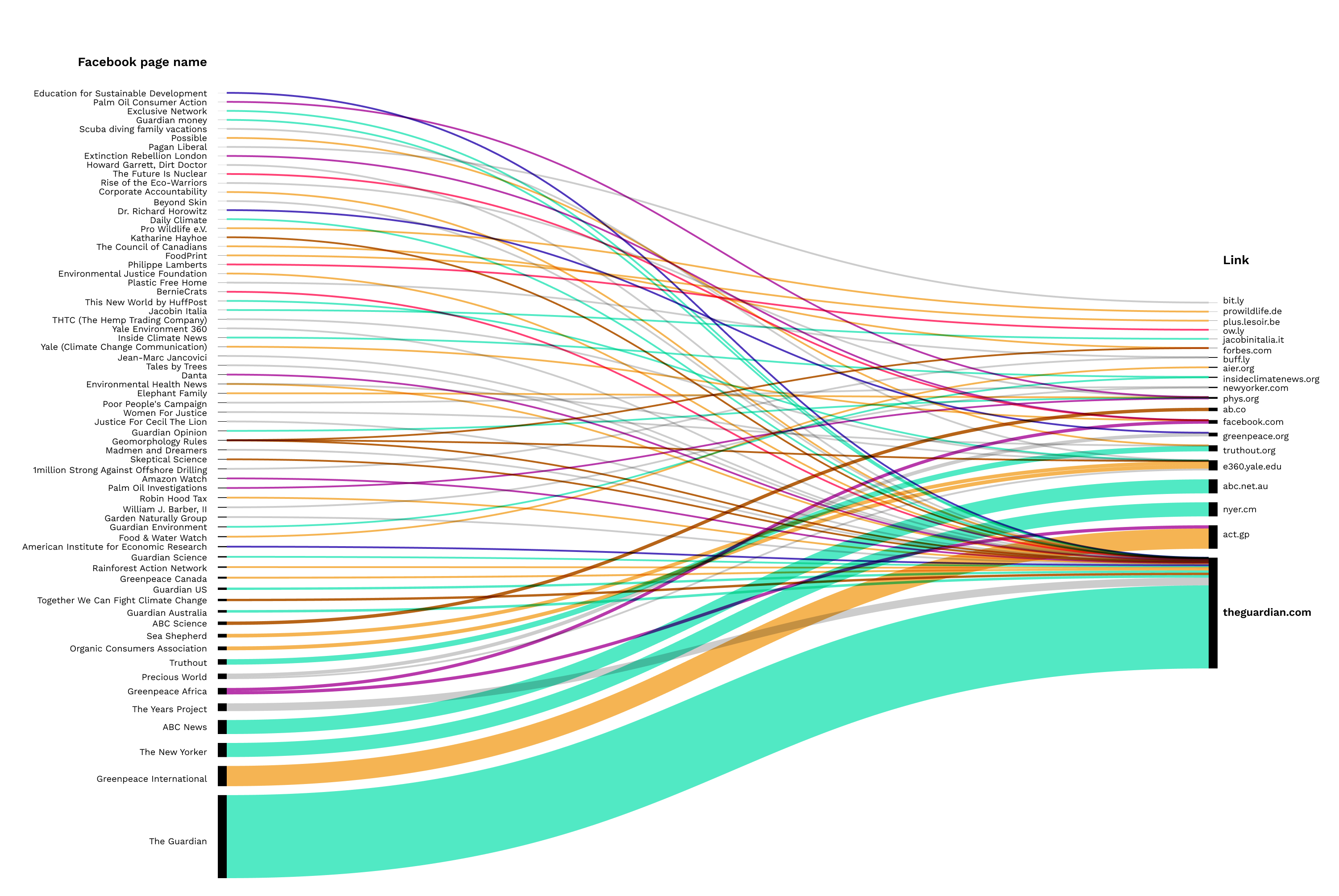
Fig. 21: Top URLs for Facebook - Facebook groups
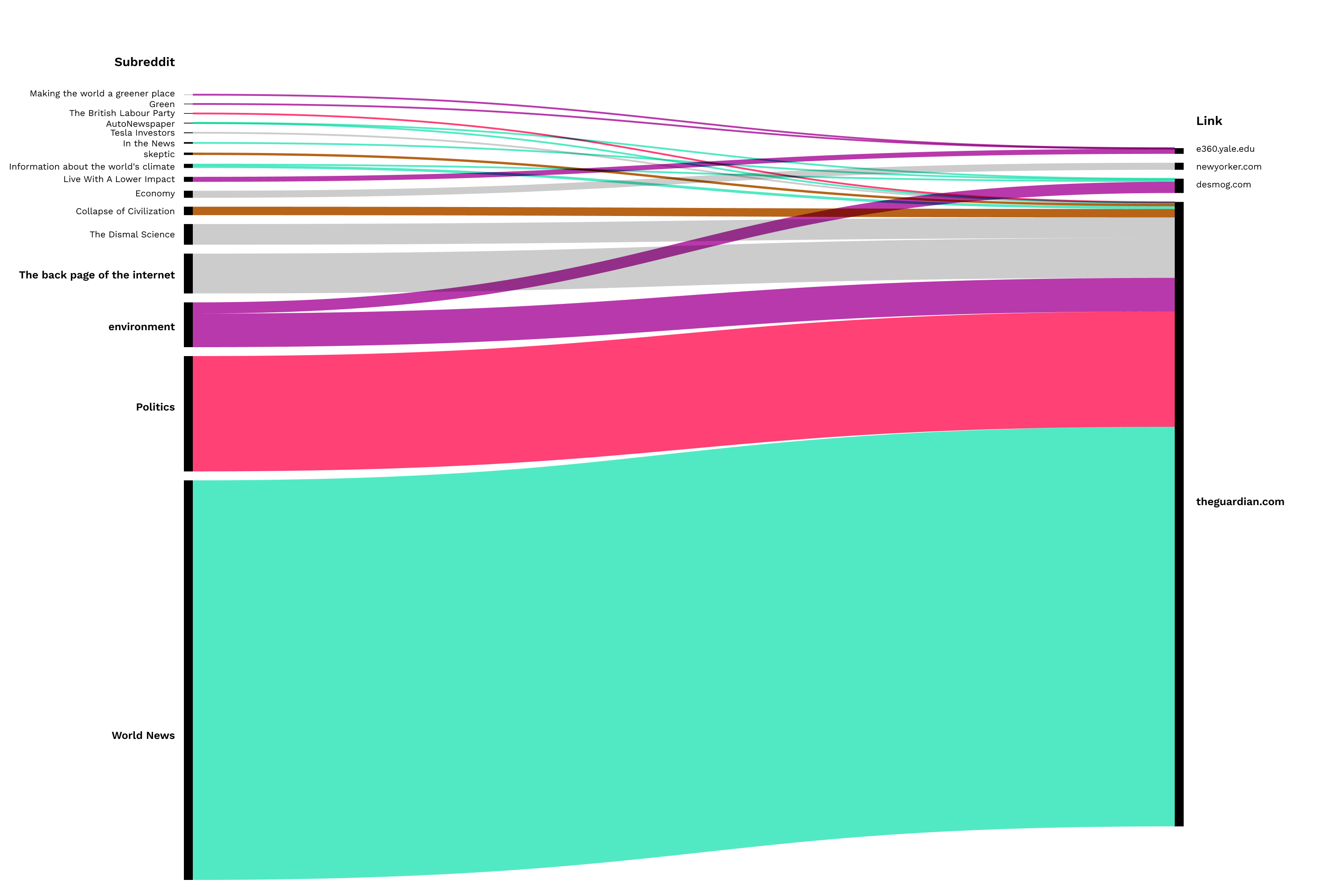
Fig. 22: Top URLs for Facebook - Reddit sub-groups
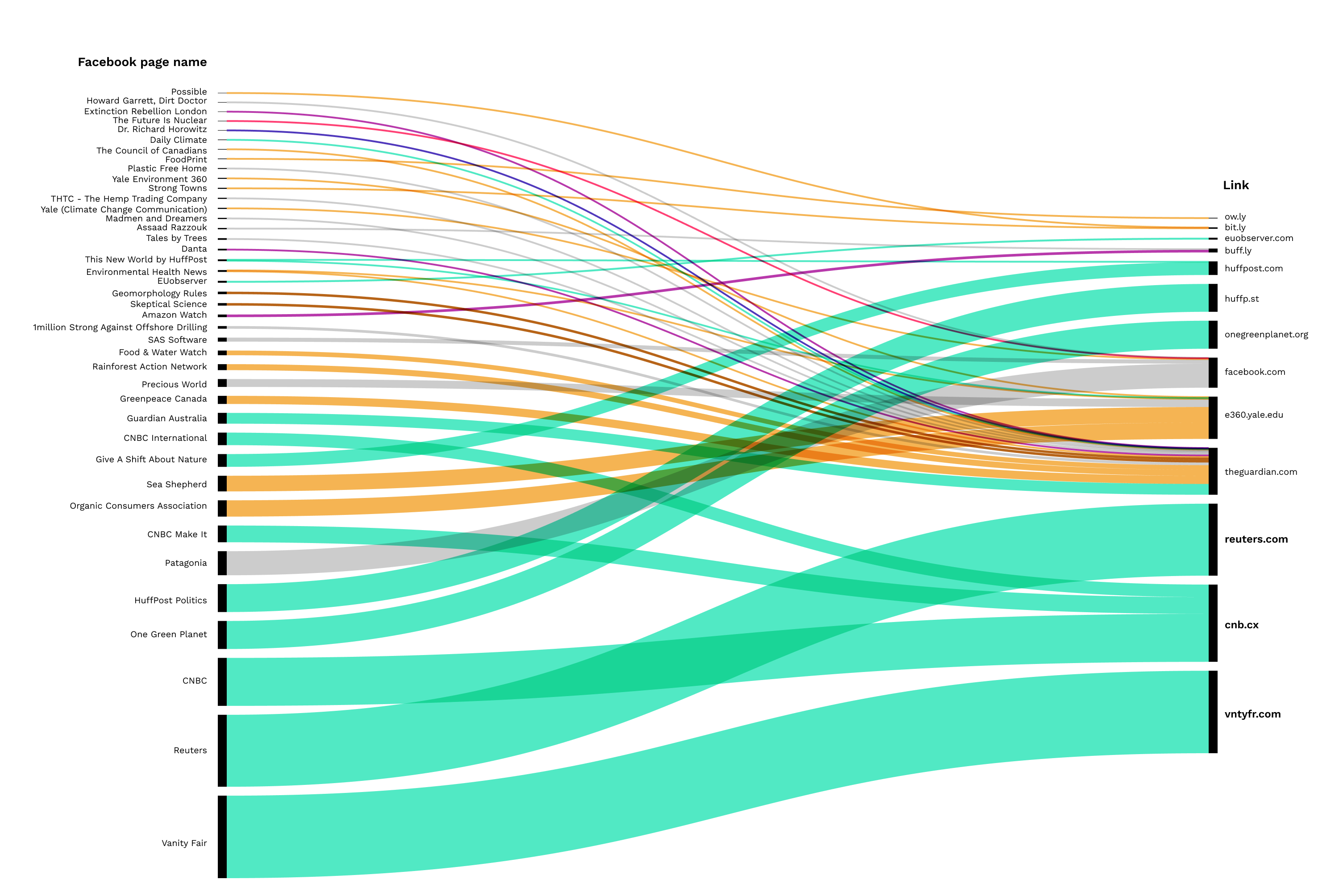
Fig. 23: Top URLs for Reddit - Facebook groups
Fig. 24: Top URLs for Reddit - Reddit Sub-groups
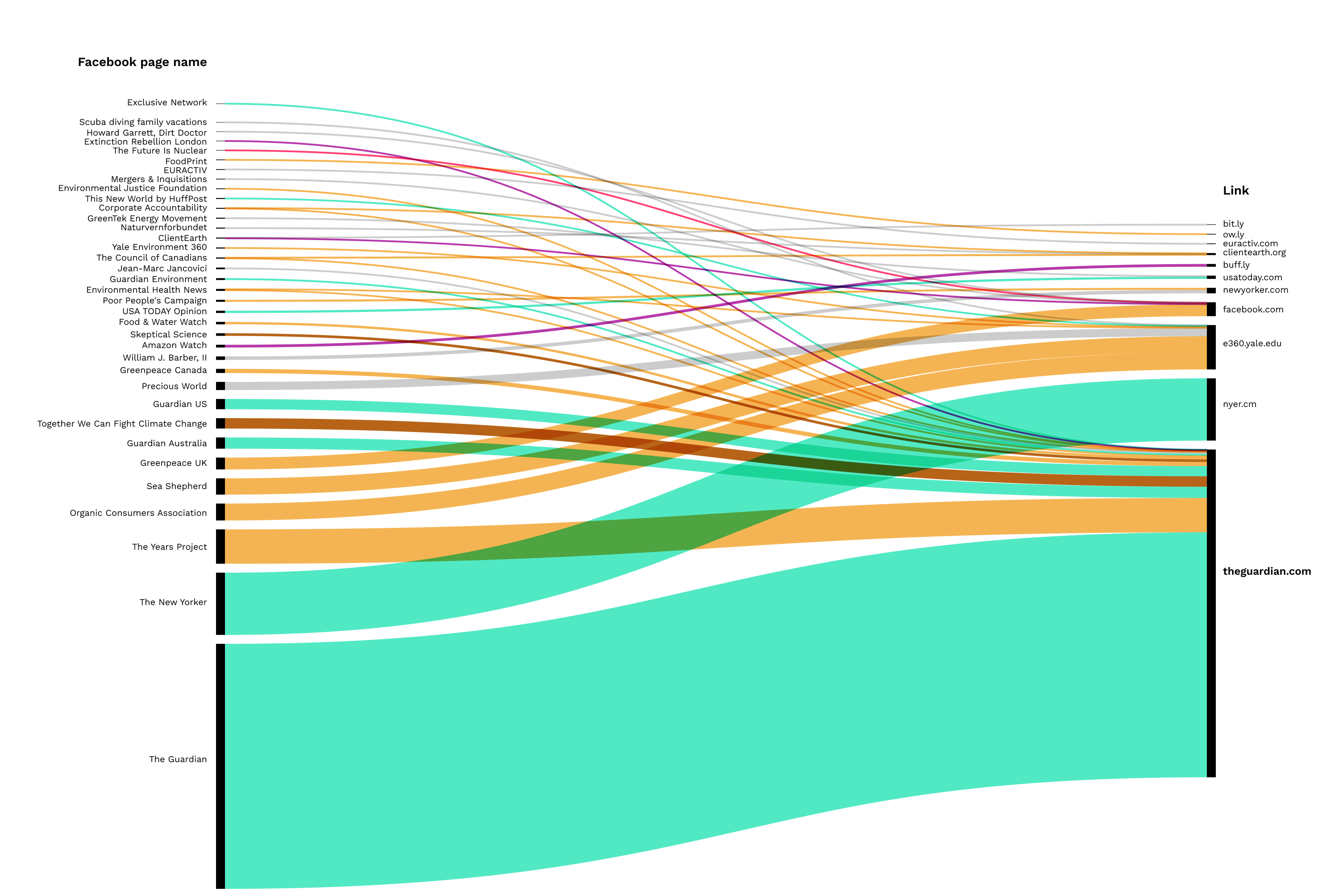
Fig. 25: Top URLs for Twitter - Facebook groups

Fig. 26: Top URLs for Twitter - Reddit Sub-groups
2.5.4 Cross-group comparison
Similar trends were found in the two exercises on matching URL findings to the Twitter enquiries from group 1. A comparative topic modelling was done both on the tweet corpus and on all URL contents across 2227 URLs. Common word clusters were identified, cleaned, and then labelled (= headings). While some words appeared across both clusters, the issue language differed significantly between the two datasets. Similarities were found in clusters around investment, brands, and commerce, as well as mentions of fossil fuels, all clusters that were common to greenwashing accusations as they relate to the accusation targets and the specific evidence the greenwashed claims address. Even so, Twitter issue language was stylistically different in that it showed a high degree of emotive responses, for example through clusters that captured a sense of responsibility, awareness, accountability, and call for action. These did not appear (for perhaps obvious reasons) in the URL contents.
In a second exercise, the group attempted to further compare the issue language by matching some of the keywords that appeared in the Twitter data and were relevant to the project’s overall research interest. These terms included protest, campaign, misleading, truth, misinformation, accountability, fake, pinkwashing, and fact. The results were equally mixed (see Fig. 27). More neutral terms such as “campaign” and “fact” appeared extensively, whereas more accusatory and emotive or ideological language did not. The latter includes words like “fake” and “misinformation”. These keywords were run across all URL lists (those shared on Facebook, Twitter, and Reddit) and they did not really feature as they were not part of the issue language in the URLs.

Fig. 27: Keyword matching of URL contents to Twitter data
2.6. Discussion & conclusion Group 2
Overall the results showed that the top URLs shared across platforms were, in fact, quite similar. In comparison, the full (rather than the top) lists showed differences in that (a) some platforms were more diverse in the contents they share (e.g. Facebook compared to Reddit), and (b) the spaces where these were shared showed significant differences (in source selection as well as narratives). As such, platform choice was significant in whether progressive pro-environmental users were successfully targeted. Issue language (in posts) and source dependency varied depending on which platform the URLs were highly engaged with, despite (1) highly similar (or even the same) ideological orientation on greenwashing, and (2) very similar URL selection & content. Thus, while the shared materials and critical stance were fairly similar across the datasets, issue language and framing changes depended on the chosen platform. These findings suggest that URL materials (incl. the facts and news shared in these) do not necessarily dictate or influence the frames in social media posts. Instead, variations could potentially be attributed to the distinct platform vernaculars, affordances, or user associations of these platforms that determine issue framing in social media commentary.
In terms of the research questions posed at the beginning of the project, this means that URL sources and contents (i.e. materials/evidence) on “greenwashing” are by and large (successfully) targeted towards progressive movement actors. Marginalised discourses (such that could be related to potential anti-programmes) were not found. Even so, significant differences existed based on the platforms where these URLs have shown high engagement. For example, while in the CrowdTangle analysis Facebook was primarily used to provide information and attempts at social mobilisation, Reddit was largely used to exchange political views, which also results in a broader discussion involving actors with different views (incl.) links from liberal media being captured and published with different commentary on conservative or skeptical groups. Platform relevance was a trend across datasets. The network graphs resulting from the IssueCrawler analysis suggested that platform choice matters considerably for orientations of the wider URL networks. Differences based on platform-related URL lists also appeared in the WordTree text-mining of the social media commentary (though not the URL networks). Thus, while URL contents showed little differences based on where these URLs were engaged with, the wider URL networks, the precise spaces where they were shared, and the surrounding social media commentary differed. This suggests that platform vernaculars carry significant weight in issue framing.
Potential limitations of this study relate to:
(a) methodological challenges that relate to a focus on URLs rather than social media commentary, e.g. issues in tool use for URLs as queries, word count restrictions in queries, and issues in cleaning;
(b) a focus on “greenwashing” as the query without the inclusion of anti-programmes (although these were also part of the enquiry). Future research would benefit from running a more holistic cross-platform analysis that further explores the vocabulary of anti-programs towards and examination of how groups sceptical of the term greenwashing use and mobilise it on social media.
Future research would need to determine how far platform identity, association, and culture influences the framing of news and evidence, above all where phenomena are (like greenwashing) tied to natural-scientific issues where evidence is of high relevance to decision-making processes.
General Conclusion
Greenwashing is now an established term in the digital public sphere. The technique of greenwashing accusation is powerful, our research emphasises. Some features of the discourse indicate particular kinds of exclusion, as indicated in the discussion of the Twitter data. In this last section, we briefly conclude with a more general methodological note.
The individual approach of the research groups (e.g. user focus vs evidence focus; single-platform vs cross-platform) significantly influences how Greenwashing is understood, enacted, and mobilised. This is because cross-platform analyses illuminate different cultures of Greenwashing. The platforms and their users format how an issue space is conceptualised, approached and lived, while the platform access we get through the tools used restricts how we can make sense of and enact the specific platforms and their cultures. Our research thus underlines a central pillar of digital method research, namely that digital practices are to be analysed in their situatedness and that with our research we also draw on our own particular perspectives and (consciously or unconsciously) weaken or overlook others.
At the beginning of our project, we had the idea – inspired by Susan Leigh Start's critical research – to follow "smaller actors" and their contributions in order to read the discourses along the grain, so to speak. We could only partially address this. More research of this kind is needed, especially on a specific topic like "greenwashing". We do not intend to suggest that greenwashing accusations are saturated with inauthentic frames with the presented research. Rather, we suggest, the subject points to the need for actors to negotiate and make fruitful uncertainties that are always contextual.
References
Adi, Ana. 2018. ‘#Sustainability on Twitter: Loose Ties and Green-Washing CSR’. In Corporate Responsibility and Digital Communities: An International Perspective towards Sustainability, edited by Georgiana Grigore, Alin Stancu, and David McQueen, 99–122. Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-63480-7_6.
Bastos, Marco T., Mercea, Dan. 2019: ‘The Brexit Botnet and User-Generated Hyperpartisan News’. Social Science and Computer Review 37(1), 38-54.
Gatti, Lucia, Peter Seele, and Lars Rademacher. 2019. ‘Grey Zone in – Greenwash out. A Review of Greenwashing Research and Implications for the Voluntary-Mandatory Transition of CSR’. International Journal of Corporate Social Responsibility 4 (1): 6. https://doi.org/10.1186/s40991-019-0044-9.
Harman, Graham. 2014. Bruno Latour: Reassembling the Political. London: Pluto Press.
Freitas Netto, Sebastião Vieira de, Marcos Felipe Falcão Sobral, Ana Regina Bezerra Ribeiro, and Gleibson Robert da Luz Soares. 2020. ‘Concepts and Forms of Greenwashing: A Systematic Review’. Environmental Sciences Europe 32 (1): 19. https://doi.org/10.1186/s12302-020-0300-3.
Klein, Naomi. 2015. This Changes Everything: Capitalism Vs. The Climate. Simon and Schuster.
Latour, Bruno. 2004. ‘Why Has Critique Run out of Steam? From Matters of Fact to Matters of Concern’. Critical Inquiry 30 (2): 225–48.
Kim, Eun-Hee, and Thomas P. Lyon. 2015. ‘Greenwash vs. Brownwash: Exaggeration and Undue Modesty in Corporate Sustainability Disclosure’. Organization Science 26 (3): 705–23. https://doi.org/10.1287/orsc.2014.0949.
Lyon, Thomas P., and A. Wren Montgomery. 2013. ‘Tweetjacked: The Impact of Social Media on Corporate Greenwash’. Journal of Business Ethics 118 (4): 747–57. https://doi.org/10.1007/s10551-013-1958-x.
Malm, Andreas, and Zetkin Collective. 2021. White Skin, Black Fuel: On the Danger of Fossil Fascism. London ; New York: Verso.
Marres, Noortje. 2020. ‘For a Situational Analytics: An Interpretative Methodology for the Study of Situations in Computational Settings’. Big Data & Society 7 (2). https://doi.org/10.1177/2053951720949571.
Power, Michael. 2004. ‘Counting, Control and Calculation: Reflections on Measuring and Management’. Human Relations 57 (6): 765-83.
Rogers, Richard. 2019. Doing Digital Methods. Sage.
Rogers, Richard. 2018. ‘Digital Traces in Context| Otherwise Engaged: Social Media from Vanity Metrics to Critical Analytics’. International Journal of Communication 12 (0): 23.
Truscello, Michael. 2020. Infrastructural Brutalism: Art and the Necropolitics of Infrastructure. Cambridge: The MIT Press.
Ideas, requests, problems regarding Foswiki? Send feedback