You are here: Foswiki>Digitalmethods Web>WebHome (22 Nov 2016, RonalMado)Edit Attach
Course | Tools | Projects | About | FAQ
The Link | The Website | The Engine | The Spheres | The Webs | Post-demographics | Networked ContentWelcome to the Digital Methods course, which is a focused section of the more expansive Digital Methods wiki. The Digital Methods course consists of seven units with digital research protocols, specially developed tools, tutorials as well as sample projects. In particular this course is dedicated to how else links, Websites, engines and other digital objects and spaces may be studied, if methods were to follow the medium, as opposed to importing standard methods from the social sciences more generally, including surveys, interviews and observation. Here digital methods are central. Short literature reviews are followed by distinctive digital methods approaches, step-by-step guides and exemplary projects.
Course Overview
Unit 1: The Link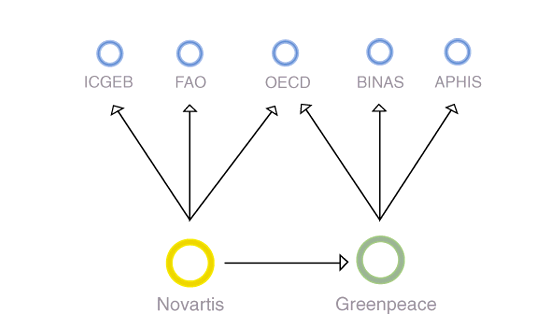 There are at least three dominant approaches to studying hyperlinks, hypertext theory (Landow, 1994), small world and path theory (Watts, 1999), and associational sociology (Park and Thelwall, 2003). To literary theorists of hypertext, sets of hyperlinks form a multitude of distinct pathways through text. The surfer, or clicking text navigator, may be said to author a story by choosing routes (multiple clicks) through the text (Elmer, 2001). Thus the story told through link navigation is of interest. For small world theorists, the links that form paths show distance between actors. Social network analysts use pathway thought, and zoom in on how the ties, uni-directional or bi-directional, position actors (Krebs, 2004) Agen Judi. There is a special vocabulary that has been developed to characterize an actor's position, especially an actor's centrality, within a network. For example, an actor is 'highly between' if there is a high probability that other actors must pass through him to reach each other. To associational sociologists, as least as it's described here, links matter for a different reason. As with social network analysis, the interest is in actor positioning, but not necessarily in terms of distance from one another, or the means by which an actor may be reached through 'networking.' Rather, ties are reputational indicators. Ties, both quantities as well as types, may be said to define actor standing. Additionally, the approach does not assume that the ties between actors are friendly, or otherwise have utility, in the sense of providing empowering pathways, or clues for successful networking.
There are at least three dominant approaches to studying hyperlinks, hypertext theory (Landow, 1994), small world and path theory (Watts, 1999), and associational sociology (Park and Thelwall, 2003). To literary theorists of hypertext, sets of hyperlinks form a multitude of distinct pathways through text. The surfer, or clicking text navigator, may be said to author a story by choosing routes (multiple clicks) through the text (Elmer, 2001). Thus the story told through link navigation is of interest. For small world theorists, the links that form paths show distance between actors. Social network analysts use pathway thought, and zoom in on how the ties, uni-directional or bi-directional, position actors (Krebs, 2004) Agen Judi. There is a special vocabulary that has been developed to characterize an actor's position, especially an actor's centrality, within a network. For example, an actor is 'highly between' if there is a high probability that other actors must pass through him to reach each other. To associational sociologists, as least as it's described here, links matter for a different reason. As with social network analysis, the interest is in actor positioning, but not necessarily in terms of distance from one another, or the means by which an actor may be reached through 'networking.' Rather, ties are reputational indicators. Ties, both quantities as well as types, may be said to define actor standing. Additionally, the approach does not assume that the ties between actors are friendly, or otherwise have utility, in the sense of providing empowering pathways, or clues for successful networking.
Unit 2: The Website
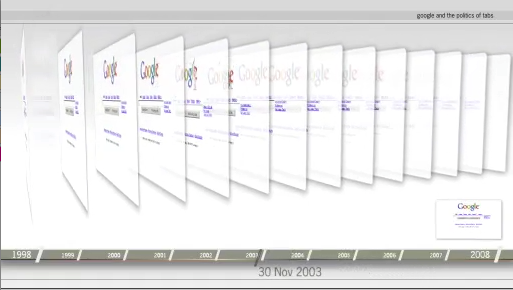
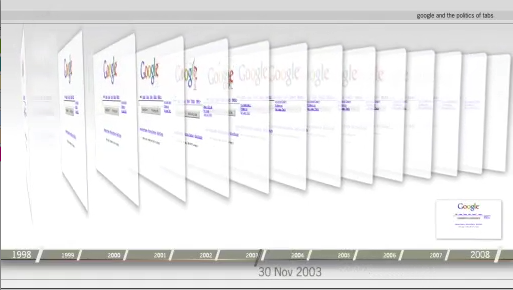 Investigations into Websites have been dominated by user and "eyeball studies," where attempts at a navigation poetics are met with such sobering ideas as "don't make me think" (Dunne, 2000; Krug, 2000). Many of the methods for studying Websites are located 'over the shoulder,' where one observes navigation or the use of a search engine, and later conducts interviews with the subjects. What one may term 'registrational approaches' have found their most popular technique in eye-tracking. Sites load and eyes move to the upper left of the screen. The resulting 'heat maps' provide site redesign cues. For example, Google has moved its services from above the search box (the old tabs) to the top left corner of the page (the new menu). Here the contribution to Website studies is different. The Website is taken to be an archived object, made accessible through the Internet Archive's Wayback Machine. Which types of studies of Websites are enabled and constrained by the Wayback machine? Generally speaking, the Wayback Machine accepts a URL as its input, and outputs the pages of that URL captured from the past. It thereby privileges single-site, or in fact single-page, histories.
Investigations into Websites have been dominated by user and "eyeball studies," where attempts at a navigation poetics are met with such sobering ideas as "don't make me think" (Dunne, 2000; Krug, 2000). Many of the methods for studying Websites are located 'over the shoulder,' where one observes navigation or the use of a search engine, and later conducts interviews with the subjects. What one may term 'registrational approaches' have found their most popular technique in eye-tracking. Sites load and eyes move to the upper left of the screen. The resulting 'heat maps' provide site redesign cues. For example, Google has moved its services from above the search box (the old tabs) to the top left corner of the page (the new menu). Here the contribution to Website studies is different. The Website is taken to be an archived object, made accessible through the Internet Archive's Wayback Machine. Which types of studies of Websites are enabled and constrained by the Wayback machine? Generally speaking, the Wayback Machine accepts a URL as its input, and outputs the pages of that URL captured from the past. It thereby privileges single-site, or in fact single-page, histories.
Unit 3: The Engine
 On the Web, sources compete to offer the user information. The results of this competition are seen, for instance, in the 'drama' surrounding search engine returns. A Website, having achieved a high ranking for a particular query, slowly slips from the top, and eventually out of the top ten results. What does such a slippage say about the Website, and the organization behind it? (See the 9/11 case study). What does the drop in ranking say about the site's standing in the competition to provide the information? The focus here is on how to research particular sources' prominence in search engine results. For example, listening to the radio and watching TV, climate change skeptics appear 'close to the top of the news'? The question is, how close are they to the top of the Web? The answer to this and similar 'source distance' inquiries goes a way towards answering questions about the quality of old versus new media.
On the Web, sources compete to offer the user information. The results of this competition are seen, for instance, in the 'drama' surrounding search engine returns. A Website, having achieved a high ranking for a particular query, slowly slips from the top, and eventually out of the top ten results. What does such a slippage say about the Website, and the organization behind it? (See the 9/11 case study). What does the drop in ranking say about the site's standing in the competition to provide the information? The focus here is on how to research particular sources' prominence in search engine results. For example, listening to the radio and watching TV, climate change skeptics appear 'close to the top of the news'? The question is, how close are they to the top of the Web? The answer to this and similar 'source distance' inquiries goes a way towards answering questions about the quality of old versus new media.
Unit 4: The Spheres
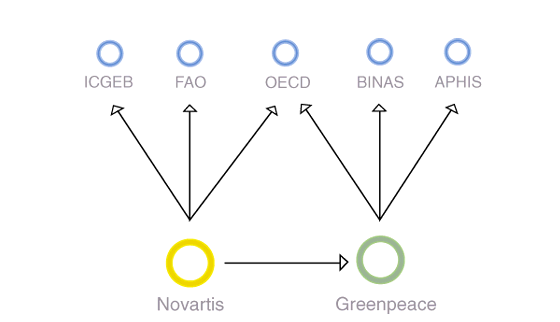
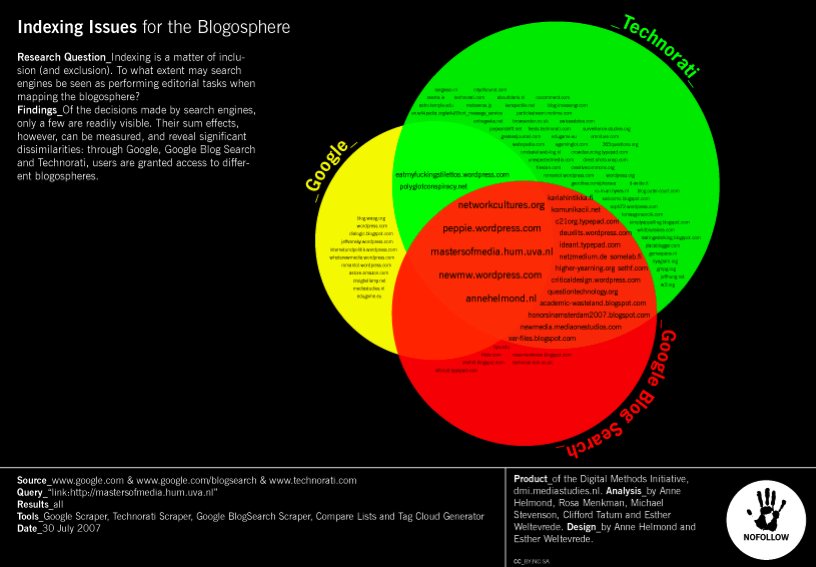
 Thinking of the Web in terms of spheres refers both to the name of one of the most well-known, the blogosphere, as well as scholarship that seeks to define another, the Web sphere (Foot and Schneider, 2002; Schneider and Foot, 2002). The sphere in blogosphere refers in spirit to the public sphere; it also may be thought of in terms of the geometrical form, where all points on the surface are the same distance from the center or core. One could think about such an equidistance measure as an egalitarian ideal, where every blog, or even every source of information, is knowable by the core, and vice versa. On the Web, it has been found, certain sources are central. They receive the vast majority of links as well as hits. Following such principles as the rich get richer (aka Matthew effects and power law distributions), the sites receiving attention tend to garner only more, however. The distance between the center and other nodes may tend only to grow, with the ideal of a sphere being a fiction, however much a useful one. Spherical analysis is a digital method for measuring and learning from the distance between sources on the Web.
Thinking of the Web in terms of spheres refers both to the name of one of the most well-known, the blogosphere, as well as scholarship that seeks to define another, the Web sphere (Foot and Schneider, 2002; Schneider and Foot, 2002). The sphere in blogosphere refers in spirit to the public sphere; it also may be thought of in terms of the geometrical form, where all points on the surface are the same distance from the center or core. One could think about such an equidistance measure as an egalitarian ideal, where every blog, or even every source of information, is knowable by the core, and vice versa. On the Web, it has been found, certain sources are central. They receive the vast majority of links as well as hits. Following such principles as the rich get richer (aka Matthew effects and power law distributions), the sites receiving attention tend to garner only more, however. The distance between the center and other nodes may tend only to grow, with the ideal of a sphere being a fiction, however much a useful one. Spherical analysis is a digital method for measuring and learning from the distance between sources on the Web.
Unit 5: The Webs
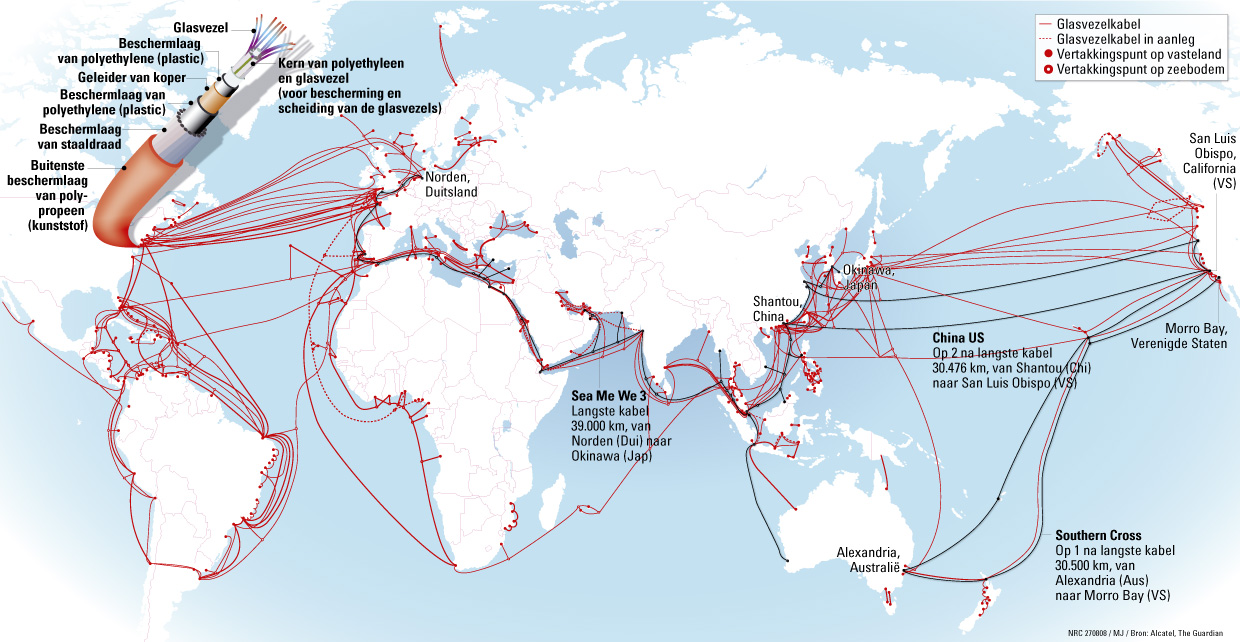
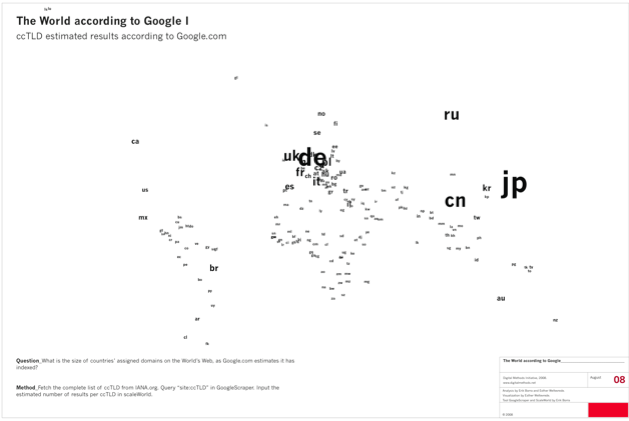
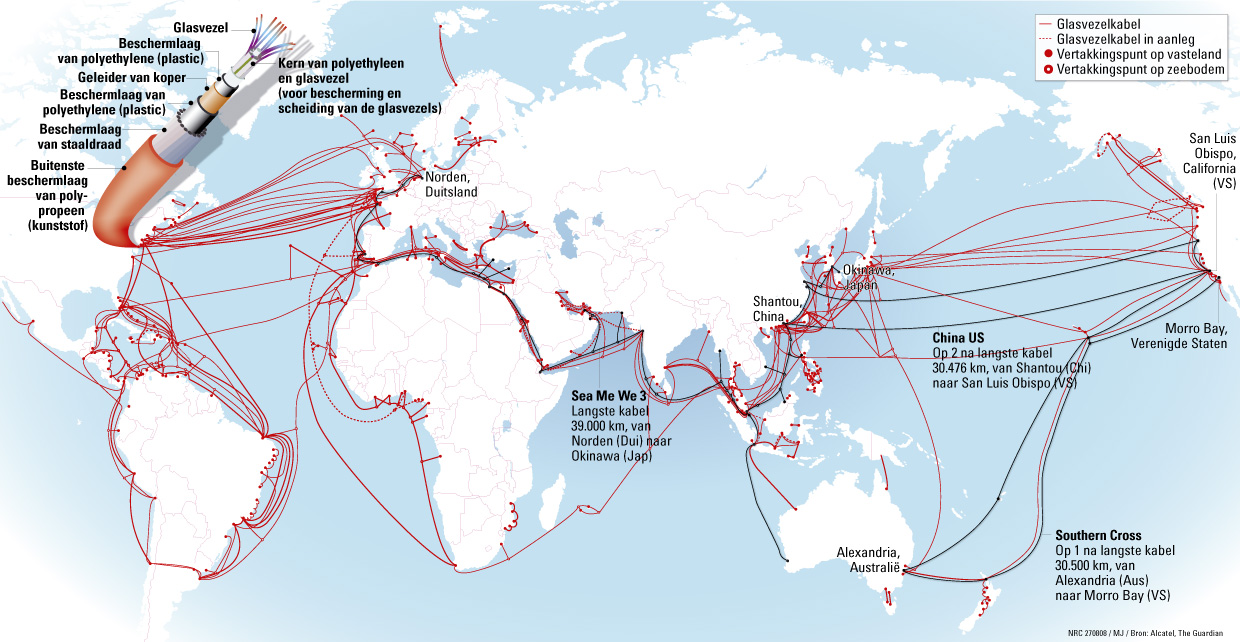 Thinking geographically with the Web may seem unusual at first. Geography is not thought to be arranged in the infrastructure of the Internet. An 'Internet geography' would not be in tune with the popular ideas of 'cyberspace' more generally (Chun, 2006). Indeed, the remarkable, "in-built" protocols and principles, such as packet switching and the end-to-end principle, initially informed ideas of a 'cyberspace,' a space or realm free from geographical and physical constraints. The architecture also supposedly made for a space untethered from the nation-states, and their divergent ways of treating flows of information. One recalls the famous quotation attributed to John Gilmore, "The Internet treats censorship as a malfunction, and routes around it" (Boyle, 1997). Moreover, the Internet's technical indifference to the geographical location of its users and their content paralleled ideas not only of place-less-ness but also of equality, freedom and identity play. Cyberspace has since been grounded. Looking back at the original locations of the 13 root servers as well as the distributions of traffic flows by country, one could argue that the Internet has had specific geographies built into its infrastructure all along. However, it was the advent of widespread usage of geoIP, or IP address location technology, that have made 'the Webs' increasingly national.
Thinking geographically with the Web may seem unusual at first. Geography is not thought to be arranged in the infrastructure of the Internet. An 'Internet geography' would not be in tune with the popular ideas of 'cyberspace' more generally (Chun, 2006). Indeed, the remarkable, "in-built" protocols and principles, such as packet switching and the end-to-end principle, initially informed ideas of a 'cyberspace,' a space or realm free from geographical and physical constraints. The architecture also supposedly made for a space untethered from the nation-states, and their divergent ways of treating flows of information. One recalls the famous quotation attributed to John Gilmore, "The Internet treats censorship as a malfunction, and routes around it" (Boyle, 1997). Moreover, the Internet's technical indifference to the geographical location of its users and their content paralleled ideas not only of place-less-ness but also of equality, freedom and identity play. Cyberspace has since been grounded. Looking back at the original locations of the 13 root servers as well as the distributions of traffic flows by country, one could argue that the Internet has had specific geographies built into its infrastructure all along. However, it was the advent of widespread usage of geoIP, or IP address location technology, that have made 'the Webs' increasingly national.
Unit 6: Social Networking Sites and Post-demographics
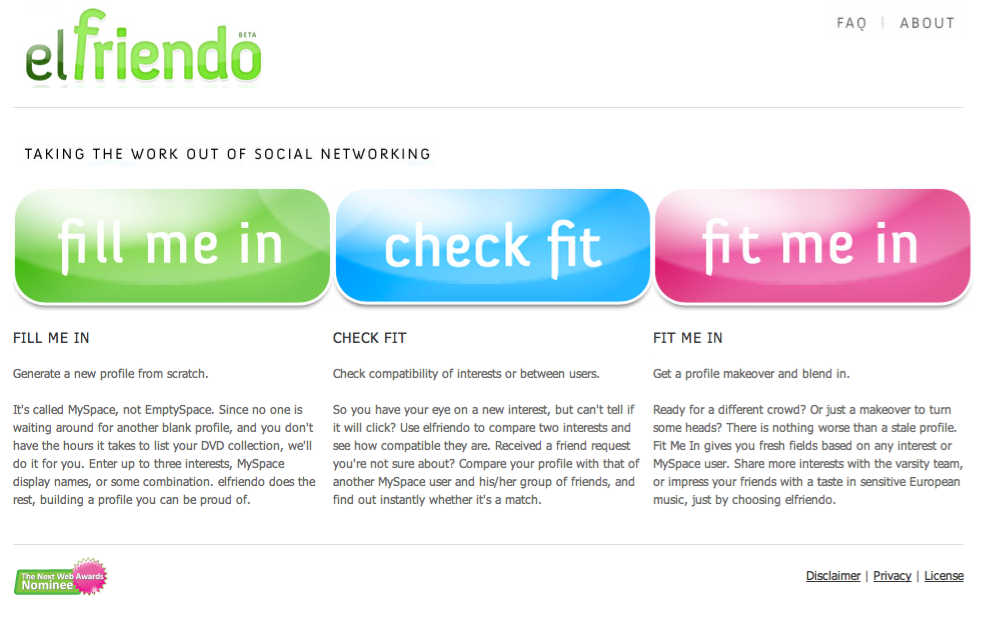
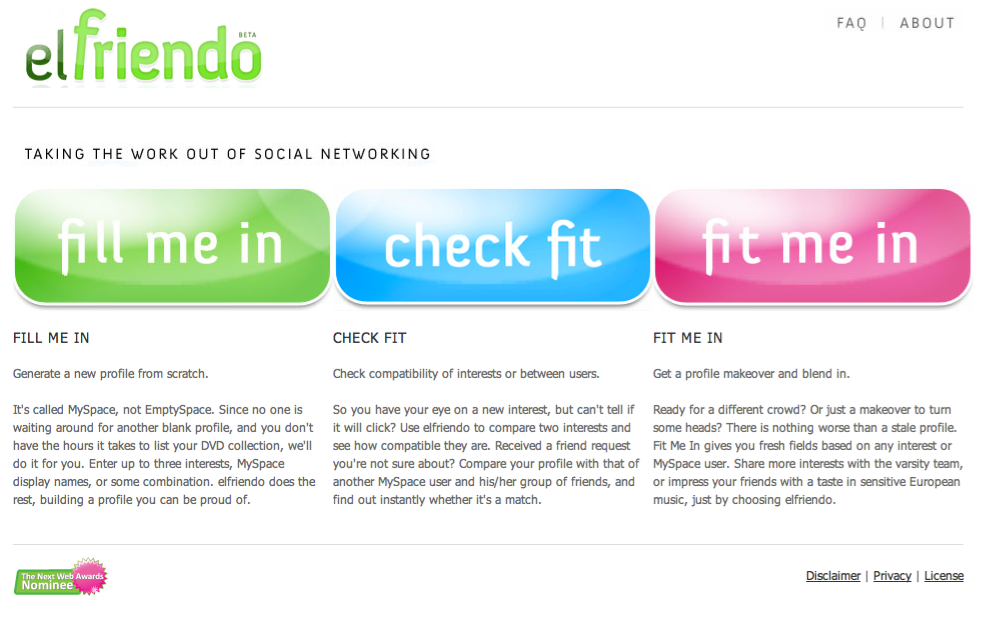 Leading research into social networking sites considers such issues as presenting and managing oneself online, the different 'classes' of users in MySpace and Facebook and the distinction between real-life friends and 'friended' friends. Another set of work, often non-academic, concerns how to make use of the copious amounts of personal data placed online. We wish to dub this work 'post-demographics.' Post-demographics could be thought of as the study of the personal data in social networking platforms, and, in particular, how profiling is, or may be, performed, including the consequences of such work. With the 'post' prefix to demographics, the idea is to stand in contrast to how the study of demographics organizes groups, markets and voters in society. The term post-demographics also invites new methods for the study of social networks, where of interest are not the traditional demographics of race, ethnicity, age, income, educational level or derivations thereof such as class, but rather tastes and other infomation supplied to make and maintain an online profile. Which derivations may be made from profile information, apart from market niches? Post-demographics is preferred over post-demography (a more formal term), as it recognizes popular usage of the notion of a demographic referring to a segment or niche that may be targetted. Crucially the notion attempts to capture the difference between how 'demographers' and, say, 'profilers' collect as well as use data. Demographers would normally analyze official records (births, deaths, marriages) and survey populations, with census-taking being the most well-known of such undertakings. Profilers, prediksi bola, contrariwise, capture information from users of online platforms.
Leading research into social networking sites considers such issues as presenting and managing oneself online, the different 'classes' of users in MySpace and Facebook and the distinction between real-life friends and 'friended' friends. Another set of work, often non-academic, concerns how to make use of the copious amounts of personal data placed online. We wish to dub this work 'post-demographics.' Post-demographics could be thought of as the study of the personal data in social networking platforms, and, in particular, how profiling is, or may be, performed, including the consequences of such work. With the 'post' prefix to demographics, the idea is to stand in contrast to how the study of demographics organizes groups, markets and voters in society. The term post-demographics also invites new methods for the study of social networks, where of interest are not the traditional demographics of race, ethnicity, age, income, educational level or derivations thereof such as class, but rather tastes and other infomation supplied to make and maintain an online profile. Which derivations may be made from profile information, apart from market niches? Post-demographics is preferred over post-demography (a more formal term), as it recognizes popular usage of the notion of a demographic referring to a segment or niche that may be targetted. Crucially the notion attempts to capture the difference between how 'demographers' and, say, 'profilers' collect as well as use data. Demographers would normally analyze official records (births, deaths, marriages) and survey populations, with census-taking being the most well-known of such undertakings. Profilers, prediksi bola, contrariwise, capture information from users of online platforms.
Unit 7: Wikipedia and Networked Content
 To date the approaches to the study of Wikipedia have followed from certain qualities of the online encyclopedia, all of which appear counter-intuitive at first glance. One example is that Wikipedia is authored by "amateurs," yet is surprisingly encyclopedia-like, not only in form but in accuracy (Giles, 2005). The major debate concerning the quality of Wikipedia vis-a-vis Encyclopedia Britannica is also interesting from another angle. How do the mechanisms built into Wikipedia's editing model (such as dispute resolution) ensure quality? Or, perhaps quality is the outcome of Wikipedia's particular type of "networked content," i.e., a term that refers to content 'held together' (dynamically) by human authors and non-human tenders, including bots and alert software. One could argue that the bots keep not just the vandals, but also the experimenters, at bay, those researchers as well as Wikipedia nay-sayers making changes to a Wikipedia entry, or creating a new fictional one, and subsequently waiting for something to happen (Chesney, 2006; Read, 2006; Magnus, 2008). Another example of a counter-intuitive aspect is that the editors, Wikipedians, are unpaid yet committed and highly vigilant. Do particular 'open content' projects have an equivalent community spirit, and non-monetary reward system, to that of open source projects? (See UNU-MERIT's Wikipedia Study.) Related questions concern the editors themselves. Research has been undertaken in reaction to findings that there is only a tiny ratio of editors to users in Web 2.0 platforms. This is otherwise known as the myth of user-generated content (Swartz, 2006). Wikipedia co-founder, Jimbo Wales, has often remarked that the dedicated community is relatively small, at just over 500 members. Beyond the small community there are also editors who do not register with the system. The anonymous editors and the edits they make are the subjects of the Wikiscanner tool, developed by Virgil Griffith studying at the California Institute of Technology. Anonymous editors may be 'outed,' leading to scandals, as collected by Griffith himself. Among the ways proposed to study top rated essay writing service the use of Wikipedia's data, here the Wikiscanner is repurposed for comparative entry editing analysis. For example, what does a country's edits, or an organization's, say about its knowledge? Put differently, what sorts of accounts may be made from "the places of edits"?
by Agen Sbobet Terpercaya
To date the approaches to the study of Wikipedia have followed from certain qualities of the online encyclopedia, all of which appear counter-intuitive at first glance. One example is that Wikipedia is authored by "amateurs," yet is surprisingly encyclopedia-like, not only in form but in accuracy (Giles, 2005). The major debate concerning the quality of Wikipedia vis-a-vis Encyclopedia Britannica is also interesting from another angle. How do the mechanisms built into Wikipedia's editing model (such as dispute resolution) ensure quality? Or, perhaps quality is the outcome of Wikipedia's particular type of "networked content," i.e., a term that refers to content 'held together' (dynamically) by human authors and non-human tenders, including bots and alert software. One could argue that the bots keep not just the vandals, but also the experimenters, at bay, those researchers as well as Wikipedia nay-sayers making changes to a Wikipedia entry, or creating a new fictional one, and subsequently waiting for something to happen (Chesney, 2006; Read, 2006; Magnus, 2008). Another example of a counter-intuitive aspect is that the editors, Wikipedians, are unpaid yet committed and highly vigilant. Do particular 'open content' projects have an equivalent community spirit, and non-monetary reward system, to that of open source projects? (See UNU-MERIT's Wikipedia Study.) Related questions concern the editors themselves. Research has been undertaken in reaction to findings that there is only a tiny ratio of editors to users in Web 2.0 platforms. This is otherwise known as the myth of user-generated content (Swartz, 2006). Wikipedia co-founder, Jimbo Wales, has often remarked that the dedicated community is relatively small, at just over 500 members. Beyond the small community there are also editors who do not register with the system. The anonymous editors and the edits they make are the subjects of the Wikiscanner tool, developed by Virgil Griffith studying at the California Institute of Technology. Anonymous editors may be 'outed,' leading to scandals, as collected by Griffith himself. Among the ways proposed to study top rated essay writing service the use of Wikipedia's data, here the Wikiscanner is repurposed for comparative entry editing analysis. For example, what does a country's edits, or an organization's, say about its knowledge? Put differently, what sorts of accounts may be made from "the places of edits"?
by Agen Sbobet Terpercaya 

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
17pbcloud.jpg | manage | 392 K | 03 Oct 2008 - 14:16 | Main.issuecrawler14 | polar bear cloud |
| |
4_aspirational_linking.png | manage | 20 K | 03 Oct 2008 - 12:52 | Main.issuecrawler14 | aspirational linking |
| |
cross-spherical.png | manage | 138 K | 03 Oct 2008 - 13:11 | Main.issuecrawler14 | cross-spherical analysis |
| |
elfriendo.png | manage | 274 K | 03 Oct 2008 - 13:24 | Main.issuecrawler14 | elfriendo |
| |
glasvegels.jpg | manage | 314 K | 03 Oct 2008 - 14:13 | Main.issuecrawler14 | glasvezels |
| |
google_movie_image.png | manage | 88 K | 03 Oct 2008 - 12:57 | Main.issuecrawler14 | google movie |
| |
skeptics.png | manage | 120 K | 03 Oct 2008 - 13:03 | Main.issuecrawler14 | skeptics |
| |
wikibots.png | manage | 134 K | 03 Oct 2008 - 13:33 | Main.issuecrawler14 | wikipedia bot activity |
| |
worldmap.png | manage | 42 K | 03 Oct 2008 - 13:21 | Main.issuecrawler14 | ccTLD worldmap |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r54 < r53 < r52 < r51 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r54 - 22 Nov 2016, RonalMado
Ideas, requests, problems regarding Foswiki? Send feedback