You are here: Foswiki>Dmi Web>WinterSchool2016>WinterSchool2016ProjectPages>(Gauge,Observe,Articulate,Listen)UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch (12 Aug 2024, KunchiWu)Edit Attach
Title
Team Members
Kunchi WuContents
1. Introduction
Football, unlike many other sports, often features a lower frequency of scoring, which can sometimes obscure the relationship between a team's overall performance and the match outcome. To address this challenge, the metric of Expected Goals (xG) has been developed and widely adopted in football analytics. The xG metric assigns a probability value, ranging from 0 to 1, to each shot taken during a match, based on various factors such as shot location, shot type, and the events leading up to the shot. This value represents the likelihood of a shot resulting in a goal, thus providing a quantitative measure of the quality of scoring opportunities created by a team. For instance, consider two football matches that both concluded with a 0-1 scoreline. From an xG perspective, one match might have had an xG of 1.22 to 2.15, indicating a closely contested game with both teams creating significant chances. In contrast, another match might have an xG of 3.25 to 0.74, suggesting a dominant performance by the losing team in terms of chances created. These examples highlight how xG can offer a more nuanced understanding of a team's performance beyond the binary outcome of a match. However, while xG is effective in assessing which team played better based on the quality of chances, it does not necessarily capture the entertainment value of a match—an aspect crucial to fans and spectators. The entertainment value often encompasses more than just the statistical likelihood of scoring but includes the excitement and spectacle associated with the match events. For example, two very different scenarios, such as a blocked header from a corner kick and a spectacular long-range shot narrowly missing the goal, can both be assigned a similar xG value (e.g., 0.02). Yet, the latter scenario, particularly if involving a player like Çalhanoğlu, known for his long-range shots, might be far more thrilling for viewers. To bridge this gap, we introduce the concept of "loud goals," which refers to moments in official broadcasts where commentators respond with high decibel excitement. These moments are identified not solely by their statistical probability of resulting in a goal but by the palpable excitement they generate among commentators and fans alike. The notion of "loud goals" aims to capture the visceral, emotional response to certain moments in a match that go beyond what xG can quantify. These are the moments that, despite their statistical unlikelihood, resonate deeply with audiences, enhancing the perceived entertainment value of the game. Through our research, we aim to analyze the distribution of "loud goals" across different teams and matches, thereby providing insights into which teams deliver the most entertaining football. We will also explore the correlation between the frequency of "loud goals" and traditional xG metrics, examining whether these emotional high points align with or diverge from the expected statistical outcomes. Additionally, we aim to assess the predictive power of "loud goals" in forecasting match outcomes and league standings, potentially offering a new dimension to football analytics that aligns more closely with the fan experience.2. Research Questions
How best to capture the entertainment value of a football match? To answer this question, the project aims to expand the Expected metrics family by introducing the following new metrics: (1) highlighted xG: the xG value of the chances included in the video highlights (2) loudest xG: the chances that make the commentator scream the most during a goal-scoring action (3) spoken xG: how to derive xG from analysing live commentary transcripts (4) replied xG: the amount of replies that chances and goals are given in the highlight3. Methodology
3.1 Description of Methods By analyzing 190 video highlights of games from the Serie A season, focusing on both video highlights and live commentary, this project aims to identify the team that produced the loudest, most highlighted, and most replied xG, and compare it to the spoken and original xG values.During this process, we initially obtained all match audio files from publicly available official Serie A videos. We then utilized programming techniques to process the match information data. Natural language processing (NLP) was employed to automatically annotate the commentators' remarks on various highlight moments.
Subsequently, we used the acoustic software Praat for filtering and cleaning the audio, ensuring that only the audio segments truly reflecting the match outcomes and highlight moments were retained. This comprehensive approach allowed us to generate a detailed and actionable dataset, which is presented in the following tables. 3.2 Operationalization 3.2.1 Extraction of Raw Materials In this study, we employed a comprehensive methodology to extract and organize the raw materials necessary for our analysis. We utilized the "4k Video Download" tool to download highlight videos from the official YouTube channel "@seriea," covering all matches from the first half of the 2019-2020 Serie A season. To systematically manage the data, we named each folder containing the videos based on the URL suffix of the source page. This systematic naming convention allowed for easy identification and retrieval of the video content. The downloaded video files were then converted into WAV audio format using the FFmpeg software, a powerful multimedia framework. This conversion was essential for facilitating subsequent audio analysis. Each converted audio file was stored in its respective folder, alongside a "match.json" file, which documented detailed match data such as team names, player information, goal events, and expected goal (xG) times. Additionally, each folder contained a transcript file of the commentators' remarks on the highlight moments. These files provided a rich dataset, capturing both quantitative match statistics and qualitative commentary, essential for a nuanced analysis of the game dynamics. To prepare the data for analysis, we used Python scripts to parse the "match.json" and transcript files, extracting relevant information and creating comprehensive player lists for both home and away teams. This preparatory step was crucial in ensuring the accuracy and consistency of the data used in subsequent analytical processes. 3.2.2 Annotation of Highlight Moments to Teams The annotation process aimed to attribute each highlight moment accurately to the corresponding team, a task facilitated by the detailed data gathered in the previous step. Utilizing the player lists and commentary transcripts, we ran a pre-configured Python script designed to match player mentions in the commentary with the player lists of both teams. This matching process allowed us to identify which team was being referred to in each highlight moment, particularly focusing on offensive actions. A critical innovation in this methodology was the handling of goalkeeper mentions, which posed a unique challenge. The default assumption that mentions of a player from Team A correspond to offensive actions by Team A often led to misclassification, particularly in scenarios where a mention of the goalkeeper indicated a defensive save rather than an offensive play. To address this, we developed a "goalkeepers’ list" for all Serie A teams, identifying the primary and backup goalkeepers for each team. During the annotation process, we implemented a technique of "goalkeeper swapping," where the goalkeepers' team associations were reversed. This means that if a goalkeeper from the away team was mentioned, it was interpreted as a reference to the home team's offensive action, and vice versa. This approach allowed for a more accurate classification of highlight moments, particularly those involving significant defensive plays by goalkeepers. 3.2.3 Audio Analysis Following the annotation of highlight moments, we integrated the annotated comment files with the corresponding WAV audio files. These files were collectively processed using Praat, a sophisticated software tool for phonetic analysis. The primary objective of this step was to filter and clean the audio data, isolating segments that were truly indicative of significant match events and emotional peaks. To achieve this, we set specific parameters in Praat, tailored to identify and retain the most analytically relevant audio segments:
- Minimum Duration (minDuration): This parameter was set to 1 second, ensuring that any audio interval included in the analysis had sufficient length to provide meaningful context.
- Minimum Merge Duration (minMergeDuration): Set at 2 seconds, this parameter merged intervals separated by short pauses, thus preventing fragmentation of continuous speech or noise indicative of significant events.
- Minimum Pitch Quantile (pitchMin$): We used the 85th percentile of pitch as a threshold to identify "excited" states. This filtering aimed to capture moments of heightened emotional expression, often correlating with critical or thrilling game events.
- Minimum Intensity Difference from Average (minIntDiffToAv): A threshold of -2 was established to filter out audio segments with significantly lower intensity than the overall average, focusing the analysis on segments where commentary and background noise levels suggested greater event significance.
- Minimum Voiced/Unvoiced Ratio (minVoicedRatio): With a minimum ratio set at 0.3, this filter ensured that the retained audio segments contained a sufficient amount of voiced sound (e.g., speech) relative to unvoiced sound (e.g., background noise), enhancing the clarity and relevance of the data.
- Minimum Harmonic-to-Noise Ratio (minHnr): This was set at 3 to exclude low-quality audio segments with excessive noise, thereby enhancing the overall quality of the dataset.
4. Findings
After the creation of the dataset and ranking of the team performance, the following ranks: Highlighted xG RankingsTeams were first ranked based on highlighted expected goals (xG), which focuses on significant scoring opportunities. This metric provides a clearer picture of a team’s ability to create high-quality chances. Notably, Atalanta and Lazio, known for their offensive strategies, ranked high in both highlighted xG and overall xG, aligning with their points-based rankings. This suggests these teams effectively capitalized on key moments. However, discrepancies were observed for other teams, indicating either inefficiencies in converting chances or reliance on strong defensive strategies.
Loudest xG Rankings
The analysis was enriched by introducing the loudest xG metric, which measures the intensity of live commentary during significant game moments. This captures the emotional and dramatic aspects of the game. Comparing loudest xG with highlighted xG, points, and overall xG provided a holistic view of team performances. Teams with dynamic playing styles and passionate fanbases ranked higher in loudest xG, emphasizing how crowd and commentator engagement enhance the perceived excitement and importance of a team's performance.
5. Discussion
6. Conclusions
7. References


{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=Areagraph_03_Tavola%20disegno%201.jpg;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=Atlantis_WikiTimeline_Tavola%20disegno%201.jpg;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=Crusade_WikiTimeline-02.jpg;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=Screenshot%202019-07-22%20at%2015.22.51.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=Screenshot%202019-07-22%20at%2016.42.17.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=Screenshot%202019-07-23%20at%2012.25.46.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=Screenshot%202019-07-23%20at%2016.10.01.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=WW2_WikiTimeline-03.jpg;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=cluster%202.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=image-wall-e3b55f6d8e296e95f13bd18fc943dd55.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=pasted%20image%200.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=pasted%20image%202.png;revInfo=1){kind=link}
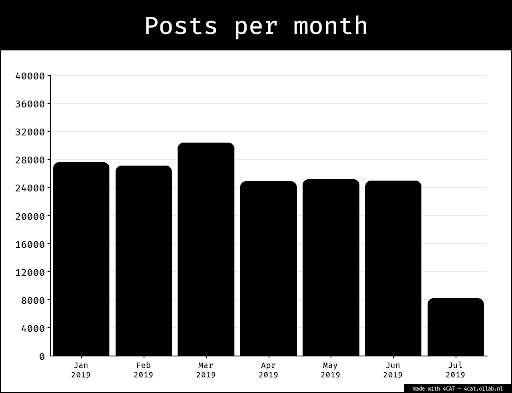{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=unnamed-2.png;revInfo=1){kind=link}
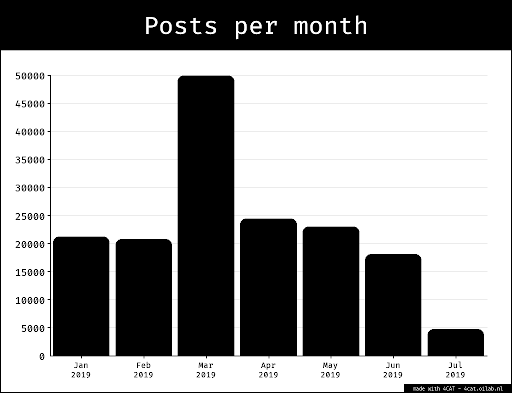{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=unnamed-3.png;revInfo=1){kind=link}
{kind=link}
UsingMulti-ModalAItoMeasuretheEntertainmentValueofaFootballMatch?filename=unnamed-4.png;revInfo=1){kind=link}
Edit | Attach | Print version | History: r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r1 - 12 Aug 2024, KunchiWu
Ideas, requests, problems regarding Foswiki? Send feedback