Spring Data Sprint 2024
Content laundering: Spread and source identification
Content or information laundering is a form of strategic communication that disguises the origins of the content by having other sources publish and/or spread it. The aim of the laundering is to make it appear to come from a legitimate source, which may be affiliates or proxies created expressly for that purpose. Spreading the message amplifies it, creating both greater resonance overall but also uptake by sources disconnected to original and its affiliates. Successful laundering thus not only obscures or washes away its origin; it spreads the message widely and with resonance, becoming part of a larger discourse, perhaps become central to it or a significant minority report within it.
Studying laundering is making its spread visible and identifying its origin as well as affiliates, though in practice the order of the steps in the methodology depends on the discovery process as well as on the working practices and routines of the investigators, monitors, and other information specialists.
One may begin with known launderers and search for the sources that spread their content, measuring resonance. This approach is to be taken at the workshop, where we would like to map out source-and-feeder networks, surfacing and exposing laundering infrastructures. Other methodologies are also welcome, such as monitoring practices that react to laundering only when a particular threshold of resonance is reached, which then triggers consideration of writing a fact check or otherwise working on publishing an exposure story.
The workshop also features a new tool set, which has been developed to study content laundering. It has content matching as well as website fingerprinting features (see below). The content matching is useful for the study of circulation and the fingerprinting for identifying affiliates and proxies.
About the new software
Disinfo.id detects content copies and networks of mirror websites automatically.
It offers multifaceted functionality for identifying and tracking instances of reposted content across various platforms. It employs advanced search capabilities, leveraging multiple search services, as well as the GDELT database, and Copyscape, to locate content based on titles and/or fragments of text.Additionally, the tool incorporates sophisticated website fingerprinting to detect commonalities indicative of shared ownership. This is achieved by recognising similarities in website code, such as shared HTML, CSS, and Javascript. Current usability allows users to input a domain name into the tool, which then generates a comprehensive list of technical indicators associated with the site. The results are presented in the form of a list of other domains likely owned by the same entity, facilitating broader analysis and investigation. Users can subsequently conduct an analysis by comparing a list of technical indicators (such as Google IDs, Bitcoin wallets) associated with flagged similar sites.
See the schedule.


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
figure1.png | manage | 45 K | 15 Jan 2016 - 12:32 | AnneHelmond | Presence/absence of trackers in Italian University websites |
| |
figure2.png | manage | 42 K | 15 Jan 2016 - 12:32 | AnneHelmond | Group of the Italian University websites tracked and the network of the trackers used. |
| |
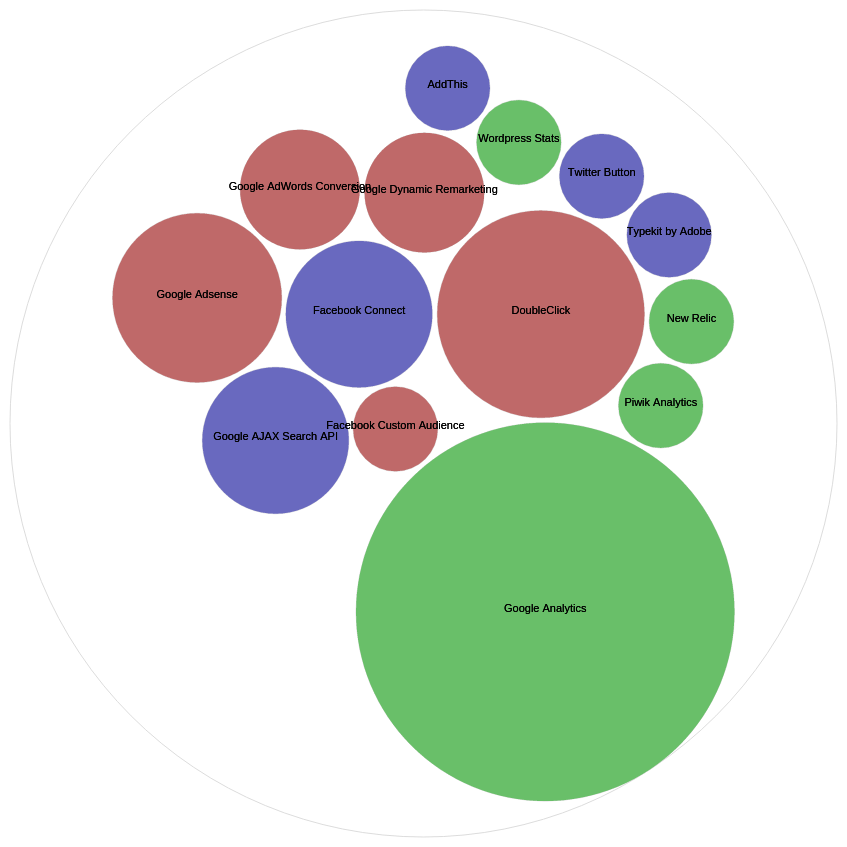
figure3.png | manage | 73 K | 15 Jan 2016 - 12:33 | AnneHelmond | Bubble chart of the typology of trackers used in Italian University websites |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback