Robots.txt Discovery
Display a site's robot exclusion policy.
Instructions
Input URLs or text into the harvester and choose depth of search (example.com/depth1/depth2/depth3).
In the box you can enter URLs. After clicking submit all unique hosts of the URLs will be checked for robots.txt (e.g. http://www.bla.com/bla/bla/index.html will be checked for http://www.bla.com/robots.txt) and each unique URL will be checked for <meta name=
Sample project
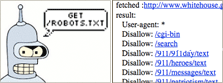
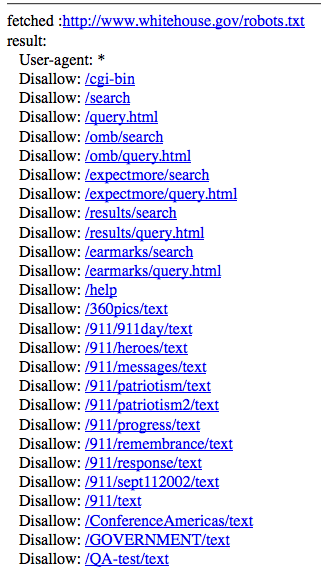
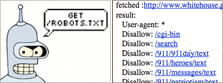
Discover robots.txt exclusion policy for http://www.whitehouse.gov. Input URL to produce a list of robot-excluded content:
<img alt=
Protocols devised by the DMI This page is being replaced gradually by our new research protocols and methods page. Hyperlink Analysis * Perfom an issue craw...
Summer School 2007
Digital Methods Summer School 2007: New Objects of Study 2010 2009 2008 2007 How does one do research online? What are the new objects of study, and how do ...
Test Home
DMI Tools Digital Methods Project Overview FAQ Tag Cloud Introduction The Digital Methods Initiative is a contribution to doing research into the "nati...
Other projects using this tool
Dmi ProtocolsProtocols devised by the DMI This page is being replaced gradually by our new research protocols and methods page. Hyperlink Analysis * Perfom an issue craw...
Summer School 2007
Digital Methods Summer School 2007: New Objects of Study 2010 2009 2008 2007 How does one do research online? What are the new objects of study, and how do ...
Test Home
DMI Tools Digital Methods Project Overview FAQ Tag Cloud Introduction The Digital Methods Initiative is a contribution to doing research into the "nati...


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
white_house_robots.png | manage | 55 K | 12 Dec 2008 - 14:51 | MichaelStevenson | White House Robots |
| |
robotstxt.png | manage | 9 K | 12 Dec 2008 - 14:19 | AnneHelmond | Tool icon |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback